 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision for AI-Driven Adaptation of Dynamic AR Content to Users and Environments
Apr 23, 2025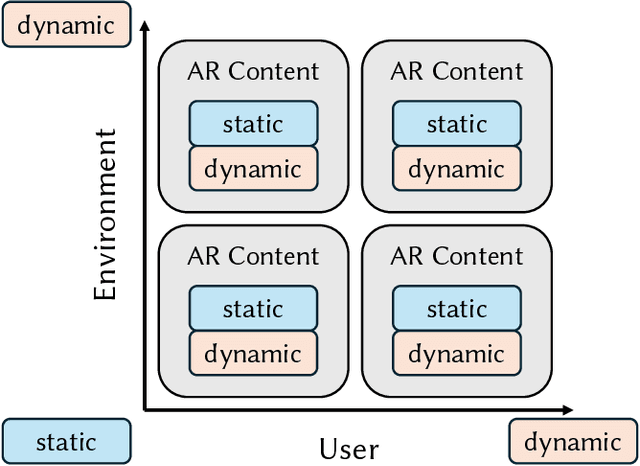
Augmented Reality (AR) is transforming the way we interact with virtual information in the physical world. By overlaying digital content in real-world environments, AR enables new forms of immersive and engaging experiences. However, existing AR systems often struggle to effectively manage the many interactive possibilities that AR presents. This vision paper speculates on AI-driven approaches for adaptive AR content placement, dynamically adjusting to user movement and environmental changes. By leveraging machine learning methods, such a system would intelligently manage content distribution between AR projections integrated into the external environment and fixed static content, enabling seamless UI layout and potentially reducing users' cognitive load. By exploring the possibilities of AI-driven dynamic AR content placement, we aim to envision new opportunities for innovation and improvement in various industries, from urban navigation and workplace productivity to immersive learning and beyond. This paper outlines a vision for the development of more intuitive, engaging, and effective AI-powered AR experiences.
Teaching Wav2Vec2 the Language of the Brain
Jan 16, 2025



The decoding of continuously spoken speech from neuronal activity has the potential to become an important clinical solution for paralyzed patients. Deep Learning Brain Computer Interfaces (BCIs) have recently successfully mapped neuronal activity to text contents in subjects who attempted to formulate speech. However, only small BCI datasets are available. In contrast, labeled data and pre-trained models for the closely related task of speech recognition from audio are widely available. One such model is Wav2Vec2 which has been trained in a self-supervised fashion to create meaningful representations of speech audio data. In this study, we show that patterns learned by Wav2Vec2 are transferable to brain data. Specifically, we replace its audio feature extractor with an untrained Brain Feature Extractor (BFE) model. We then execute full fine-tuning with pre-trained weights for Wav2Vec2, training ''from scratch'' without pre-trained weights as well as freezing a pre-trained Wav2Vec2 and training only the BFE each for 45 different BFE architectures. Across these experiments, the best run is from full fine-tuning with pre-trained weights, achieving a Character Error Rate (CER) of 18.54\%, outperforming the best training from scratch run by 20.46\% and that of frozen Wav2Vec2 training by 15.92\% percentage points. These results indicate that knowledge transfer from audio speech recognition to brain decoding is possible and significantly improves brain decoding performance for the same architectures. Related source code is available at https://github.com/tfiedlerdev/Wav2Vec2ForBrain.
Experimental analysis of the TRC benchmark system
Mar 12, 2024



