 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Event Visual Odometry
Dec 15, 2023



Event cameras offer the exciting possibility of tracking the camera's pose during high-speed motion and in adverse lighting conditions. Despite this promise, existing event-based monocular visual odometry (VO) approaches demonstrate limited performance on recent benchmarks. To address this limitation, some methods resort to additional sensors such as IMUs, stereo event cameras, or frame-based cameras. Nonetheless, these additional sensors limit the application of event cameras in real-world devices since they increase cost and complicate system requirements. Moreover, relying on a frame-based camera makes the system susceptible to motion blur and HDR. To remove the dependency on additional sensors and to push the limits of using only a single event camera, we present Deep Event VO (DEVO), the first monocular event-only system with strong performance on a large number of real-world benchmarks. DEVO sparsely tracks selected event patches over time. A key component of DEVO is a novel deep patch selection mechanism tailored to event data. We significantly decrease the pose tracking error on seven real-world benchmarks by up to 97% compared to event-only methods and often surpass or are close to stereo or inertial methods. Code is available at https://github.com/tum-vision/DEVO
Learning Correspondence Uncertainty via Differentiable Nonlinear Least Squares
May 18, 2023We propose a differentiable nonlinear least squares framework to account for uncertainty in relative pose estimation from feature correspondences. Specifically, we introduce a symmetric version of the probabilistic normal epipolar constraint, and an approach to estimate the covariance of feature positions by differentiating through the camera pose estimation procedure. We evaluate our approach on synthetic, as well as the KITTI and EuRoC real-world datasets. On the synthetic dataset, we confirm that our learned covariances accurately approximate the true noise distribution. In real world experiments, we find that our approach consistently outperforms state-of-the-art non-probabilistic and probabilistic approaches, regardless of the feature extraction algorithm of choice.
Masked Event Modeling: Self-Supervised Pretraining for Event Cameras
Dec 20, 2022Event cameras offer the capacity to asynchronously capture brightness changes with low latency, high temporal resolution, and high dynamic range. Deploying deep learning methods for classification or other tasks to these sensors typically requires large labeled datasets. Since the amount of labeled event data is tiny compared to the bulk of labeled RGB imagery, the progress of event-based vision has remained limited. To reduce the dependency on labeled event data, we introduce Masked Event Modeling (MEM), a self-supervised pretraining framework for events. Our method pretrains a neural network on unlabeled events, which can originate from any event camera recording. Subsequently, the pretrained model is finetuned on a downstream task leading to an overall better performance while requiring fewer labels. Our method outperforms the state-of-the-art on N-ImageNet, N-Cars, and N-Caltech101, increasing the object classification accuracy on N-ImageNet by 7.96%. We demonstrate that Masked Event Modeling is superior to RGB-based pretraining on a real world dataset.
E-NeRF: Neural Radiance Fields from a Moving Event Camera
Aug 24, 2022
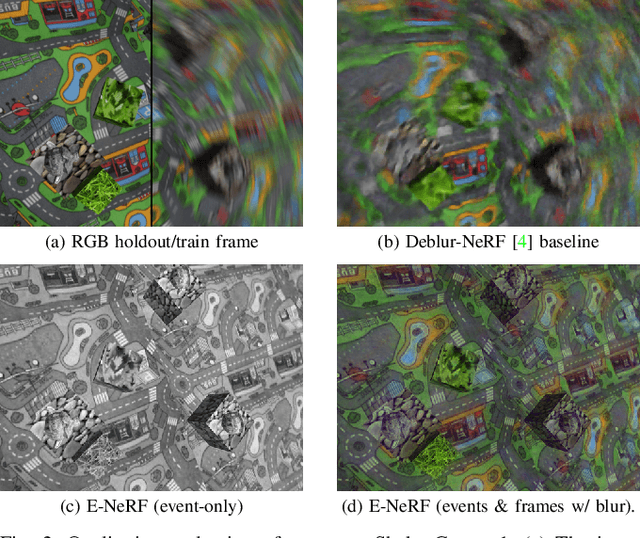


Estimating neural radiance fields (NeRFs) from ideal images has been extensively studied in the computer vision community. Most approaches assume optimal illumination and slow camera motion. These assumptions are often violated in robotic applications, where images contain motion blur and the scene may not have suitable illumination. This can cause significant problems for downstream tasks such as navigation, inspection or visualization of the scene. To alleviate these problems we present E-NeRF, the first method which estimates a volumetric scene representation in the form of a NeRF from a fast-moving event camera. Our method can recover NeRFs during very fast motion and in high dynamic range conditions, where frame-based approaches fail. We show that rendering high-quality frames is possible by only providing an event stream as input. Furthermore, by combining events and frames, we can estimate NeRFs of higher quality than state-of-the-art approaches under severe motion blur. We also show that combining events and frames can overcome failure cases of NeRF estimation in scenarios where only few input views are available, without requiring additional regularization.
