 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration of Musical Timbres using a Text-Guided Diffusion Model
Apr 12, 2025



In recent years, text-to-audio systems have achieved remarkable success, enabling the generation of complete audio segments directly from text descriptions. While these systems also facilitate music creation, the element of human creativity and deliberate expression is often limited. In contrast, the present work allows composers, arrangers, and performers to create the basic building blocks for music creation: audio of individual musical notes for use in electronic instruments and DAWs. Through text prompts, the user can specify the timbre characteristics of the audio. We introduce a system that combines a latent diffusion model and multi-modal contrastive learning to generate musical timbres conditioned on text descriptions. By jointly generating the magnitude and phase of the spectrogram, our method eliminates the need for subsequently running a phase retrieval algorithm, as related methods do. Audio examples, source code, and a web app are available at https://wxuanyuan.github.io/Musical-Note-Generation/
Enhancing Multimodal Compositional Reasoning of Visual Language Models with Generative Negative Mining
Nov 07, 2023Contemporary large-scale visual language models (VLMs) exhibit strong representation capacities, making them ubiquitous for enhancing image and text understanding tasks. They are often trained in a contrastive manner on a large and diverse corpus of images and corresponding text captions scraped from the internet. Despite this, VLMs often struggle with compositional reasoning tasks which require a fine-grained understanding of the complex interactions of objects and their attributes. This failure can be attributed to two main factors: 1) Contrastive approaches have traditionally focused on mining negative examples from existing datasets. However, the mined negative examples might not be difficult for the model to discriminate from the positive. An alternative to mining would be negative sample generation 2) But existing generative approaches primarily focus on generating hard negative texts associated with a given image. Mining in the other direction, i.e., generating negative image samples associated with a given text has been ignored. To overcome both these limitations, we propose a framework that not only mines in both directions but also generates challenging negative samples in both modalities, i.e., images and texts. Leveraging these generative hard negative samples, we significantly enhance VLMs' performance in tasks involving multimodal compositional reasoning. Our code and dataset are released at https://ugorsahin.github.io/enhancing-multimodal-compositional-reasoning-of-vlm.html.
Robust Autonomous Vehicle Pursuit without Expert Steering Labels
Aug 16, 2023In this work, we present a learning method for lateral and longitudinal motion control of an ego-vehicle for vehicle pursuit. The car being controlled does not have a pre-defined route, rather it reactively adapts to follow a target vehicle while maintaining a safety distance. To train our model, we do not rely on steering labels recorded from an expert driver but effectively leverage a classical controller as an offline label generation tool. In addition, we account for the errors in the predicted control values, which can lead to a loss of tracking and catastrophic crashes of the controlled vehicle. To this end, we propose an effective data augmentation approach, which allows to train a network capable of handling different views of the target vehicle. During the pursuit, the target vehicle is firstly localized using a Convolutional Neural Network. The network takes a single RGB image along with cars' velocities and estimates the target vehicle's pose with respect to the ego-vehicle. This information is then fed to a Multi-Layer Perceptron, which regresses the control commands for the ego-vehicle, namely throttle and steering angle. We extensively validate our approach using the CARLA simulator on a wide range of terrains. Our method demonstrates real-time performance and robustness to different scenarios including unseen trajectories and high route completion. The project page containing code and multimedia can be publicly accessed here: https://changyaozhou.github.io/Autonomous-Vehicle-Pursuit/.
