 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeodesicNVS: Probability Density Geodesic Flow Matching for Novel View Synthesis
Mar 01, 2026Recent advances in generative modeling have substantially enhanced novel view synthesis, yet maintaining consistency across viewpoints remains challenging. Diffusion-based models rely on stochastic noise-to-data transitions, which obscure deterministic structures and yield inconsistent view predictions. We propose a Data-to-Data Flow Matching framework that learns deterministic transformations directly between paired views, enhancing view-consistent synthesis through explicit data coupling. To further enhance geometric coherence, we introduce Probability Density Geodesic Flow Matching (PDG-FM), which constrains flow trajectories using geodesic interpolants derived from probability density metrics of pretrained diffusion models. Such alignment with high-density regions of the data manifold promotes more realistic interpolants between samples. Empirically, our method surpasses diffusion-based NVS baselines, demonstrating improved structural coherence and smoother transitions across views. These results highlight the advantages of incorporating data-dependent geometric regularization into deterministic flow matching for consistent novel view generation.
LADB: Latent Aligned Diffusion Bridges for Semi-Supervised Domain Translation
Sep 10, 2025Diffusion models excel at generating high-quality outputs but face challenges in data-scarce domains, where exhaustive retraining or costly paired data are often required. To address these limitations, we propose Latent Aligned Diffusion Bridges (LADB), a semi-supervised framework for sample-to-sample translation that effectively bridges domain gaps using partially paired data. By aligning source and target distributions within a shared latent space, LADB seamlessly integrates pretrained source-domain diffusion models with a target-domain Latent Aligned Diffusion Model (LADM), trained on partially paired latent representations. This approach enables deterministic domain mapping without the need for full supervision. Compared to unpaired methods, which often lack controllability, and fully paired approaches that require large, domain-specific datasets, LADB strikes a balance between fidelity and diversity by leveraging a mixture of paired and unpaired latent-target couplings. Our experimental results demonstrate superior performance in depth-to-image translation under partial supervision. Furthermore, we extend LADB to handle multi-source translation (from depth maps and segmentation masks) and multi-target translation in a class-conditioned style transfer task, showcasing its versatility in handling diverse and heterogeneous use cases. Ultimately, we present LADB as a scalable and versatile solution for real-world domain translation, particularly in scenarios where data annotation is costly or incomplete.
HI-SLAM2: Geometry-Aware Gaussian SLAM for Fast Monocular Scene Reconstruction
Nov 27, 2024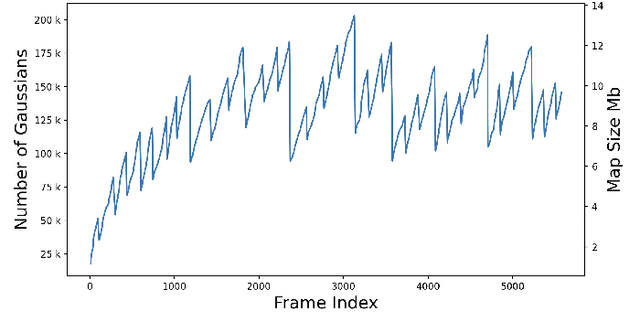
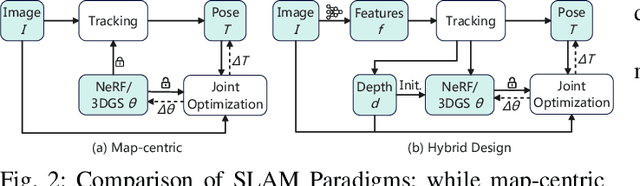
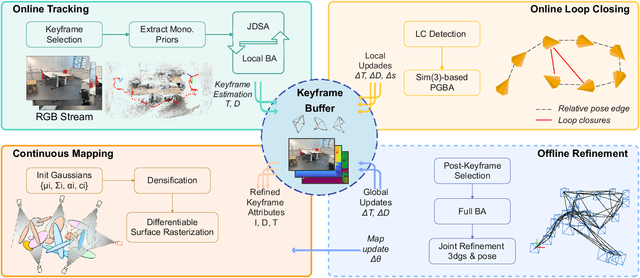
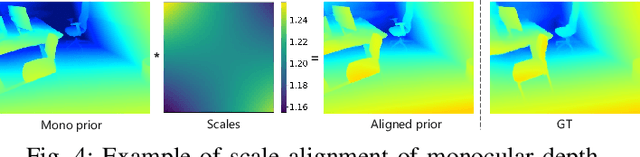
We present HI-SLAM2, a geometry-aware Gaussian SLAM system that achieves fast and accurate monocular scene reconstruction using only RGB input. Existing Neural SLAM or 3DGS-based SLAM methods often trade off between rendering quality and geometry accuracy, our research demonstrates that both can be achieved simultaneously with RGB input alone. The key idea of our approach is to enhance the ability for geometry estimation by combining easy-to-obtain monocular priors with learning-based dense SLAM, and then using 3D Gaussian splatting as our core map representation to efficiently model the scene. Upon loop closure, our method ensures on-the-fly global consistency through efficient pose graph bundle adjustment and instant map updates by explicitly deforming the 3D Gaussian units based on anchored keyframe updates. Furthermore, we introduce a grid-based scale alignment strategy to maintain improved scale consistency in prior depths for finer depth details. Through extensive experiments on Replica, ScanNet, and ScanNet++, we demonstrate significant improvements over existing Neural SLAM methods and even surpass RGB-D-based methods in both reconstruction and rendering quality. The project page and source code will be made available at https://hi-slam2.github.io/.
