 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDM-VIO: Delayed Marginalization Visual-Inertial Odometry
Jan 11, 2022



We present DM-VIO, a monocular visual-inertial odometry system based on two novel techniques called delayed marginalization and pose graph bundle adjustment. DM-VIO performs photometric bundle adjustment with a dynamic weight for visual residuals. We adopt marginalization, which is a popular strategy to keep the update time constrained, but it cannot easily be reversed, and linearization points of connected variables have to be fixed. To overcome this we propose delayed marginalization: The idea is to maintain a second factor graph, where marginalization is delayed. This allows us to later readvance this delayed graph, yielding an updated marginalization prior with new and consistent linearization points. In addition, delayed marginalization enables us to inject IMU information into already marginalized states. This is the foundation of the proposed pose graph bundle adjustment, which we use for IMU initialization. In contrast to prior works on IMU initialization, it is able to capture the full photometric uncertainty, improving the scale estimation. In order to cope with initially unobservable scale, we continue to optimize scale and gravity direction in the main system after IMU initialization is complete. We evaluate our system on the EuRoC, TUM-VI, and 4Seasons datasets, which comprise flying drone, large-scale handheld, and automotive scenarios. Thanks to the proposed IMU initialization, our system exceeds the state of the art in visual-inertial odometry, even outperforming stereo-inertial methods while using only a single camera and IMU. The code will be published at http://vision.in.tum.de/dm-vio
MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera
Nov 24, 2020
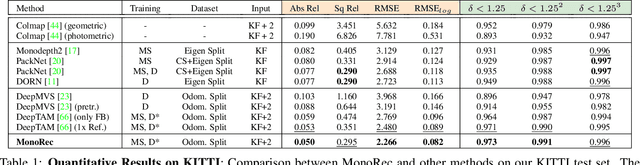
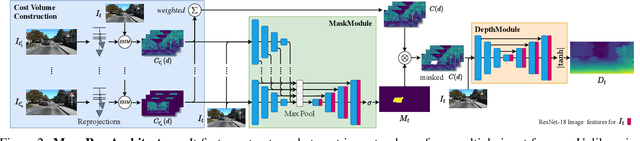

In this paper, we propose MonoRec, a semi-supervised monocular dense reconstruction architecture that predicts depth maps from a single moving camera in dynamic environments. MonoRec is based on a MVS setting which encodes the information of multiple consecutive images in a cost volume. To deal with dynamic objects in the scene, we introduce a MaskModule that predicts moving object masks by leveraging the photometric inconsistencies encoded in the cost volumes. Unlike other MVS methods, MonoRec is able to predict accurate depths for both static and moving objects by leveraging the predicted masks. Furthermore, we present a novel multi-stage training scheme with a semi-supervised loss formulation that does not require LiDAR depth values. We carefully evaluate MonoRec on the KITTI dataset and show that it achieves state-of-the-art performance compared to both multi-view and single-view methods. With the model trained on KITTI, we further demonstrate that MonoRec is able to generalize well to both the Oxford RobotCar dataset and the more challenging TUM-Mono dataset recorded by a handheld camera. Training code and pre-trained model will be published soon.
LM-Reloc: Levenberg-Marquardt Based Direct Visual Relocalization
Oct 13, 2020


We present LM-Reloc -- a novel approach for visual relocalization based on direct image alignment. In contrast to prior works that tackle the problem with a feature-based formulation, the proposed method does not rely on feature matching and RANSAC. Hence, the method can utilize not only corners but any region of the image with gradients. In particular, we propose a loss formulation inspired by the classical Levenberg-Marquardt algorithm to train LM-Net. The learned features significantly improve the robustness of direct image alignment, especially for relocalization across different conditions. To further improve the robustness of LM-Net against large image baselines, we propose a pose estimation network, CorrPoseNet, which regresses the relative pose to bootstrap the direct image alignment. Evaluations on the CARLA and Oxford RobotCar relocalization tracking benchmark show that our approach delivers more accurate results than previous state-of-the-art methods while being comparable in terms of robustness.
4Seasons: A Cross-Season Dataset for Multi-Weather SLAM in Autonomous Driving
Sep 14, 2020
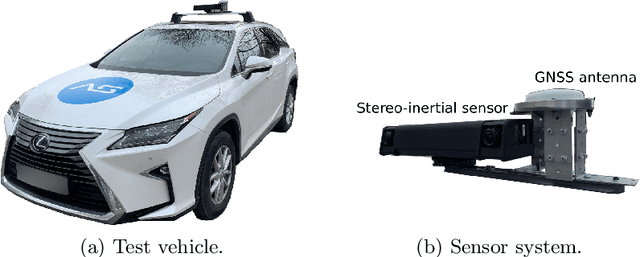