Multi Agent Navigation in Unconstrained Environments using a Centralized Attention based Graphical Neural Network Controller
Aug 10, 2023In this work, we propose a learning based neural model that provides both the longitudinal and lateral control commands to simultaneously navigate multiple vehicles. The goal is to ensure that each vehicle reaches a desired target state without colliding with any other vehicle or obstacle in an unconstrained environment. The model utilizes an attention based Graphical Neural Network paradigm that takes into consideration the state of all the surrounding vehicles to make an informed decision. This allows each vehicle to smoothly reach its destination while also evading collision with the other agents. The data and corresponding labels for training such a network is obtained using an optimization based procedure. Experimental results demonstrates that our model is powerful enough to generalize even to situations with more vehicles than in the training data. Our method also outperforms comparable graphical neural network architectures. Project page which includes the code and supplementary information can be found at https://yininghase.github.io/multi-agent-control/
LiDAR View Synthesis for Robust Vehicle Navigation Without Expert Labels
Aug 05, 2023Deep learning models for self-driving cars require a diverse training dataset to manage critical driving scenarios on public roads safely. This includes having data from divergent trajectories, such as the oncoming traffic lane or sidewalks. Such data would be too dangerous to collect in the real world. Data augmentation approaches have been proposed to tackle this issue using RGB images. However, solutions based on LiDAR sensors are scarce. Therefore, we propose synthesizing additional LiDAR point clouds from novel viewpoints without physically driving at dangerous positions. The LiDAR view synthesis is done using mesh reconstruction and ray casting. We train a deep learning model, which takes a LiDAR scan as input and predicts the future trajectory as output. A waypoint controller is then applied to this predicted trajectory to determine the throttle and steering labels of the ego-vehicle. Our method neither requires expert driving labels for the original nor the synthesized LiDAR sequence. Instead, we infer labels from LiDAR odometry. We demonstrate the effectiveness of our approach in a comprehensive online evaluation and with a comparison to concurrent work. Our results show the importance of synthesizing additional LiDAR point clouds, particularly in terms of model robustness. Project page: https://jonathsch.github.io/lidar-synthesis/
Multi-Vehicle Trajectory Prediction at Intersections using State and Intention Information
