 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAIFAI: Human-AI Collaboration for Mental Face Reconstruction
Dec 09, 2024We present HAIFAI - a novel collaborative human-AI system to tackle the challenging task of reconstructing a visual representation of a face that exists only in a person's mind. Users iteratively rank images presented by the AI system based on their resemblance to a mental image. These rankings, in turn, allow the system to extract relevant image features, fuse them into a unified feature vector, and use a generative model to reconstruct the mental image. We also propose an extension called HAIFAI-X that allows users to manually refine and further improve the reconstruction using an easy-to-use slider interface. To avoid the need for tedious human data collection for model training, we introduce a computational user model of human ranking behaviour. For this, we collected a small face ranking dataset through an online crowd-sourcing study containing data from 275 participants. We evaluate HAIFAI and HAIFAI-X in a 12-participant user study and show that HAIFAI outperforms the previous state of the art regarding reconstruction quality, usability, perceived workload, and reconstruction speed. HAIFAI-X achieves even better reconstruction quality at the cost of reduced usability, perceived workload, and increased reconstruction time. We further validate the reconstructions in a subsequent face ranking study with 18 participants and show that HAIFAI-X achieves a new state-of-the-art identification rate of 60.6%. These findings represent a significant advancement towards developing new collaborative intelligent systems capable of reliably and effortlessly reconstructing a user's mental image.
SeFFeC: Semantic Facial Feature Control for Fine-grained Face Editing
Mar 26, 2024



We propose Semantic Facial Feature Control (SeFFeC) - a novel method for fine-grained face shape editing. Our method enables the manipulation of human-understandable, semantic face features, such as nose length or mouth width, which are defined by different groups of facial landmarks. In contrast to existing methods, the use of facial landmarks enables precise measurement of the facial features, which then enables training SeFFeC without any manually annotated labels. SeFFeC consists of a transformer-based encoder network that takes a latent vector of a pre-trained generative model and a facial feature embedding as input, and learns to modify the latent vector to perform the desired face edit operation. To ensure that the desired feature measurement is changed towards the target value without altering uncorrelated features, we introduced a novel semantic face feature loss. Qualitative and quantitative results show that SeFFeC enables precise and fine-grained control of 23 facial features, some of which could not previously be controlled by other methods, without requiring manual annotations. Unlike existing methods, SeFFeC also provides deterministic control over the exact values of the facial features and more localised and disentangled face edits.
Learning User Embeddings from Human Gaze for Personalised Saliency Prediction
Mar 26, 2024



Reusable embeddings of user behaviour have shown significant performance improvements for the personalised saliency prediction task. However, prior works require explicit user characteristics and preferences as input, which are often difficult to obtain. We present a novel method to extract user embeddings from pairs of natural images and corresponding saliency maps generated from a small amount of user-specific eye tracking data. At the core of our method is a Siamese convolutional neural encoder that learns the user embeddings by contrasting the image and personal saliency map pairs of different users. Evaluations on two public saliency datasets show that the generated embeddings have high discriminative power, are effective at refining universal saliency maps to the individual users, and generalise well across users and images. Finally, based on our model's ability to encode individual user characteristics, our work points towards other applications that can benefit from reusable embeddings of gaze behaviour.
Int-HRL: Towards Intention-based Hierarchical Reinforcement Learning
Jun 20, 2023While deep reinforcement learning (RL) agents outperform humans on an increasing number of tasks, training them requires data equivalent to decades of human gameplay. Recent hierarchical RL methods have increased sample efficiency by incorporating information inherent to the structure of the decision problem but at the cost of having to discover or use human-annotated sub-goals that guide the learning process. We show that intentions of human players, i.e. the precursor of goal-oriented decisions, can be robustly predicted from eye gaze even for the long-horizon sparse rewards task of Montezuma's Revenge - one of the most challenging RL tasks in the Atari2600 game suite. We propose Int-HRL: Hierarchical RL with intention-based sub-goals that are inferred from human eye gaze. Our novel sub-goal extraction pipeline is fully automatic and replaces the need for manual sub-goal annotation by human experts. Our evaluations show that replacing hand-crafted sub-goals with automatically extracted intentions leads to a HRL agent that is significantly more sample efficient than previous methods.