We present a novel dataset covering seasonal and challenging perceptual conditions for autonomous driving. Among others, it enables research on visual odometry, global place recognition, and map-based re-localization tracking. The data was collected in different scenarios and under a wide variety of weather conditions and illuminations, including day and night. This resulted in more than 350 km of recordings in nine different environments ranging from multi-level parking garage over urban (including tunnels) to countryside and highway. We provide globally consistent reference poses with up-to centimeter accuracy obtained from the fusion of direct stereo visual-inertial odometry with RTK-GNSS. The full dataset is available at www.4seasons-dataset.com.
D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry
Mar 28, 2020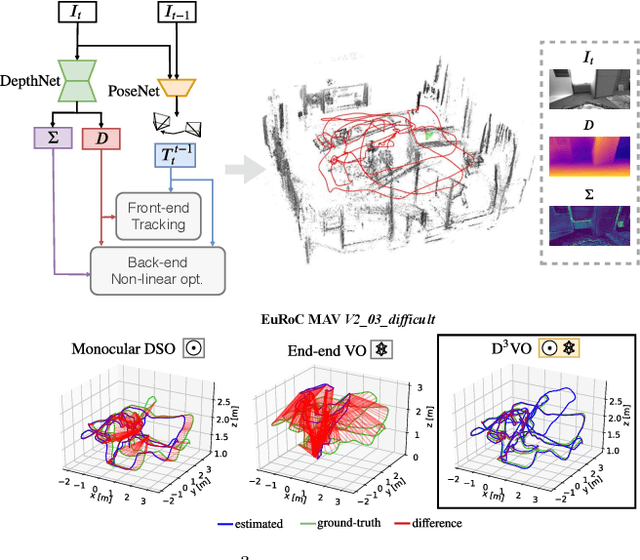
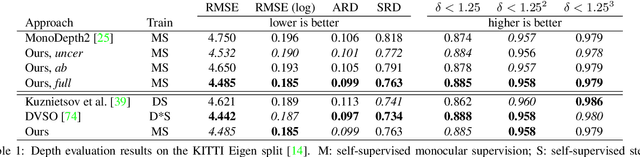
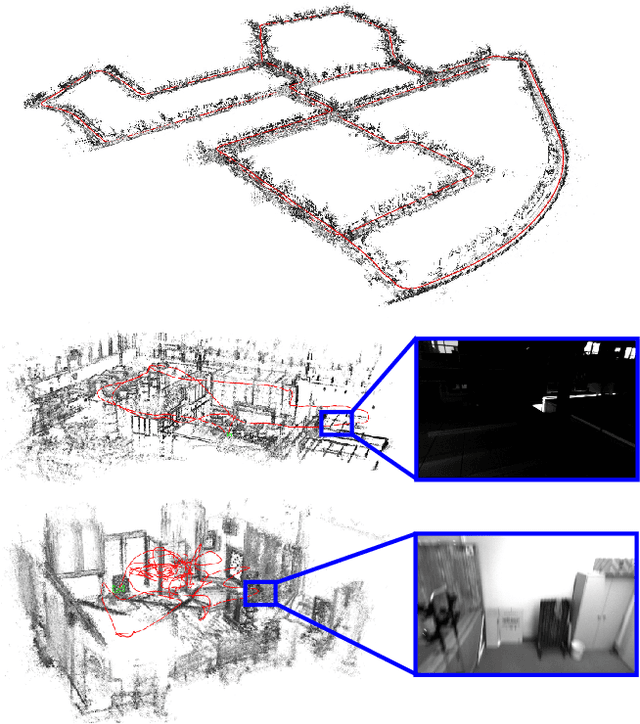
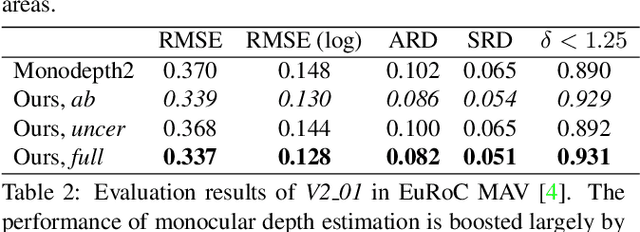
We propose D3VO as a novel framework for monocular visual odometry that exploits deep networks on three levels -- deep depth, pose and uncertainty estimation. We first propose a novel self-supervised monocular depth estimation network trained on stereo videos without any external supervision. In particular, it aligns the training image pairs into similar lighting condition with predictive brightness transformation parameters. Besides, we model the photometric uncertainties of pixels on the input images, which improves the depth estimation accuracy and provides a learned weighting function for the photometric residuals in direct (feature-less) visual odometry. Evaluation results show that the proposed network outperforms state-of-the-art self-supervised depth estimation networks. D3VO tightly incorporates the predicted depth, pose and uncertainty into a direct visual odometry method to boost both the front-end tracking as well as the back-end non-linear optimization. We evaluate D3VO in terms of monocular visual odometry on both the KITTI odometry benchmark and the EuRoC MAV dataset.The results show that D3VO outperforms state-of-the-art traditional monocular VO methods by a large margin. It also achieves comparable results to state-of-the-art stereo/LiDAR odometry on KITTI and to the state-of-the-art visual-inertial odometry on EuRoC MAV, while using only a single camera.
Rolling-Shutter Modelling for Direct Visual-Inertial Odometry
Nov 04, 2019