Neural Implicit Representations for Physical Parameter Inference from a Single Video
Apr 29, 2022
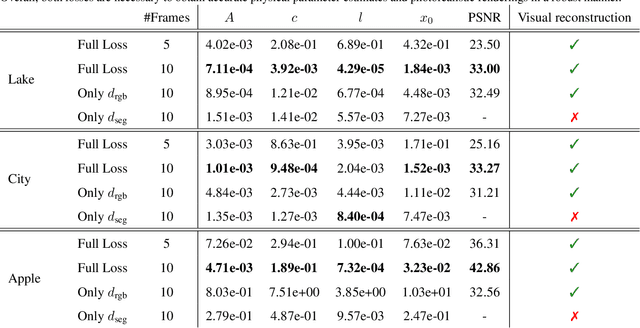
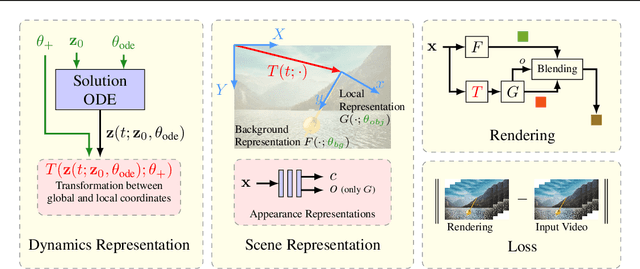

Neural networks have recently been used to analyze diverse physical systems and to identify the underlying dynamics. While existing methods achieve impressive results, they are limited by their strong demand for training data and their weak generalization abilities to out-of-distribution data. To overcome these limitations, in this work we propose to combine neural implicit representations for appearance modeling with neural ordinary differential equations (ODEs) for modelling physical phenomena to obtain a dynamic scene representation that can be identified directly from visual observations. Our proposed model combines several unique advantages: (i) Contrary to existing approaches that require large training datasets, we are able to identify physical parameters from only a single video. (ii) The use of neural implicit representations enables the processing of high-resolution videos and the synthesis of photo-realistic images. (iii) The embedded neural ODE has a known parametric form that allows for the identification of interpretable physical parameters, and (iv) long-term prediction in state space. (v) Furthermore, the photo-realistic rendering of novel scenes with modified physical parameters becomes possible.