VQA-MHUG: A Gaze Dataset to Study Multimodal Neural Attention in Visual Question Answering
Sep 27, 2021

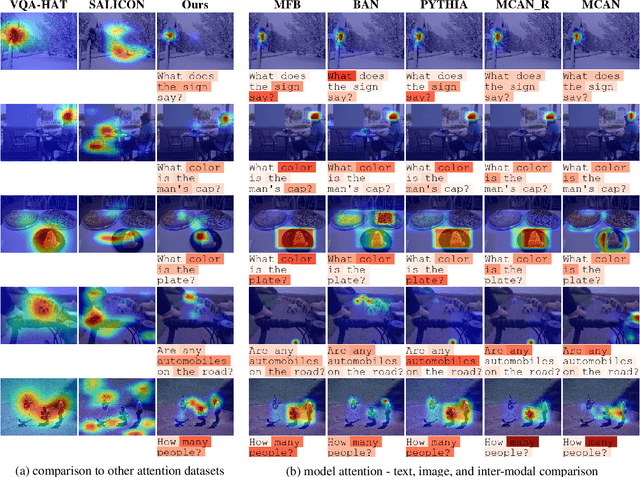
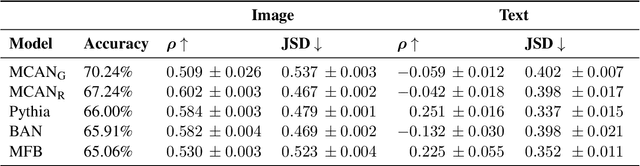
We present VQA-MHUG - a novel 49-participant dataset of multimodal human gaze on both images and questions during visual question answering (VQA) collected using a high-speed eye tracker. We use our dataset to analyze the similarity between human and neural attentive strategies learned by five state-of-the-art VQA models: Modular Co-Attention Network (MCAN) with either grid or region features, Pythia, Bilinear Attention Network (BAN), and the Multimodal Factorized Bilinear Pooling Network (MFB). While prior work has focused on studying the image modality, our analyses show - for the first time - that for all models, higher correlation with human attention on text is a significant predictor of VQA performance. This finding points at a potential for improving VQA performance and, at the same time, calls for further research on neural text attention mechanisms and their integration into architectures for vision and language tasks, including but potentially also beyond VQA.
Neural Photofit: Gaze-based Mental Image Reconstruction
Aug 17, 2021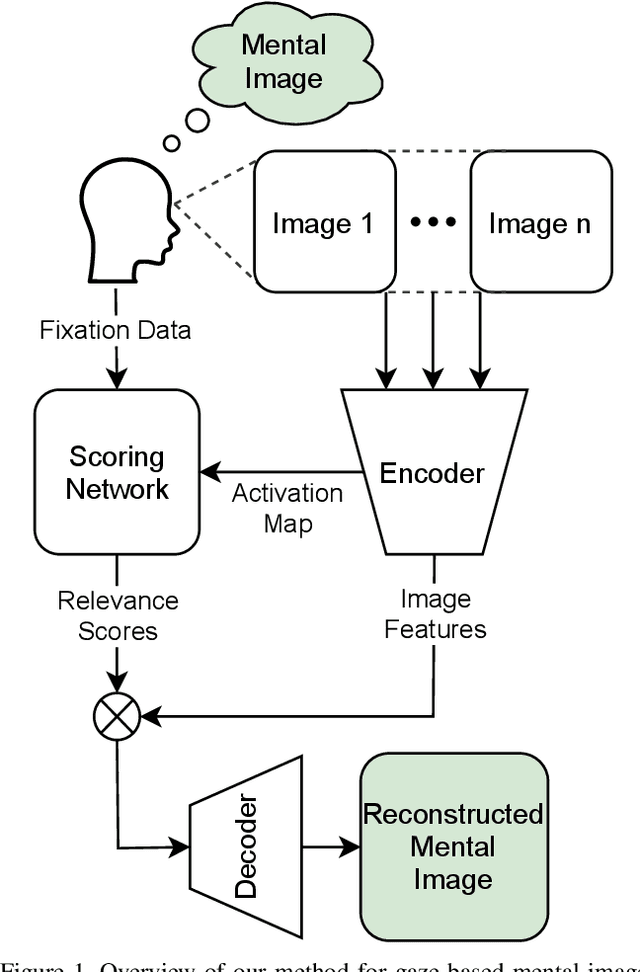
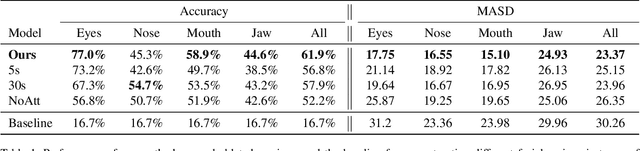

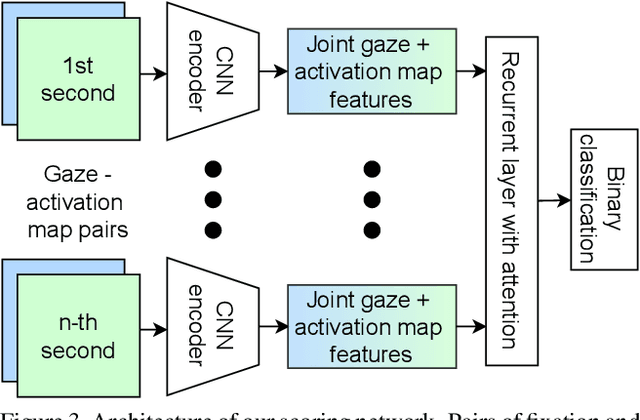
We propose a novel method that leverages human fixations to visually decode the image a person has in mind into a photofit (facial composite). Our method combines three neural networks: An encoder, a scoring network, and a decoder. The encoder extracts image features and predicts a neural activation map for each face looked at by a human observer. A neural scoring network compares the human and neural attention and predicts a relevance score for each extracted image feature. Finally, image features are aggregated into a single feature vector as a linear combination of all features weighted by relevance which a decoder decodes into the final photofit. We train the neural scoring network on a novel dataset containing gaze data of 19 participants looking at collages of synthetic faces. We show that our method significantly outperforms a mean baseline predictor and report on a human study that shows that we can decode photofits that are visually plausible and close to the observer's mental image.