LiFCal: Online Light Field Camera Calibration via Bundle Adjustment
Aug 21, 2024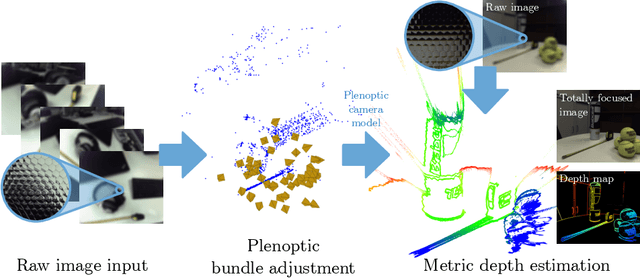
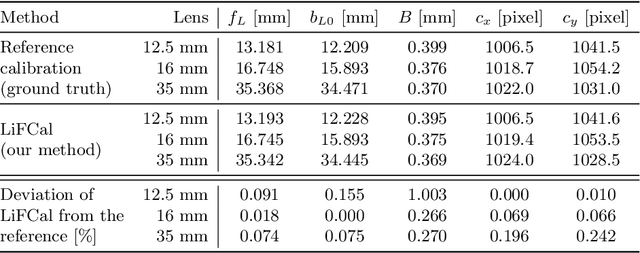
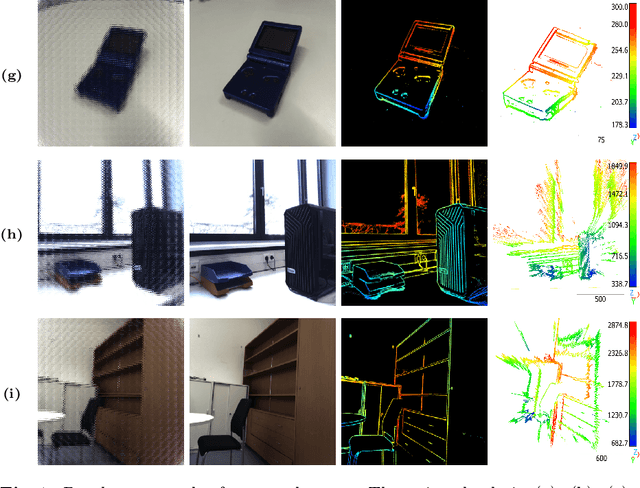

We propose LiFCal, a novel geometric online calibration pipeline for MLA-based light field cameras. LiFCal accurately determines model parameters from a moving camera sequence without precise calibration targets, integrating arbitrary metric scaling constraints. It optimizes intrinsic parameters of the light field camera model, the 3D coordinates of a sparse set of scene points and camera poses in a single bundle adjustment defined directly on micro image points. We show that LiFCal can reliably and repeatably calibrate a focused plenoptic camera using different input sequences, providing intrinsic camera parameters extremely close to state-of-the-art methods, while offering two main advantages: it can be applied in a target-free scene, and it is implemented online in a complete and continuous pipeline. Furthermore, we demonstrate the quality of the obtained camera parameters in downstream tasks like depth estimation and SLAM. Webpage: https://lifcal.github.io/
