 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Too Much? Understanding How Large Language Model Reasoning Traces Influence Performance and Metacognition
May 25, 2026Large Language Model interfaces are increasingly verbose, exposing intermediate reasoning traces alongside final answers. Traces are framed as transparency mechanisms, yet it is unclear how people use them to solve problems. We report a preregistered between-subjects study (N = 559) in which participants solved ten LSAT-style reasoning problems under one of three conditions: an Answer-only baseline, a Full-trace revealed before the answer, and a Summary-trace presented alongside the answer. Summaries preserved task performance at the no-trace baseline while significantly elevating trust and hedonic appeal, establishing that trace exposure shifts subjective appraisal of the interaction without bringing performance benefits. Under an open-weight reasoning model exposing verbose intermediate output, full traces additionally impaired performance relative to the answer-only baseline. Across all conditions, participants substantially overestimated their performance, and no trace format supported calibrated self-evaluation. Further analysis indicates that hedonic appeal, not trust, carries the indirect path to overestimation, consistent with a processing-fluency account. Reasoning traces are best understood as user-facing interface artifacts rather than transparent windows into model cognition, and calibration is unlikely to emerge from the traces themselves and may best be scaffolded by interactions that elicit users' own reasoning first.
Within-Model vs Between-Prompt Variability in Large Language Models for Creative Tasks
Jan 29, 2026How much of LLM output variance is explained by prompts versus model choice versus stochasticity through sampling? We answer this by evaluating 12 LLMs on 10 creativity prompts with 100 samples each (N = 12,000). For output quality (originality), prompts explain 36.43% of variance, comparable to model choice (40.94%). But for output quantity (fluency), model choice (51.25%) and within-LLM variance (33.70%) dominate, with prompts explaining only 4.22%. Prompts are powerful levers for steering output quality, but given the substantial within-LLM variance (10-34%), single-sample evaluations risk conflating sampling noise with genuine prompt or model effects.
HappyRouting: Learning Emotion-Aware Route Trajectories for Scalable In-The-Wild Navigation
Jan 28, 2024
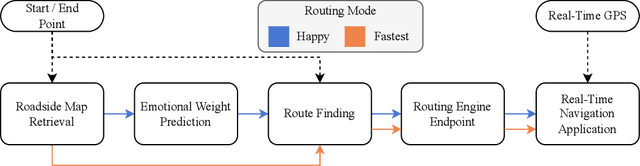


Routes represent an integral part of triggering emotions in drivers. Navigation systems allow users to choose a navigation strategy, such as the fastest or shortest route. However, they do not consider the driver's emotional well-being. We present HappyRouting, a novel navigation-based empathic car interface guiding drivers through real-world traffic while evoking positive emotions. We propose design considerations, derive a technical architecture, and implement a routing optimization framework. Our contribution is a machine learning-based generated emotion map layer, predicting emotions along routes based on static and dynamic contextual data. We evaluated HappyRouting in a real-world driving study (N=13), finding that happy routes increase subjectively perceived valence by 11% (p=.007). Although happy routes take 1.25 times longer on average, participants perceived the happy route as shorter, presenting an emotion-enhanced alternative to today's fastest routing mechanisms. We discuss how emotion-based routing can be integrated into navigation apps, promoting emotional well-being for mobility use.
Large Language Models to the Rescue: Reducing the Complexity in Scientific Workflow Development Using ChatGPT
Nov 06, 2023
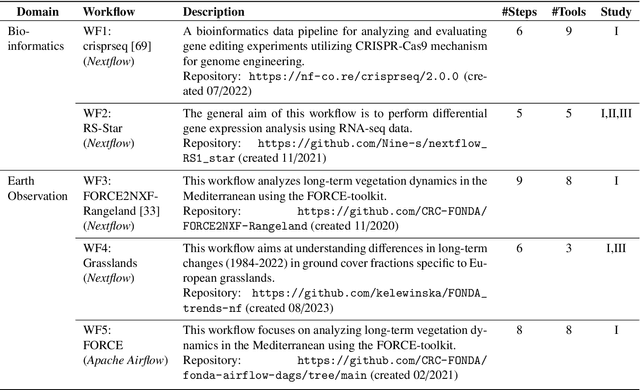

Scientific workflow systems are increasingly popular for expressing and executing complex data analysis pipelines over large datasets, as they offer reproducibility, dependability, and scalability of analyses by automatic parallelization on large compute clusters. However, implementing workflows is difficult due to the involvement of many black-box tools and the deep infrastructure stack necessary for their execution. Simultaneously, user-supporting tools are rare, and the number of available examples is much lower than in classical programming languages. To address these challenges, we investigate the efficiency of Large Language Models (LLMs), specifically ChatGPT, to support users when dealing with scientific workflows. We performed three user studies in two scientific domains to evaluate ChatGPT for comprehending, adapting, and extending workflows. Our results indicate that LLMs efficiently interpret workflows but achieve lower performance for exchanging components or purposeful workflow extensions. We characterize their limitations in these challenging scenarios and suggest future research directions.
"AI enhances our performance, I have no doubt this one will do the same": The Placebo effect is robust to negative descriptions of AI
Sep 28, 2023
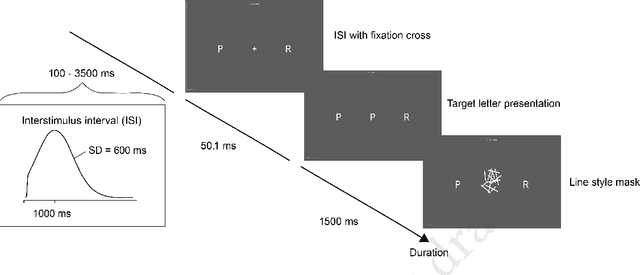


Heightened AI expectations facilitate performance in human-AI interactions through placebo effects. While lowering expectations to control for placebo effects is advisable, overly negative expectations could induce nocebo effects. In a letter discrimination task, we informed participants that an AI would either increase or decrease their performance by adapting the interface, but in reality, no AI was present in any condition. A Bayesian analysis showed that participants had high expectations and performed descriptively better irrespective of the AI description when a sham-AI was present. Using cognitive modeling, we could trace this advantage back to participants gathering more information. A replication study verified that negative AI descriptions do not alter expectations, suggesting that performance expectations with AI are biased and robust to negative verbal descriptions. We discuss the impact of user expectations on AI interactions and evaluation and provide a behavioral placebo marker for human-AI interaction