 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring AI-Augmented Sensemaking of Patient-Generated Health Data: A Mixed-Method Study with Healthcare Professionals in Cardiac Risk Reduction
Feb 05, 2026Individuals are increasingly generating substantial personal health and lifestyle data, e.g. through wearables and smartphones. While such data could transform preventative care, its integration into clinical practice is hindered by its scale, heterogeneity and the time pressure and data literacy of healthcare professionals (HCPs). We explore how large language models (LLMs) can support sensemaking of patient-generated health data (PGHD) with automated summaries and natural language data exploration. Using cardiovascular disease (CVD) risk reduction as a use case, 16 HCPs reviewed multimodal PGHD in a mixed-methods study with a prototype that integrated common charts, LLM-generated summaries, and a conversational interface. Findings show that AI summaries provided quick overviews that anchored exploration, while conversational interaction supported flexible analysis and bridged data-literacy gaps. However, HCPs raised concerns about transparency, privacy, and overreliance. We contribute empirical insights and sociotechnical design implications for integrating AI-driven summarization and conversation into clinical workflows to support PGHD sensemaking.
Designing Intent: A Multimodal Framework for Human-Robot Cooperation in Industrial Workspaces
Jun 18, 2025As robots enter collaborative workspaces, ensuring mutual understanding between human workers and robotic systems becomes a prerequisite for trust, safety, and efficiency. In this position paper, we draw on the cooperation scenario of the AIMotive project in which a human and a cobot jointly perform assembly tasks to argue for a structured approach to intent communication. Building on the Situation Awareness-based Agent Transparency (SAT) framework and the notion of task abstraction levels, we propose a multidimensional design space that maps intent content (SAT1, SAT3), planning horizon (operational to strategic), and modality (visual, auditory, haptic). We illustrate how this space can guide the design of multimodal communication strategies tailored to dynamic collaborative work contexts. With this paper, we lay the conceptual foundation for a future design toolkit aimed at supporting transparent human-robot interaction in the workplace. We highlight key open questions and design challenges, and propose a shared agenda for multimodal, adaptive, and trustworthy robotic collaboration in hybrid work environments.
* 9 pages
An Approach to Elicit Human-Understandable Robot Expressions to Support Human-Robot Interaction
Oct 01, 2024Understanding the intentions of robots is essential for natural and seamless human-robot collaboration. Ensuring that robots have means for non-verbal communication is a basis for intuitive and implicit interaction. For this, we contribute an approach to elicit and design human-understandable robot expressions. We outline the approach in the context of non-humanoid robots. We paired human mimicking and enactment with research from gesture elicitation in two phases: first, to elicit expressions, and second, to ensure they are understandable. We present an example application through two studies (N=16 \& N=260) of our approach to elicit expressions for a simple 6-DoF robotic arm. We show that it enabled us to design robot expressions that signal curiosity and interest in getting attention. Our main contribution is an approach to generate and validate understandable expressions for robots, enabling more natural human-robot interaction.
HappyRouting: Learning Emotion-Aware Route Trajectories for Scalable In-The-Wild Navigation
Jan 28, 2024
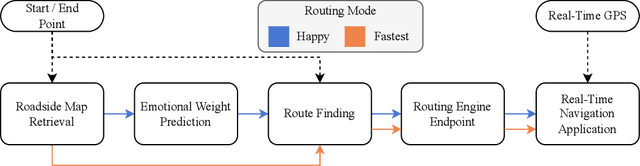


Routes represent an integral part of triggering emotions in drivers. Navigation systems allow users to choose a navigation strategy, such as the fastest or shortest route. However, they do not consider the driver's emotional well-being. We present HappyRouting, a novel navigation-based empathic car interface guiding drivers through real-world traffic while evoking positive emotions. We propose design considerations, derive a technical architecture, and implement a routing optimization framework. Our contribution is a machine learning-based generated emotion map layer, predicting emotions along routes based on static and dynamic contextual data. We evaluated HappyRouting in a real-world driving study (N=13), finding that happy routes increase subjectively perceived valence by 11% (p=.007). Although happy routes take 1.25 times longer on average, participants perceived the happy route as shorter, presenting an emotion-enhanced alternative to today's fastest routing mechanisms. We discuss how emotion-based routing can be integrated into navigation apps, promoting emotional well-being for mobility use.