Jan 06, 2023Traditional approaches to prediction of future trajectory of road agents rely on knowing information about their past trajectory. This work rather relies only on having knowledge of the current state and intended direction to make predictions for multiple vehicles at intersections. Furthermore, message passing of this information between the vehicles provides each one of them a more holistic overview of the environment allowing for a more informed prediction. This is done by training a neural network which takes the state and intent of the multiple vehicles to predict their future trajectory. Using the intention as an input allows our approach to be extended to additionally control the multiple vehicles to drive towards desired paths. Experimental results demonstrate the robustness of our approach both in terms of trajectory prediction and vehicle control at intersections. The complete training and evaluation code for this work is available here: \url{https://github.com/Dekai21/Multi_Agent_Intersection}.
Biologically Inspired Neural Path Finding
Jun 13, 2022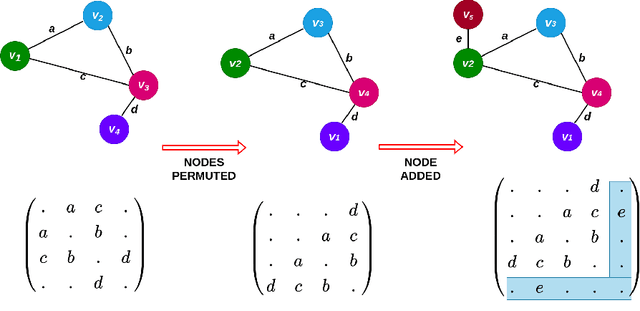
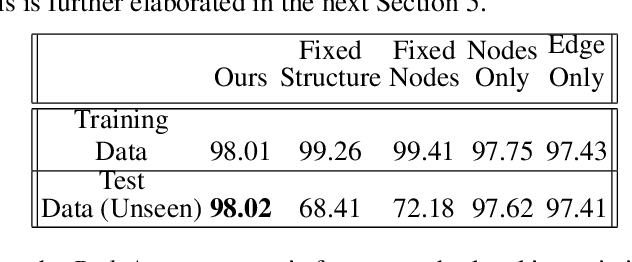
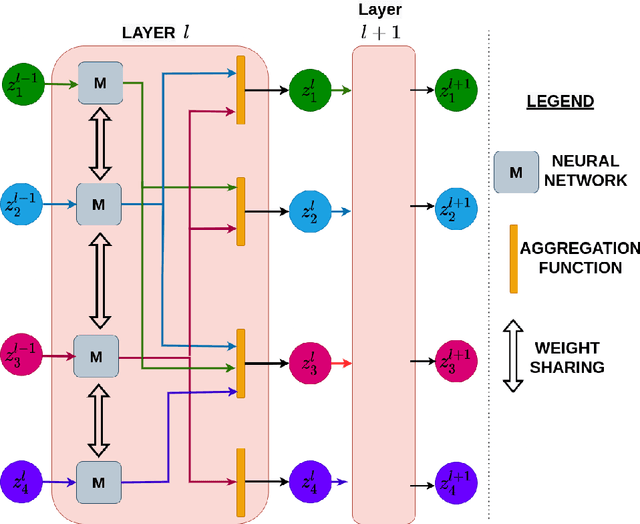
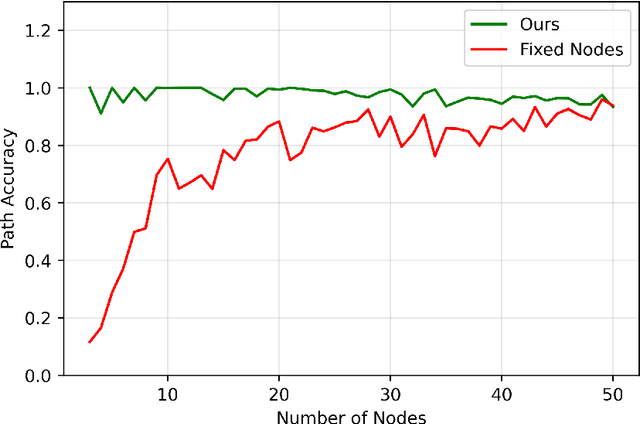
The human brain can be considered to be a graphical structure comprising of tens of billions of biological neurons connected by synapses. It has the remarkable ability to automatically re-route information flow through alternate paths in case some neurons are damaged. Moreover, the brain is capable of retaining information and applying it to similar but completely unseen scenarios. In this paper, we take inspiration from these attributes of the brain, to develop a computational framework to find the optimal low cost path between a source node and a destination node in a generalized graph. We show that our framework is capable of handling unseen graphs at test time. Moreover, it can find alternate optimal paths, when nodes are arbitrarily added or removed during inference, while maintaining a fixed prediction time. Code is available here: https://github.com/hangligit/pathfinding
Lateral Ego-Vehicle Control without Supervision using Point Clouds
Mar 20, 2022


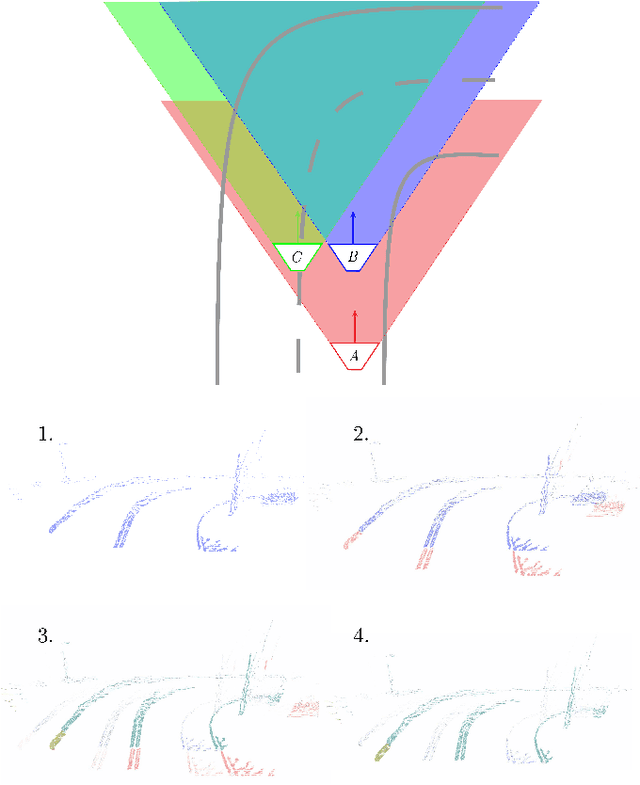
Existing vision based supervised approaches to lateral vehicle control are capable of directly mapping RGB images to the appropriate steering commands. However, they are prone to suffering from inadequate robustness in real world scenarios due to a lack of failure cases in the training data. In this paper, a framework for training a more robust and scalable model for lateral vehicle control is proposed. The framework only requires an unlabeled sequence of RGB images. The trained model takes a point cloud as input and predicts the lateral offset to a subsequent frame from which the steering angle is inferred. The frame poses are in turn obtained from visual odometry. The point cloud is conceived by projecting dense depth maps into 3D. An arbitrary number of additional trajectories from this point cloud can be generated during training. This is to increase the robustness of the model. Online experiments show that the performance of our method is superior to that of the supervised model.