Semidefinite Relaxations for Robust Multiview Triangulation
Jan 26, 2023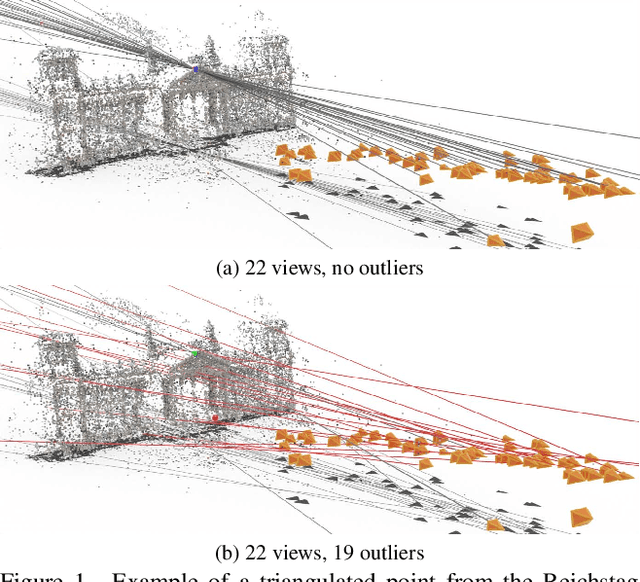

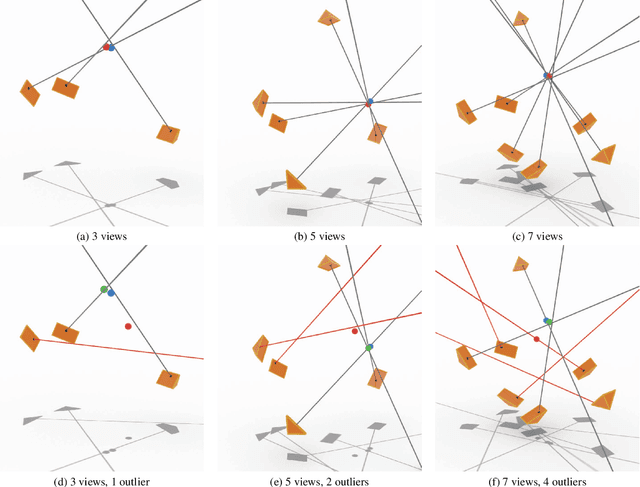
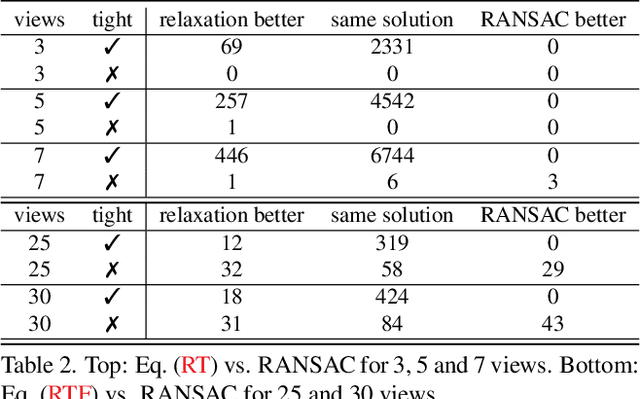
We propose the first convex relaxation for multiview triangulation that is robust to both noise and outliers. To this end, we extend existing semidefinite relaxation approaches to loss functions that include a truncated least squares cost to account for outliers. We propose two formulations, one based on epipolar constraints and one based on the fractional reprojection equations. The first is lower dimensional and remains tight under moderate noise and outlier levels, while the second is higher dimensional and therefore slower but remains tight even under extreme noise and outlier levels. We demonstrate through extensive experiments that the proposed approach allows us to compute provably optimal reconstructions and that empirically the relaxations remain tight even under significant noise and a large percentage of outliers.