In Sync: Exploring Synchronization to Increase Trust Between Humans and Non-humanoid Robots
Apr 06, 2023



When we go for a walk with friends, we can observe an interesting effect: From step lengths to arm movements - our movements unconsciously align; they synchronize. Prior research found that this synchronization is a crucial aspect of human relations that strengthens social cohesion and trust. Generalizing from these findings in synchronization theory, we propose a dynamical approach that can be applied in the design of non-humanoid robots to increase trust. We contribute the results of a controlled experiment with 51 participants exploring our concept in a between-subjects design. For this, we built a prototype of a simple non-humanoid robot that can bend to follow human movements and vary the movement synchronization patterns. We found that synchronized movements lead to significantly higher ratings in an established questionnaire on trust between people and automation but did not influence the willingness to spend money in a trust game.
Understanding the Uncertainty Loop of Human-Robot Interaction
Mar 14, 2023Recently the field of Human-Robot Interaction gained popularity, due to the wide range of possibilities of how robots can support humans during daily tasks. One form of supportive robots are socially assistive robots which are specifically built for communicating with humans, e.g., as service robots or personal companions. As they understand humans through artificial intelligence, these robots will at some point make wrong assumptions about the humans' current state and give an unexpected response. In human-human conversations, unexpected responses happen frequently. However, it is currently unclear how such robots should act if they understand that the human did not expect their response, or even showing the uncertainty of their response in the first place. For this, we explore the different forms of potential uncertainties during human-robot conversations and how humanoids can, through verbal and non-verbal cues, communicate these uncertainties.
The AI Ghostwriter Effect: Users Do Not Perceive Ownership of AI-Generated Text But Self-Declare as Authors
Mar 06, 2023Human-AI interaction in text production increases complexity in authorship. In two empirical studies (n1 = 30 & n2 = 96), we investigate authorship and ownership in human-AI collaboration for personalized language generation models. We show an AI Ghostwriter Effect: Users do not consider themselves the owners and authors of AI-generated text but refrain from publicly declaring AI authorship. The degree of personalization did not impact the AI Ghostwriter Effect, and control over the model increased participants' sense of ownership. We also found that the discrepancy between the sense of ownership and the authorship declaration is stronger in interactions with a human ghostwriter and that people use similar rationalizations for authorship in AI ghostwriters and human ghostwriters. We discuss how our findings relate to psychological ownership and human-AI interaction to lay the foundations for adapting authorship frameworks and user interfaces in AI in text-generation tasks.
Investigating Labeler Bias in Face Annotation for Machine Learning
Jan 24, 2023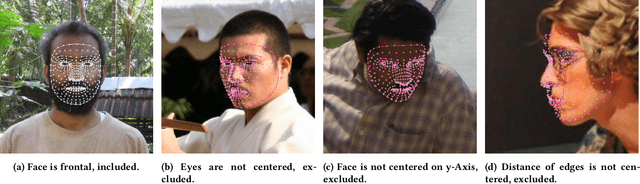



In a world increasingly reliant on artificial intelligence, it is more important than ever to consider the ethical implications of artificial intelligence on humanity. One key under-explored challenge is labeler bias, which can create inherently biased datasets for training and subsequently lead to inaccurate or unfair decisions in healthcare, employment, education, and law enforcement. Hence, we conducted a study to investigate and measure the existence of labeler bias using images of people from different ethnicities and sexes in a labeling task. Our results show that participants possess stereotypes that influence their decision-making process and that labeler demographics impact assigned labels. We also discuss how labeler bias influences datasets and, subsequently, the models trained on them. Overall, a high degree of transparency must be maintained throughout the entire artificial intelligence training process to identify and correct biases in the data as early as possible.