Self-Supervised Steering Angle Prediction for Vehicle Control Using Visual Odometry
Mar 20, 2021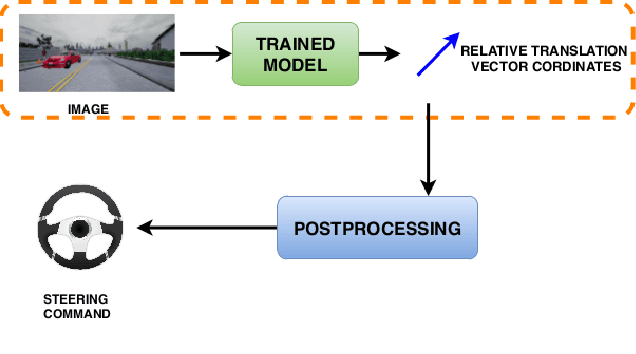
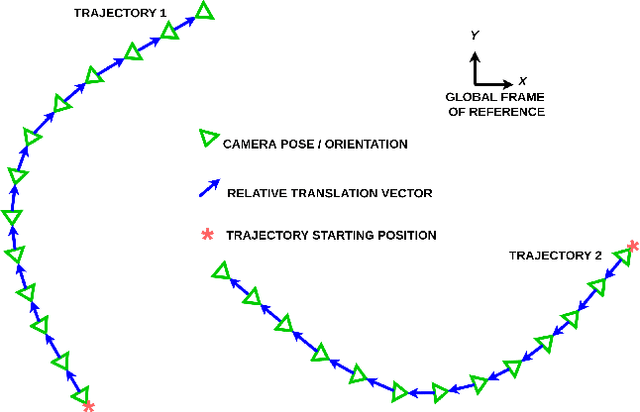
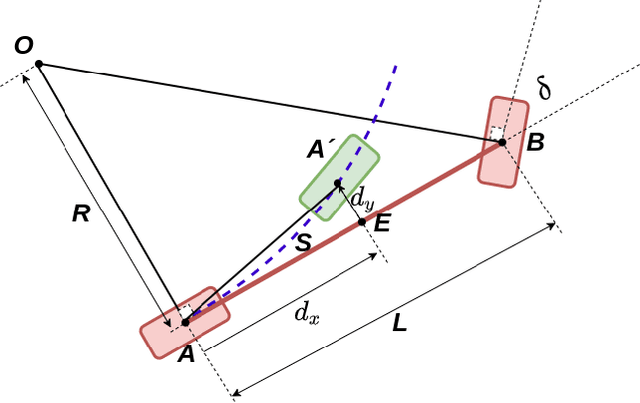
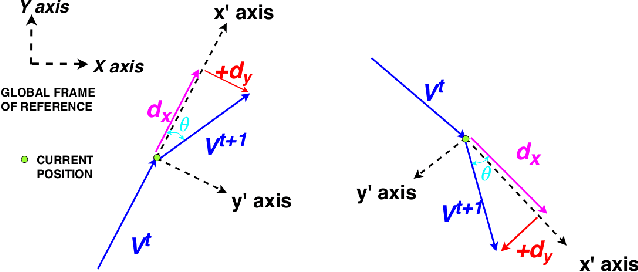
Vision-based learning methods for self-driving cars have primarily used supervised approaches that require a large number of labels for training. However, those labels are usually difficult and expensive to obtain. In this paper, we demonstrate how a model can be trained to control a vehicle's trajectory using camera poses estimated through visual odometry methods in an entirely self-supervised fashion. We propose a scalable framework that leverages trajectory information from several different runs using a camera setup placed at the front of a car. Experimental results on the CARLA simulator demonstrate that our proposed approach performs at par with the model trained with supervision.
4Seasons: A Cross-Season Dataset for Multi-Weather SLAM in Autonomous Driving
Sep 14, 2020
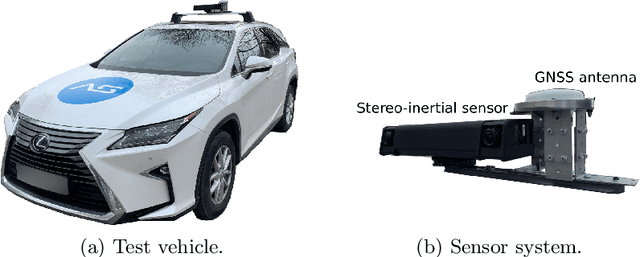


We present a novel dataset covering seasonal and challenging perceptual conditions for autonomous driving. Among others, it enables research on visual odometry, global place recognition, and map-based re-localization tracking. The data was collected in different scenarios and under a wide variety of weather conditions and illuminations, including day and night. This resulted in more than 350 km of recordings in nine different environments ranging from multi-level parking garage over urban (including tunnels) to countryside and highway. We provide globally consistent reference poses with up-to centimeter accuracy obtained from the fusion of direct stereo visual-inertial odometry with RTK-GNSS. The full dataset is available at www.4seasons-dataset.com.