We present a direct visual-inertial odometry (VIO) method which estimates the motion of the sensor setup and sparse 3D geometry of the environment based on measurements from a rolling-shutter camera and an inertial measurement unit (IMU). The visual part of the system performs a photometric bundle adjustment on a sparse set of points. This direct approach does not extract feature points and is able to track not only corners, but any pixels with sufficient gradient magnitude. Neglecting rolling-shutter effects in the visual part severely degrades accuracy and robustness of the system. In this paper, we incorporate a rolling-shutter model into the photometric bundle adjustment that estimates a set of recent keyframe poses and the inverse depth of a sparse set of points. IMU information is accumulated between several frames using measurement preintegration, and is inserted into the optimization as an additional constraint between selected keyframes. For every keyframe we estimate not only the pose but also velocity and biases to correct the IMU measurements. Unlike systems with global-shutter cameras, we use both IMU measurements and rolling-shutter effects of the camera to estimate velocity and biases for every state. Last, we evaluate our system on a novel dataset that contains global-shutter and rolling-shutter images, IMU data and ground-truth poses for ten different sequences, which we make publicly available. Evaluation shows that the proposed method outperforms a system where rolling shutter is not modelled and achieves similar accuracy to the global-shutter method on global-shutter data.
GN-Net: The Gauss-Newton Loss for Deep Direct SLAM
Apr 26, 2019


Direct methods for SLAM have shown exceptional performance on odometry tasks. However, they still suffer from dynamic lighting/weather changes and from a bad initialization on large baselines. To mitigate both of these effects, we propose an approach which feeds deep visual descriptors for each pixel as input to the SLAM system. In this work, we introduce GN-Net: a network optimized with the novel Gauss-Newton loss for training deep features. It is designed to maximize the probability of the correct pixel correspondence inside the Gauss-Newton algorithm. This results in features with a larger convergence basin when compared with single-channel grayscale images generally used in SLAM-based approaches. Our network can be trained with ground-truth pixel correspondences between different images, produced either from simulation data or by any state-of-the-art SLAM algorithm. We show that our approach is more robust against bad initialization, variations in day-time, and weather changes thereby outperforming state-of-the-art direct and indirect methods. Furthermore, we release an evaluation benchmark for what we refer to as relocalization tracking. It has been created using the CARLA simulator as well as sequences taken from the Oxford RobotCar Dataset.
Omnidirectional DSO: Direct Sparse Odometry with Fisheye Cameras
Aug 08, 2018
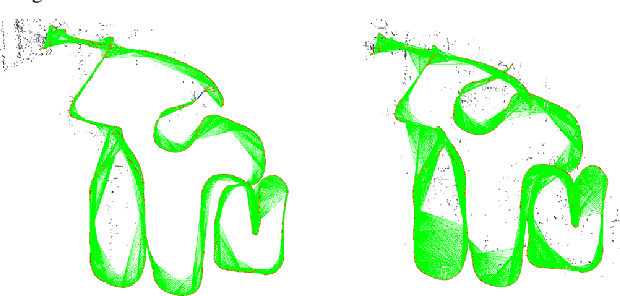