The Tribomechadynamics Research Challenge (TRC) was a blind prediction of the vibration behavior of a thin plate clamped on two sides using bolted joints. The first bending mode's natural frequency and damping ratio were requested as function of the amplitude, starting from the linear regime until high levels, where both frictional contact and nonlinear bending-stretching coupling become relevant. The predictions were confronted with experimental results in a companion paper; the present article addresses the experimental analysis of this benchmark system. Amplitude-dependent modal data was obtained from phase resonance and response controlled tests. An original variant of response controlled testing is proposed: Instead of a fixed frequency interval, a fixed phase interval is analyzed. This way, the high excitation levels required outside resonance, which could activate unwanted exciter nonlinearity, are avoided. Consistency of testing methods is carefully analyzed. Overall, these measures have permitted to gain high confidence in the acquired modal data. The different sources of the remaining uncertainty were further analyzed. A low reassembly-variability but a moderate time-variability were identified, where the latter is attributed to some thermal sensitivity of the system. Two nominally identical plates were analyzed, which both have an appreciable initial curvature, and a significant effect on the vibration behavior was found depending on whether the plate is aligned/misaligned with the support structure. Further, a 1:2 nonlinear modal interaction with the first torsion mode was observed, which only occurs in the aligned configurations.
Digital Modeling for Everyone: Exploring How Novices Approach Voice-Based 3D Modeling
Jul 10, 2023Manufacturing tools like 3D printers have become accessible to the wider society, making the promise of digital fabrication for everyone seemingly reachable. While the actual manufacturing process is largely automated today, users still require knowledge of complex design applications to produce ready-designed objects and adapt them to their needs or design new objects from scratch. To lower the barrier to the design and customization of personalized 3D models, we explored novice mental models in voice-based 3D modeling by conducting a high-fidelity Wizard of Oz study with 22 participants. We performed a thematic analysis of the collected data to understand how the mental model of novices translates into voice-based 3D modeling. We conclude with design implications for voice assistants. For example, they have to: deal with vague, incomplete and wrong commands; provide a set of straightforward commands to shape simple and composite objects; and offer different strategies to select 3D objects.
In Sync: Exploring Synchronization to Increase Trust Between Humans and Non-humanoid Robots
Apr 06, 2023



When we go for a walk with friends, we can observe an interesting effect: From step lengths to arm movements - our movements unconsciously align; they synchronize. Prior research found that this synchronization is a crucial aspect of human relations that strengthens social cohesion and trust. Generalizing from these findings in synchronization theory, we propose a dynamical approach that can be applied in the design of non-humanoid robots to increase trust. We contribute the results of a controlled experiment with 51 participants exploring our concept in a between-subjects design. For this, we built a prototype of a simple non-humanoid robot that can bend to follow human movements and vary the movement synchronization patterns. We found that synchronized movements lead to significantly higher ratings in an established questionnaire on trust between people and automation but did not influence the willingness to spend money in a trust game.
Lateral Ego-Vehicle Control without Supervision using Point Clouds
Mar 20, 2022


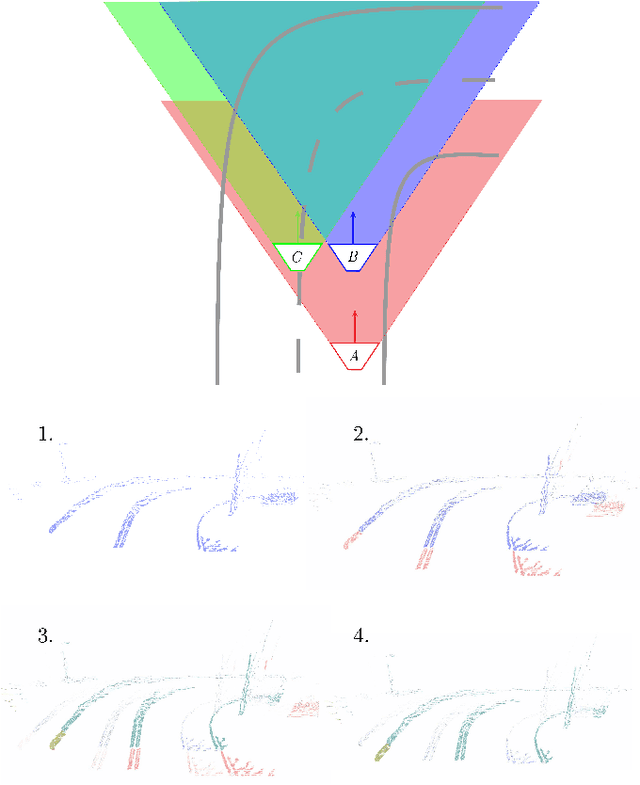
Existing vision based supervised approaches to lateral vehicle control are capable of directly mapping RGB images to the appropriate steering commands. However, they are prone to suffering from inadequate robustness in real world scenarios due to a lack of failure cases in the training data. In this paper, a framework for training a more robust and scalable model for lateral vehicle control is proposed. The framework only requires an unlabeled sequence of RGB images. The trained model takes a point cloud as input and predicts the lateral offset to a subsequent frame from which the steering angle is inferred. The frame poses are in turn obtained from visual odometry. The point cloud is conceived by projecting dense depth maps into 3D. An arbitrary number of additional trajectories from this point cloud can be generated during training. This is to increase the robustness of the model. Online experiments show that the performance of our method is superior to that of the supervised model.