EEG2Vec: Learning Affective EEG Representations via Variational Autoencoders
Jul 16, 2022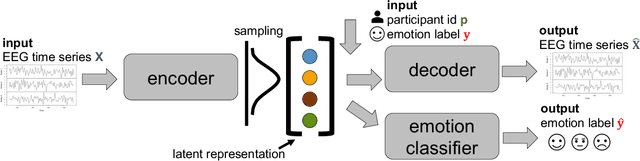
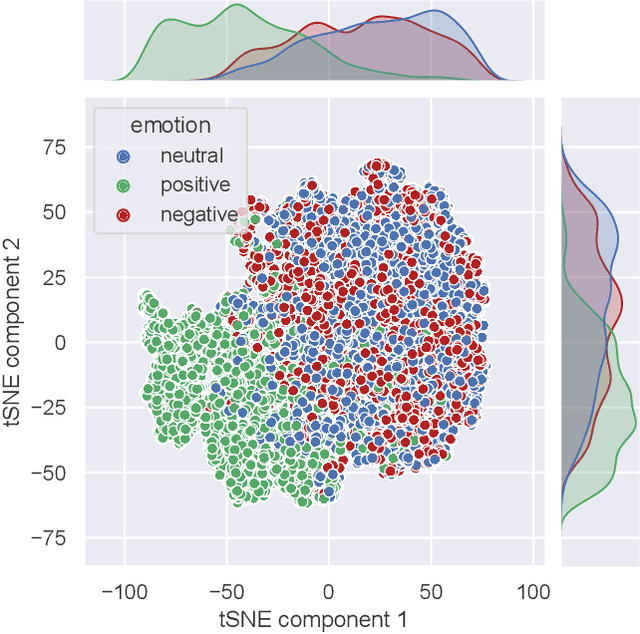
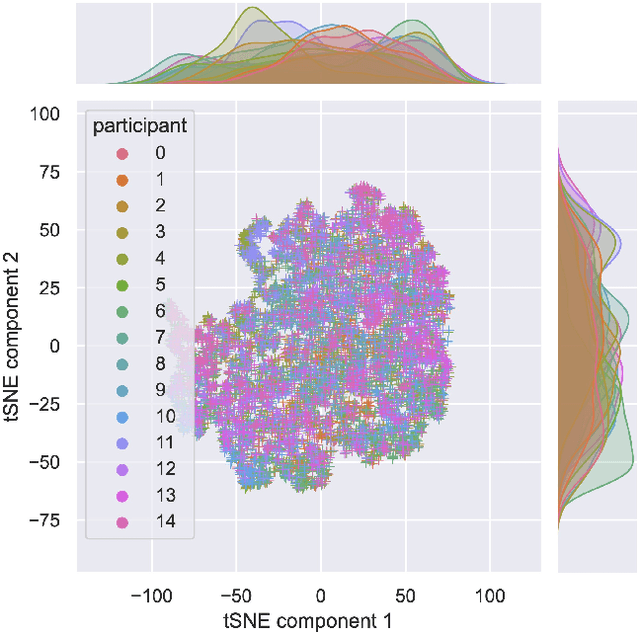
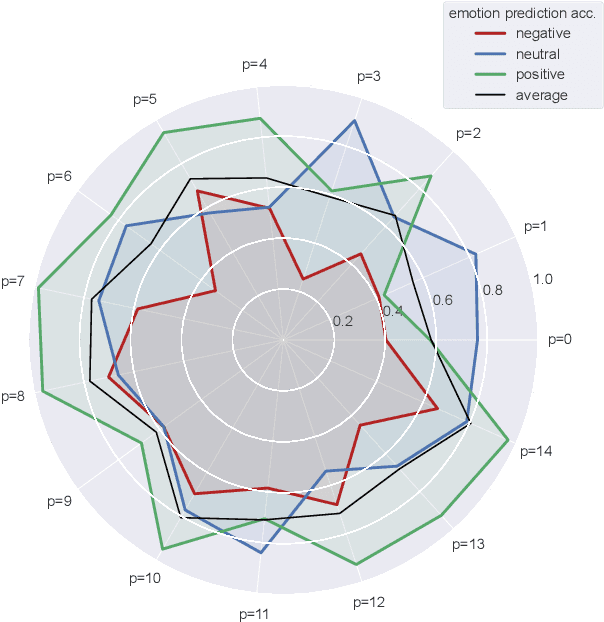
There is a growing need for sparse representational formats of human affective states that can be utilized in scenarios with limited computational memory resources. We explore whether representing neural data, in response to emotional stimuli, in a latent vector space can serve to both predict emotional states as well as generate synthetic EEG data that are participant- and/or emotion-specific. We propose a conditional variational autoencoder based framework, EEG2Vec, to learn generative-discriminative representations from EEG data. Experimental results on affective EEG recording datasets demonstrate that our model is suitable for unsupervised EEG modeling, classification of three distinct emotion categories (positive, neutral, negative) based on the latent representation achieves a robust performance of 68.49%, and generated synthetic EEG sequences resemble real EEG data inputs to particularly reconstruct low-frequency signal components. Our work advances areas where affective EEG representations can be useful in e.g., generating artificial (labeled) training data or alleviating manual feature extraction, and provide efficiency for memory constrained edge computing applications.
