 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Understandable Architectonic Gestures for Robotic Furniture through Co-Design Improvisation
Jan 03, 2025

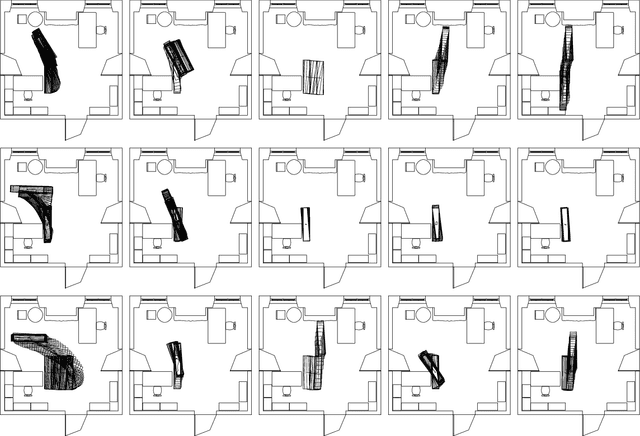

The vision of adaptive architecture proposes that robotic technologies could enable interior spaces to physically transform in a bidirectional interaction with occupants. Yet, it is still unknown how this interaction could unfold in an understandable way. Inspired by HRI studies where robotic furniture gestured intents to occupants by deliberately positioning or moving in space, we hypothesise that adaptive architecture could also convey intents through gestures performed by a mobile robotic partition. To explore this design space, we invited 15 multidisciplinary experts to join co-design improvisation sessions, where they manually manoeuvred a deactivated robotic partition to design gestures conveying six architectural intents that varied in purpose and urgency. Using a gesture elicitation method alongside motion-tracking data, a Laban-based questionnaire, and thematic analysis, we identified 20 unique gestural strategies. Through categorisation, we introduced architectonic gestures as a novel strategy for robotic furniture to convey intent by indexically leveraging its spatial impact, complementing the established deictic and emblematic gestures. Our study thus represents an exploratory step toward making the autonomous gestures of adaptive architecture more legible. By understanding how robotic gestures are interpreted based not only on their motion but also on their spatial impact, we contribute to bridging HRI with Human-Building Interaction research.
An Approach to Elicit Human-Understandable Robot Expressions to Support Human-Robot Interaction
Oct 01, 2024Understanding the intentions of robots is essential for natural and seamless human-robot collaboration. Ensuring that robots have means for non-verbal communication is a basis for intuitive and implicit interaction. For this, we contribute an approach to elicit and design human-understandable robot expressions. We outline the approach in the context of non-humanoid robots. We paired human mimicking and enactment with research from gesture elicitation in two phases: first, to elicit expressions, and second, to ensure they are understandable. We present an example application through two studies (N=16 \& N=260) of our approach to elicit expressions for a simple 6-DoF robotic arm. We show that it enabled us to design robot expressions that signal curiosity and interest in getting attention. Our main contribution is an approach to generate and validate understandable expressions for robots, enabling more natural human-robot interaction.
Understanding the Uncertainty Loop of Human-Robot Interaction
Mar 14, 2023Recently the field of Human-Robot Interaction gained popularity, due to the wide range of possibilities of how robots can support humans during daily tasks. One form of supportive robots are socially assistive robots which are specifically built for communicating with humans, e.g., as service robots or personal companions. As they understand humans through artificial intelligence, these robots will at some point make wrong assumptions about the humans' current state and give an unexpected response. In human-human conversations, unexpected responses happen frequently. However, it is currently unclear how such robots should act if they understand that the human did not expect their response, or even showing the uncertainty of their response in the first place. For this, we explore the different forms of potential uncertainties during human-robot conversations and how humanoids can, through verbal and non-verbal cues, communicate these uncertainties.
The Impact of Expertise in the Loop for Exploring Machine Rationality
Feb 11, 2023Human-in-the-loop optimization utilizes human expertise to guide machine optimizers iteratively and search for an optimal solution in a solution space. While prior empirical studies mainly investigated novices, we analyzed the impact of the levels of expertise on the outcome quality and corresponding subjective satisfaction. We conducted a study (N=60) in text, photo, and 3D mesh optimization contexts. We found that novices can achieve an expert level of quality performance, but participants with higher expertise led to more optimization iteration with more explicit preference while keeping satisfaction low. In contrast, novices were more easily satisfied and terminated faster. Therefore, we identified that experts seek more diverse outcomes while the machine reaches optimal results, and the observed behavior can be used as a performance indicator for human-in-the-loop system designers to improve underlying models. We inform future research to be cautious about the impact of user expertise when designing human-in-the-loop systems.
Investigating Labeler Bias in Face Annotation for Machine Learning
Jan 24, 2023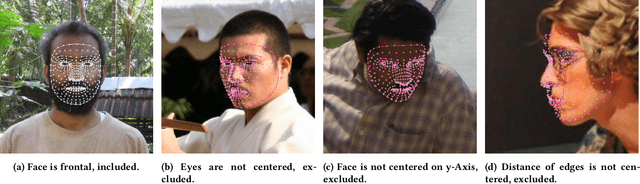