4Seasons: Benchmarking Visual SLAM and Long-Term Localization for Autonomous Driving in Challenging Conditions
Dec 31, 2022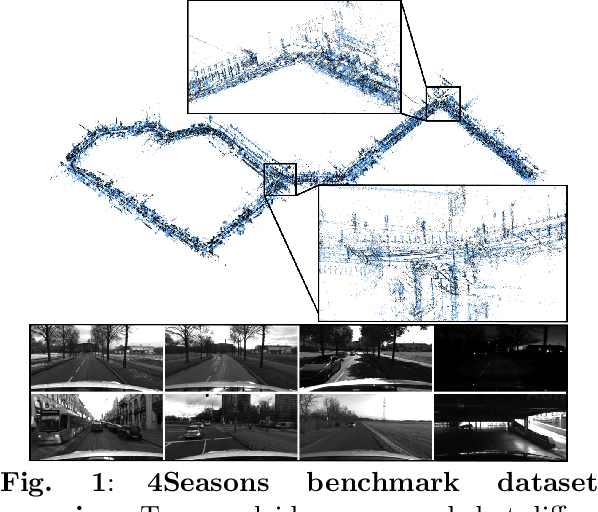
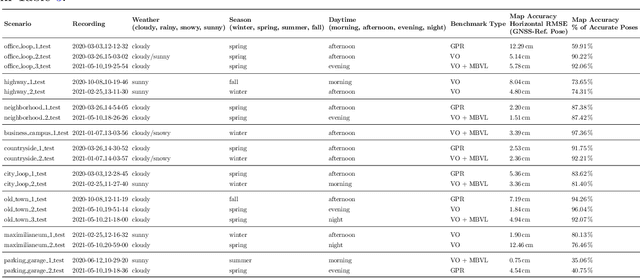

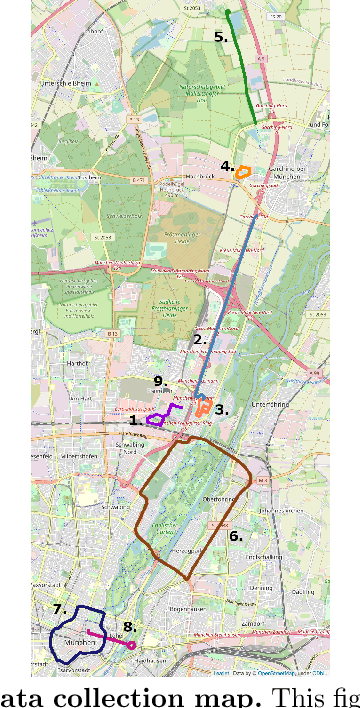
In this paper, we present a novel visual SLAM and long-term localization benchmark for autonomous driving in challenging conditions based on the large-scale 4Seasons dataset. The proposed benchmark provides drastic appearance variations caused by seasonal changes and diverse weather and illumination conditions. While significant progress has been made in advancing visual SLAM on small-scale datasets with similar conditions, there is still a lack of unified benchmarks representative of real-world scenarios for autonomous driving. We introduce a new unified benchmark for jointly evaluating visual odometry, global place recognition, and map-based visual localization performance which is crucial to successfully enable autonomous driving in any condition. The data has been collected for more than one year, resulting in more than 300 km of recordings in nine different environments ranging from a multi-level parking garage to urban (including tunnels) to countryside and highway. We provide globally consistent reference poses with up to centimeter-level accuracy obtained from the fusion of direct stereo-inertial odometry with RTK GNSS. We evaluate the performance of several state-of-the-art visual odometry and visual localization baseline approaches on the benchmark and analyze their properties. The experimental results provide new insights into current approaches and show promising potential for future research. Our benchmark and evaluation protocols will be available at https://www.4seasons-dataset.com/.
Vision-based Large-scale 3D Semantic Mapping for Autonomous Driving Applications
Mar 02, 2022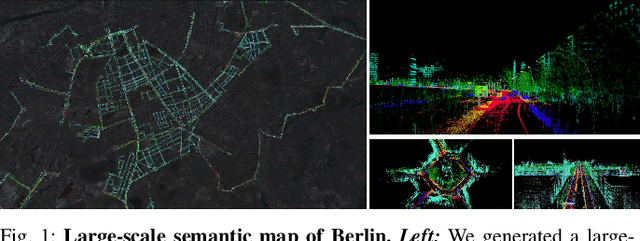
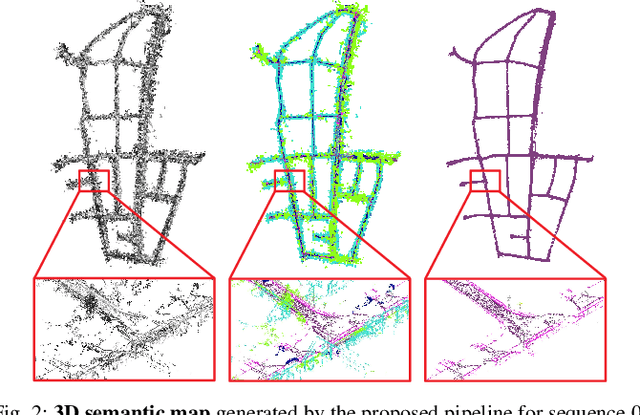
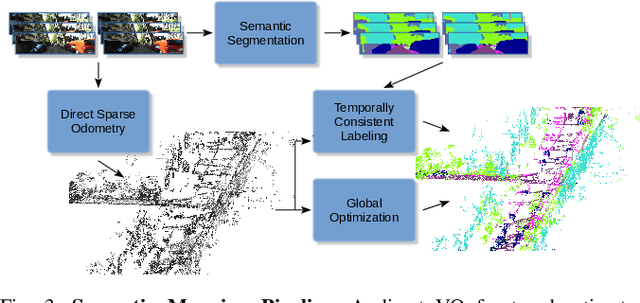
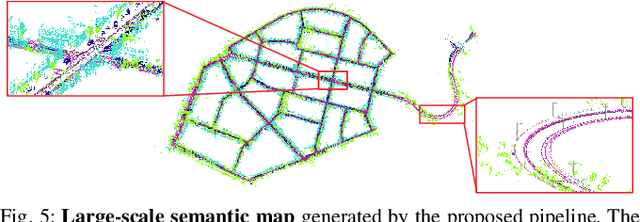