An Empirical Analysis of the Role of Amplifiers, Downtoners, and Negations in Emotion Classification in Microblogs
Oct 02, 2018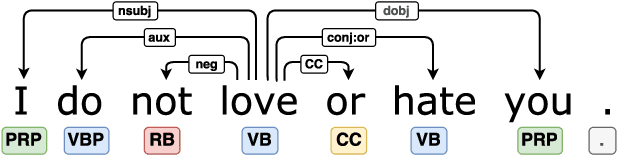
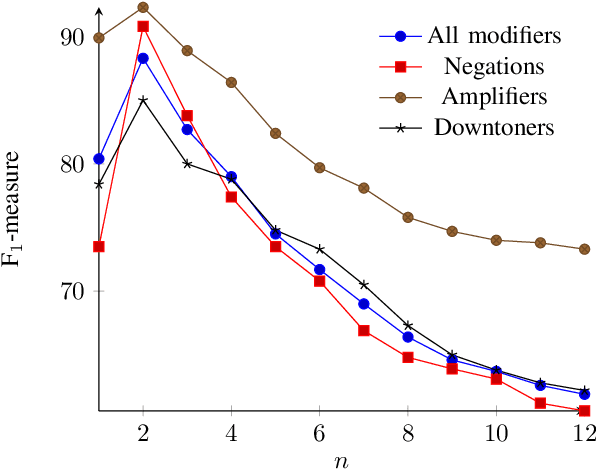
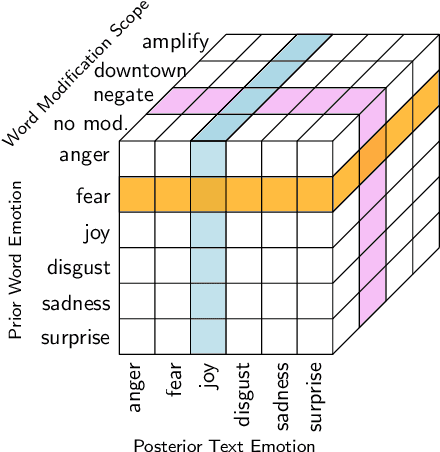
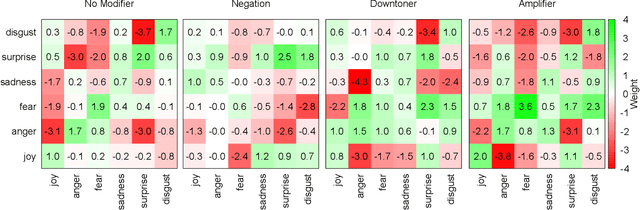
The effect of amplifiers, downtoners, and negations has been studied in general and particularly in the context of sentiment analysis. However, there is only limited work which aims at transferring the results and methods to discrete classes of emotions, e. g., joy, anger, fear, sadness, surprise, and disgust. For instance, it is not straight-forward to interpret which emotion the phrase "not happy" expresses. With this paper, we aim at obtaining a better understanding of such modifiers in the context of emotion-bearing words and their impact on document-level emotion classification, namely, microposts on Twitter. We select an appropriate scope detection method for modifiers of emotion words, incorporate it in a document-level emotion classification model as additional bag of words and show that this approach improves the performance of emotion classification. In addition, we build a term weighting approach based on the different modifiers into a lexical model for the analysis of the semantics of modifiers and their impact on emotion meaning. We show that amplifiers separate emotions expressed with an emotion- bearing word more clearly from other secondary connotations. Downtoners have the opposite effect. In addition, we discuss the meaning of negations of emotion-bearing words. For instance we show empirically that "not happy" is closer to sadness than to anger and that fear-expressing words in the scope of downtoners often express surprise.