In a world increasingly reliant on artificial intelligence, it is more important than ever to consider the ethical implications of artificial intelligence on humanity. One key under-explored challenge is labeler bias, which can create inherently biased datasets for training and subsequently lead to inaccurate or unfair decisions in healthcare, employment, education, and law enforcement. Hence, we conducted a study to investigate and measure the existence of labeler bias using images of people from different ethnicities and sexes in a labeling task. Our results show that participants possess stereotypes that influence their decision-making process and that labeler demographics impact assigned labels. We also discuss how labeler bias influences datasets and, subsequently, the models trained on them. Overall, a high degree of transparency must be maintained throughout the entire artificial intelligence training process to identify and correct biases in the data as early as possible.
Neural Photofit: Gaze-based Mental Image Reconstruction
Aug 17, 2021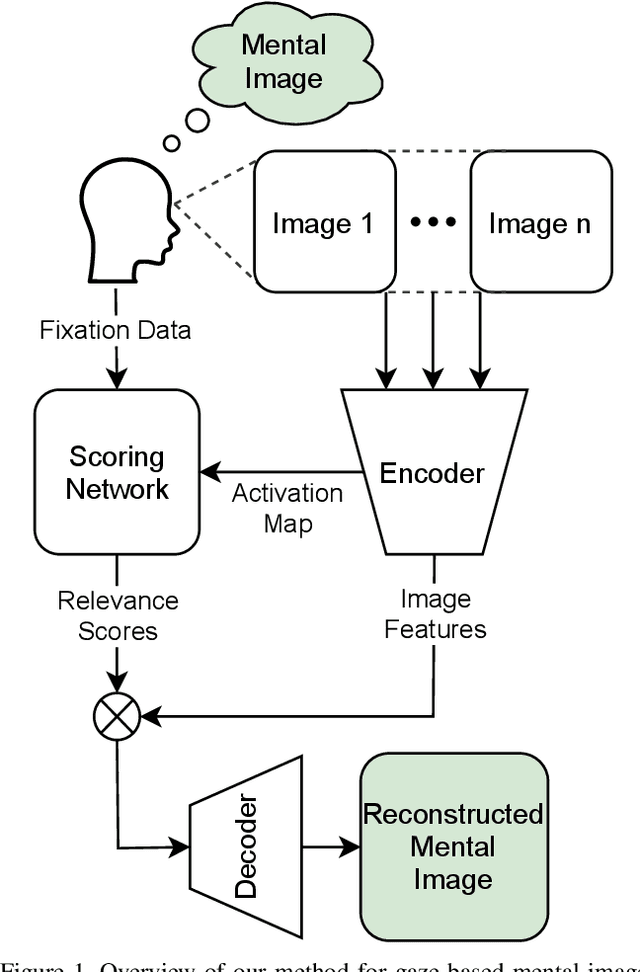
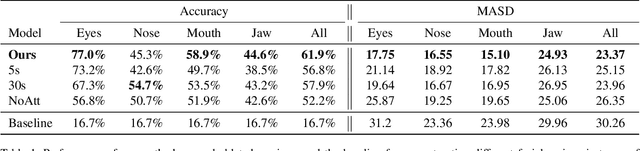

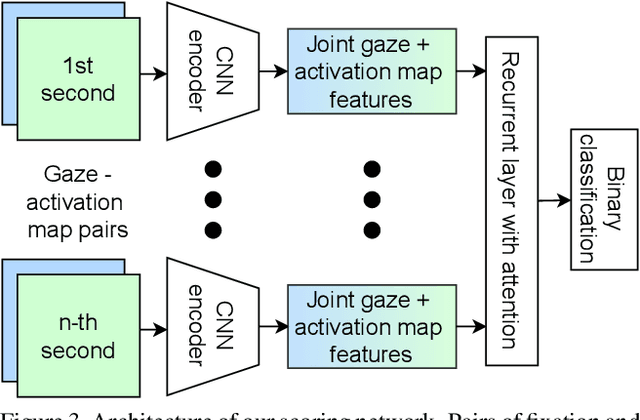
We propose a novel method that leverages human fixations to visually decode the image a person has in mind into a photofit (facial composite). Our method combines three neural networks: An encoder, a scoring network, and a decoder. The encoder extracts image features and predicts a neural activation map for each face looked at by a human observer. A neural scoring network compares the human and neural attention and predicts a relevance score for each extracted image feature. Finally, image features are aggregated into a single feature vector as a linear combination of all features weighted by relevance which a decoder decodes into the final photofit. We train the neural scoring network on a novel dataset containing gaze data of 19 participants looking at collages of synthetic faces. We show that our method significantly outperforms a mean baseline predictor and report on a human study that shows that we can decode photofits that are visually plausible and close to the observer's mental image.