 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Intent: A Multimodal Framework for Human-Robot Cooperation in Industrial Workspaces
Jun 18, 2025As robots enter collaborative workspaces, ensuring mutual understanding between human workers and robotic systems becomes a prerequisite for trust, safety, and efficiency. In this position paper, we draw on the cooperation scenario of the AIMotive project in which a human and a cobot jointly perform assembly tasks to argue for a structured approach to intent communication. Building on the Situation Awareness-based Agent Transparency (SAT) framework and the notion of task abstraction levels, we propose a multidimensional design space that maps intent content (SAT1, SAT3), planning horizon (operational to strategic), and modality (visual, auditory, haptic). We illustrate how this space can guide the design of multimodal communication strategies tailored to dynamic collaborative work contexts. With this paper, we lay the conceptual foundation for a future design toolkit aimed at supporting transparent human-robot interaction in the workplace. We highlight key open questions and design challenges, and propose a shared agenda for multimodal, adaptive, and trustworthy robotic collaboration in hybrid work environments.
* 9 pages
Questionnaires for Everyone: Streamlining Cross-Cultural Questionnaire Adaptation with GPT-Based Translation Quality Evaluation
Jul 30, 2024



Adapting questionnaires to new languages is a resource-intensive process often requiring the hiring of multiple independent translators, which limits the ability of researchers to conduct cross-cultural research and effectively creates inequalities in research and society. This work presents a prototype tool that can expedite the questionnaire translation process. The tool incorporates forward-backward translation using DeepL alongside GPT-4-generated translation quality evaluations and improvement suggestions. We conducted two online studies in which participants translated questionnaires from English to either German (Study 1; n=10) or Portuguese (Study 2; n=20) using our prototype. To evaluate the quality of the translations created using the tool, evaluation scores between conventionally translated and tool-supported versions were compared. Our results indicate that integrating LLM-generated translation quality evaluations and suggestions for improvement can help users independently attain results similar to those provided by conventional, non-NLP-supported translation methods. This is the first step towards more equitable questionnaire-based research, powered by AI.
"AI enhances our performance, I have no doubt this one will do the same": The Placebo effect is robust to negative descriptions of AI
Sep 28, 2023
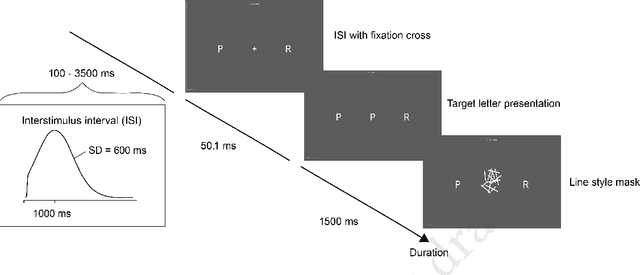


Heightened AI expectations facilitate performance in human-AI interactions through placebo effects. While lowering expectations to control for placebo effects is advisable, overly negative expectations could induce nocebo effects. In a letter discrimination task, we informed participants that an AI would either increase or decrease their performance by adapting the interface, but in reality, no AI was present in any condition. A Bayesian analysis showed that participants had high expectations and performed descriptively better irrespective of the AI description when a sham-AI was present. Using cognitive modeling, we could trace this advantage back to participants gathering more information. A replication study verified that negative AI descriptions do not alter expectations, suggesting that performance expectations with AI are biased and robust to negative verbal descriptions. We discuss the impact of user expectations on AI interactions and evaluation and provide a behavioral placebo marker for human-AI interaction
The AI Ghostwriter Effect: Users Do Not Perceive Ownership of AI-Generated Text But Self-Declare as Authors
Mar 06, 2023Human-AI interaction in text production increases complexity in authorship. In two empirical studies (n1 = 30 & n2 = 96), we investigate authorship and ownership in human-AI collaboration for personalized language generation models. We show an AI Ghostwriter Effect: Users do not consider themselves the owners and authors of AI-generated text but refrain from publicly declaring AI authorship. The degree of personalization did not impact the AI Ghostwriter Effect, and control over the model increased participants' sense of ownership. We also found that the discrepancy between the sense of ownership and the authorship declaration is stronger in interactions with a human ghostwriter and that people use similar rationalizations for authorship in AI ghostwriters and human ghostwriters. We discuss how our findings relate to psychological ownership and human-AI interaction to lay the foundations for adapting authorship frameworks and user interfaces in AI in text-generation tasks.
Investigating Labeler Bias in Face Annotation for Machine Learning
Jan 24, 2023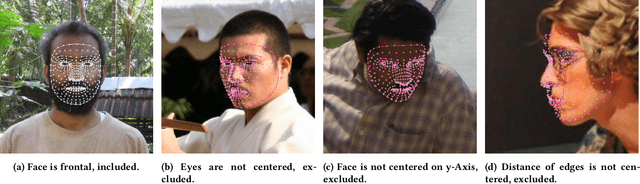



In a world increasingly reliant on artificial intelligence, it is more important than ever to consider the ethical implications of artificial intelligence on humanity. One key under-explored challenge is labeler bias, which can create inherently biased datasets for training and subsequently lead to inaccurate or unfair decisions in healthcare, employment, education, and law enforcement. Hence, we conducted a study to investigate and measure the existence of labeler bias using images of people from different ethnicities and sexes in a labeling task. Our results show that participants possess stereotypes that influence their decision-making process and that labeler demographics impact assigned labels. We also discuss how labeler bias influences datasets and, subsequently, the models trained on them. Overall, a high degree of transparency must be maintained throughout the entire artificial intelligence training process to identify and correct biases in the data as early as possible.