Exploiting Multiple EEG Data Domains with Adversarial Learning
Apr 16, 2022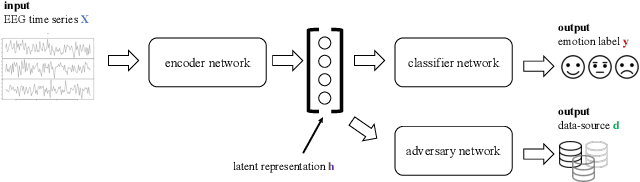
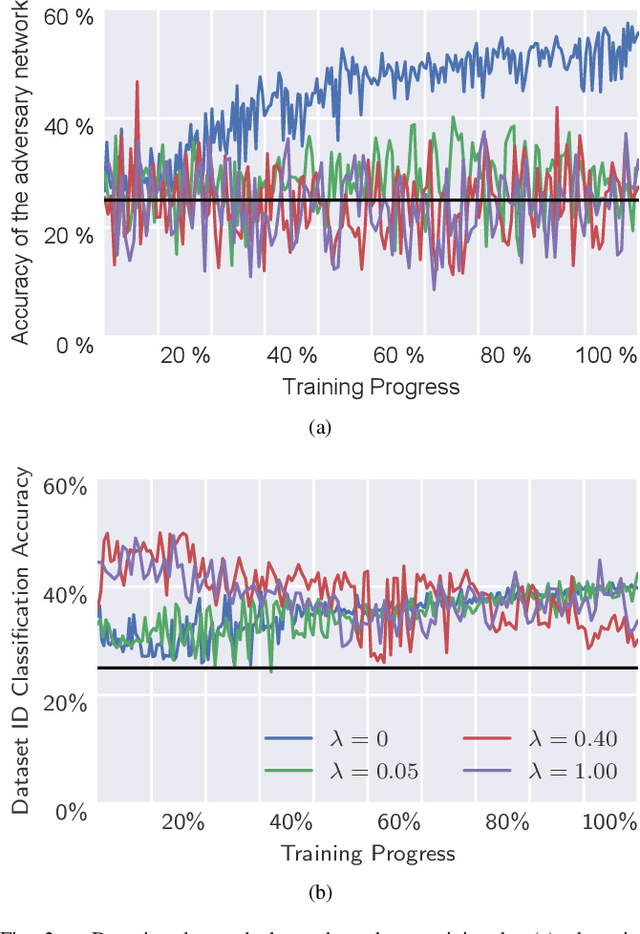
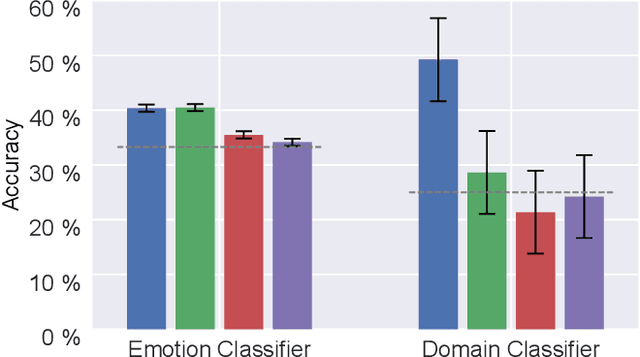
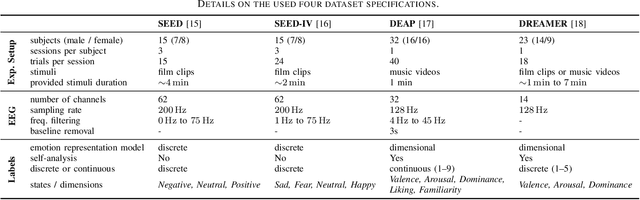
Electroencephalography (EEG) is shown to be a valuable data source for evaluating subjects' mental states. However, the interpretation of multi-modal EEG signals is challenging, as they suffer from poor signal-to-noise-ratio, are highly subject-dependent, and are bound to the equipment and experimental setup used, (i.e. domain). This leads to machine learning models often suffer from poor generalization ability, where they perform significantly worse on real-world data than on the exploited training data. Recent research heavily focuses on cross-subject and cross-session transfer learning frameworks to reduce domain calibration efforts for EEG signals. We argue that multi-source learning via learning domain-invariant representations from multiple data-sources is a viable alternative, as the available data from different EEG data-source domains (e.g., subjects, sessions, experimental setups) grow massively. We propose an adversarial inference approach to learn data-source invariant representations in this context, enabling multi-source learning for EEG-based brain-computer interfaces. We unify EEG recordings from different source domains (i.e., emotion recognition datasets SEED, SEED-IV, DEAP, DREAMER), and demonstrate the feasibility of our invariant representation learning approach in suppressing data-source-relevant information leakage by 35% while still achieving stable EEG-based emotion classification performance.