 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multimodal Compositional Reasoning of Visual Language Models with Generative Negative Mining
Nov 07, 2023Contemporary large-scale visual language models (VLMs) exhibit strong representation capacities, making them ubiquitous for enhancing image and text understanding tasks. They are often trained in a contrastive manner on a large and diverse corpus of images and corresponding text captions scraped from the internet. Despite this, VLMs often struggle with compositional reasoning tasks which require a fine-grained understanding of the complex interactions of objects and their attributes. This failure can be attributed to two main factors: 1) Contrastive approaches have traditionally focused on mining negative examples from existing datasets. However, the mined negative examples might not be difficult for the model to discriminate from the positive. An alternative to mining would be negative sample generation 2) But existing generative approaches primarily focus on generating hard negative texts associated with a given image. Mining in the other direction, i.e., generating negative image samples associated with a given text has been ignored. To overcome both these limitations, we propose a framework that not only mines in both directions but also generates challenging negative samples in both modalities, i.e., images and texts. Leveraging these generative hard negative samples, we significantly enhance VLMs' performance in tasks involving multimodal compositional reasoning. Our code and dataset are released at https://ugorsahin.github.io/enhancing-multimodal-compositional-reasoning-of-vlm.html.
Introducing Model Inversion Attacks on Automatic Speaker Recognition
Jan 09, 2023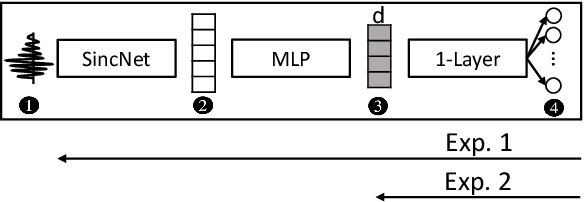
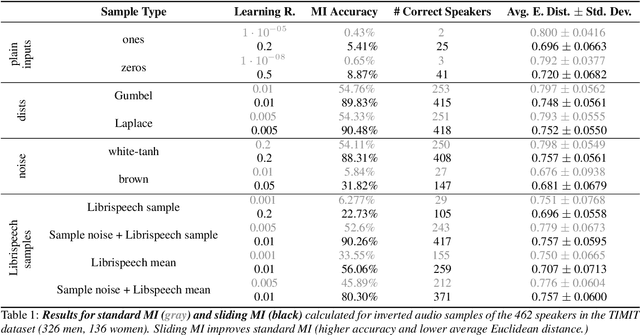
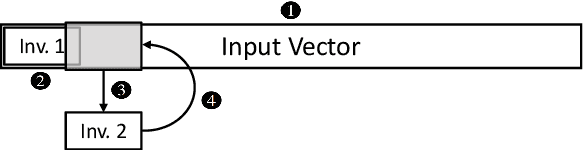
Model inversion (MI) attacks allow to reconstruct average per-class representations of a machine learning (ML) model's training data. It has been shown that in scenarios where each class corresponds to a different individual, such as face classifiers, this represents a severe privacy risk. In this work, we explore a new application for MI: the extraction of speakers' voices from a speaker recognition system. We present an approach to (1) reconstruct audio samples from a trained ML model and (2) extract intermediate voice feature representations which provide valuable insights into the speakers' biometrics. Therefore, we propose an extension of MI attacks which we call sliding model inversion. Our sliding MI extends standard MI by iteratively inverting overlapping chunks of the audio samples and thereby leveraging the sequential properties of audio data for enhanced inversion performance. We show that one can use the inverted audio data to generate spoofed audio samples to impersonate a speaker, and execute voice-protected commands for highly secured systems on their behalf. To the best of our knowledge, our work is the first one extending MI attacks to audio data, and our results highlight the security risks resulting from the extraction of the biometric data in that setup.
* for associated pdf, see https://www.isca-speech.org/archive/pdfs/spsc_2022/pizzi22_spsc.pdf