In this paper, we present a complete pipeline for 3D semantic mapping solely based on a stereo camera system. The pipeline comprises a direct sparse visual odometry front-end as well as a back-end for global optimization including GNSS integration, and semantic 3D point cloud labeling. We propose a simple but effective temporal voting scheme which improves the quality and consistency of the 3D point labels. Qualitative and quantitative evaluations of our pipeline are performed on the KITTI-360 dataset. The results show the effectiveness of our proposed voting scheme and the capability of our pipeline for efficient large-scale 3D semantic mapping. The large-scale mapping capabilities of our pipeline is furthermore demonstrated by presenting a very large-scale semantic map covering 8000 km of roads generated from data collected by a fleet of vehicles.
TANDEM: Tracking and Dense Mapping in Real-time using Deep Multi-view Stereo
Nov 14, 2021

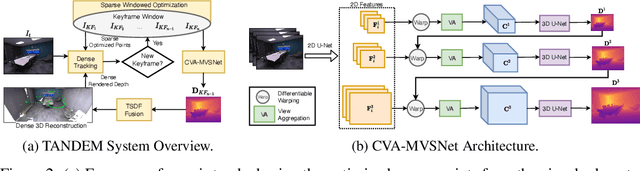
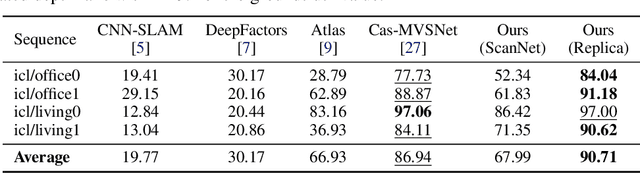
In this paper, we present TANDEM a real-time monocular tracking and dense mapping framework. For pose estimation, TANDEM performs photometric bundle adjustment based on a sliding window of keyframes. To increase the robustness, we propose a novel tracking front-end that performs dense direct image alignment using depth maps rendered from a global model that is built incrementally from dense depth predictions. To predict the dense depth maps, we propose Cascade View-Aggregation MVSNet (CVA-MVSNet) that utilizes the entire active keyframe window by hierarchically constructing 3D cost volumes with adaptive view aggregation to balance the different stereo baselines between the keyframes. Finally, the predicted depth maps are fused into a consistent global map represented as a truncated signed distance function (TSDF) voxel grid. Our experimental results show that TANDEM outperforms other state-of-the-art traditional and learning-based monocular visual odometry (VO) methods in terms of camera tracking. Moreover, TANDEM shows state-of-the-art real-time 3D reconstruction performance.