We propose a novel real-time direct monocular visual odometry for omnidirectional cameras. Our method extends direct sparse odometry (DSO) by using the unified omnidirectional model as a projection function, which can be applied to fisheye cameras with a field-of-view (FoV) well above 180 degrees. This formulation allows for using the full area of the input image even with strong distortion, while most existing visual odometry methods can only use a rectified and cropped part of it. Model parameters within an active keyframe window are jointly optimized, including the intrinsic/extrinsic camera parameters, 3D position of points, and affine brightness parameters. Thanks to the wide FoV, image overlap between frames becomes bigger and points are more spatially distributed. Our results demonstrate that our method provides increased accuracy and robustness over state-of-the-art visual odometry algorithms.
Direct Sparse Visual-Inertial Odometry using Dynamic Marginalization
Apr 16, 2018
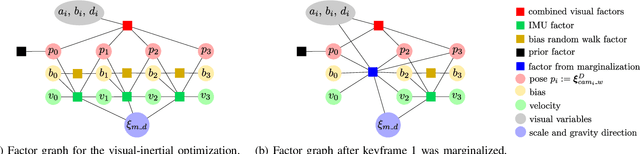
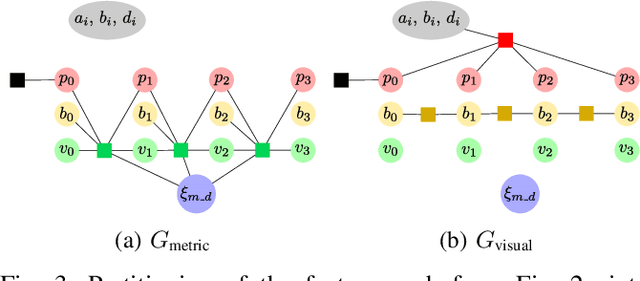
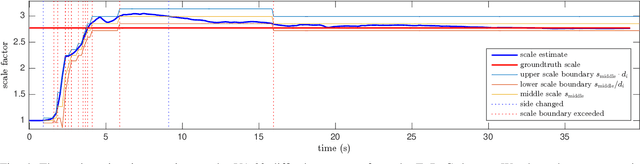
We present VI-DSO, a novel approach for visual-inertial odometry, which jointly estimates camera poses and sparse scene geometry by minimizing photometric and IMU measurement errors in a combined energy functional. The visual part of the system performs a bundle-adjustment like optimization on a sparse set of points, but unlike key-point based systems it directly minimizes a photometric error. This makes it possible for the system to track not only corners, but any pixels with large enough intensity gradients. IMU information is accumulated between several frames using measurement preintegration, and is inserted into the optimization as an additional constraint between keyframes. We explicitly include scale and gravity direction into our model and jointly optimize them together with other variables such as poses. As the scale is often not immediately observable using IMU data this allows us to initialize our visual-inertial system with an arbitrary scale instead of having to delay the initialization until everything is observable. We perform partial marginalization of old variables so that updates can be computed in a reasonable time. In order to keep the system consistent we propose a novel strategy which we call "dynamic marginalization". This technique allows us to use partial marginalization even in cases where the initial scale estimate is far from the optimum. We evaluate our method on the challenging EuRoC dataset, showing that VI-DSO outperforms the state of the art.
From Monocular SLAM to Autonomous Drone Exploration
Mar 12, 2018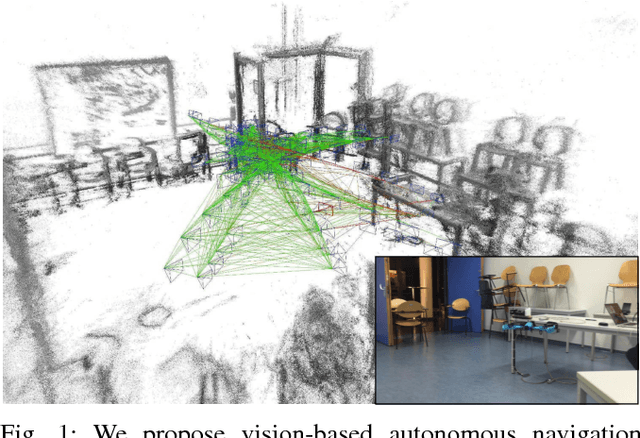



Micro aerial vehicles (MAVs) are strongly limited in their payload and power capacity. In order to implement autonomous navigation, algorithms are therefore desirable that use sensory equipment that is as small, low-weight, and low-power consuming as possible. In this paper, we propose a method for autonomous MAV navigation and exploration using a low-cost consumer-grade quadrocopter equipped with a monocular camera. Our vision-based navigation system builds on LSD-SLAM which estimates the MAV trajectory and a semi-dense reconstruction of the environment in real-time. Since LSD-SLAM only determines depth at high gradient pixels, texture-less areas are not directly observed so that previous exploration methods that assume dense map information cannot directly be applied. We propose an obstacle mapping and exploration approach that takes the properties of our semi-dense monocular SLAM system into account. In experiments, we demonstrate our vision-based autonomous navigation and exploration system with a Parrot Bebop MAV.