Tight Integration of Feature-Based Relocalization in Monocular Direct Visual Odometry
Feb 08, 2021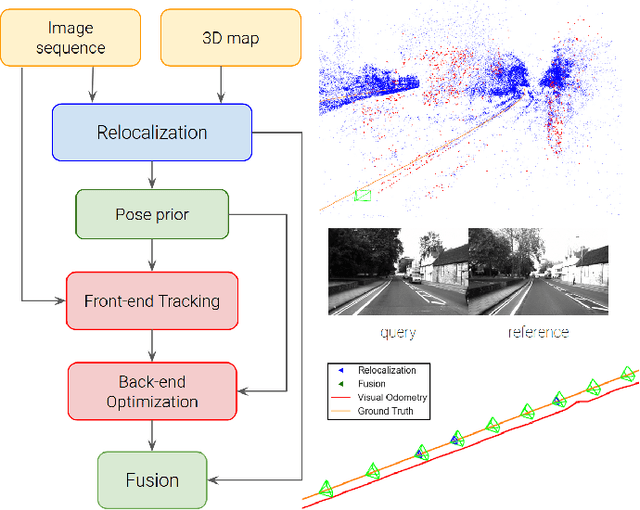
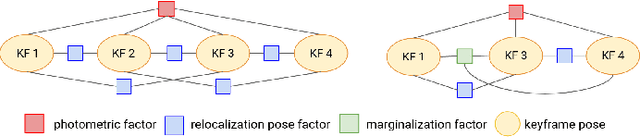
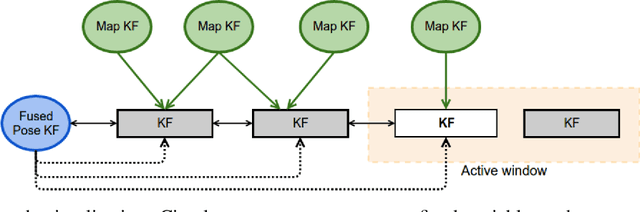
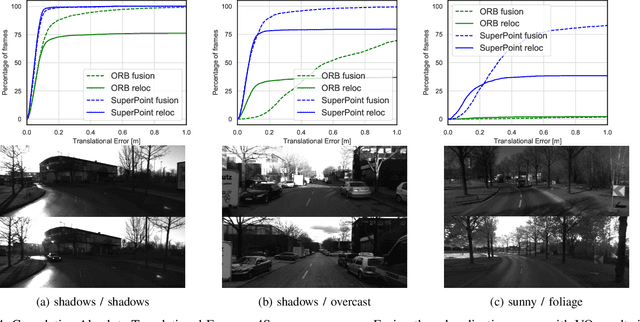
In this paper we propose a framework for integrating map-based relocalization into online direct visual odometry. To achieve map-based relocalization for direct methods, we integrate image features into Direct Sparse Odometry (DSO) and rely on feature matching to associate online visual odometry (VO) with a previously built map. The integration of the relocalization poses is threefold. Firstly, they are treated as pose priors and tightly integrated into the direct image alignment of the front-end tracking. Secondly, they are also tightly integrated into the back-end bundle adjustment. An online fusion module is further proposed to combine relative VO poses and global relocalization poses in a pose graph to estimate keyframe-wise smooth and globally accurate poses. We evaluate our method on two multi-weather datasets showing the benefits of integrating different handcrafted and learned features and demonstrating promising improvements on camera tracking accuracy.
MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera
Nov 24, 2020
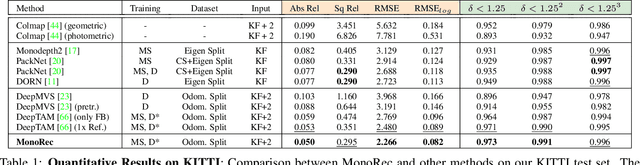
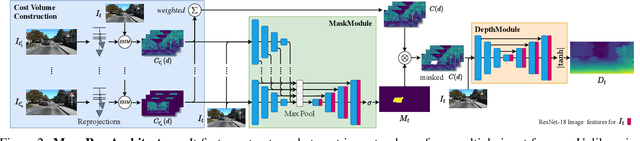

In this paper, we propose MonoRec, a semi-supervised monocular dense reconstruction architecture that predicts depth maps from a single moving camera in dynamic environments. MonoRec is based on a MVS setting which encodes the information of multiple consecutive images in a cost volume. To deal with dynamic objects in the scene, we introduce a MaskModule that predicts moving object masks by leveraging the photometric inconsistencies encoded in the cost volumes. Unlike other MVS methods, MonoRec is able to predict accurate depths for both static and moving objects by leveraging the predicted masks. Furthermore, we present a novel multi-stage training scheme with a semi-supervised loss formulation that does not require LiDAR depth values. We carefully evaluate MonoRec on the KITTI dataset and show that it achieves state-of-the-art performance compared to both multi-view and single-view methods. With the model trained on KITTI, we further demonstrate that MonoRec is able to generalize well to both the Oxford RobotCar dataset and the more challenging TUM-Mono dataset recorded by a handheld camera. Training code and pre-trained model will be published soon.