The Probabilistic Normal Epipolar Constraint for Frame-To-Frame Rotation Optimization under Uncertain Feature Positions
Apr 05, 2022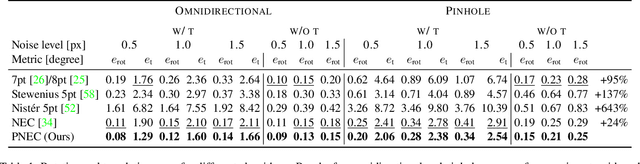

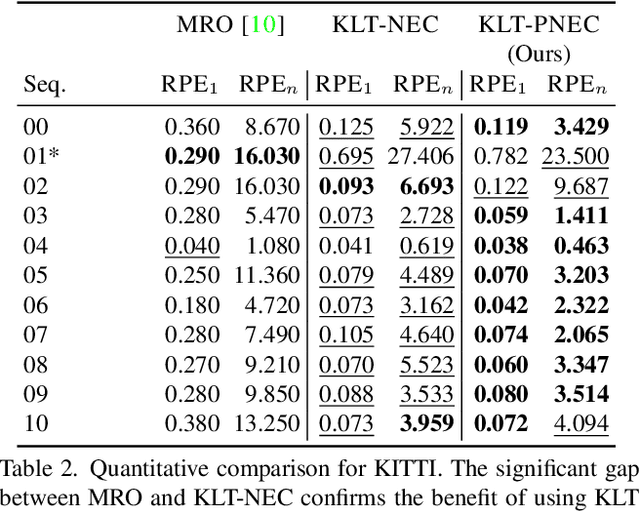
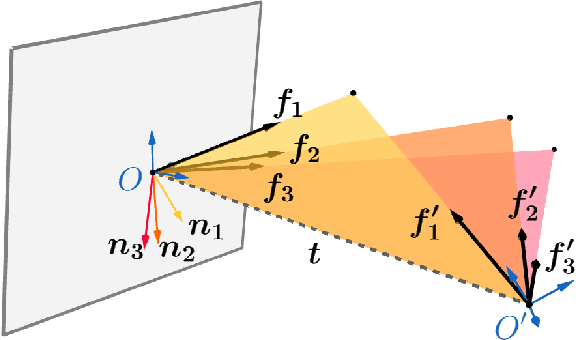
The estimation of the relative pose of two camera views is a fundamental problem in computer vision. Kneip et al. proposed to solve this problem by introducing the normal epipolar constraint (NEC). However, their approach does not take into account uncertainties, so that the accuracy of the estimated relative pose is highly dependent on accurate feature positions in the target frame. In this work, we introduce the probabilistic normal epipolar constraint (PNEC) that overcomes this limitation by accounting for anisotropic and inhomogeneous uncertainties in the feature positions. To this end, we propose a novel objective function, along with an efficient optimization scheme that effectively minimizes our objective while maintaining real-time performance. In experiments on synthetic data, we demonstrate that the novel PNEC yields more accurate rotation estimates than the original NEC and several popular relative rotation estimation algorithms. Furthermore, we integrate the proposed method into a state-of-the-art monocular rotation-only odometry system and achieve consistently improved results for the real-world KITTI dataset.
Intrinsic Neural Fields: Learning Functions on Manifolds
Mar 23, 2022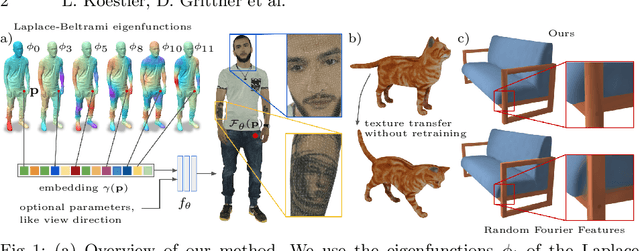
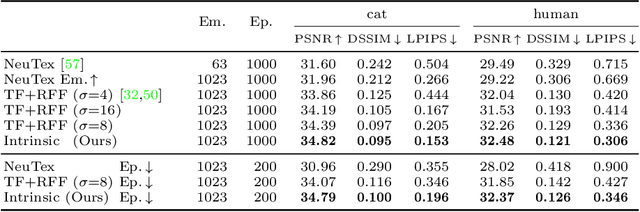
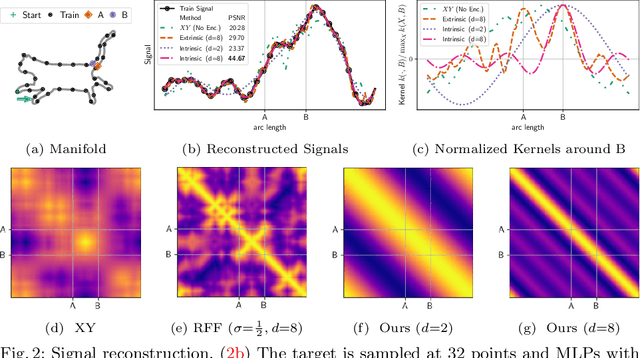
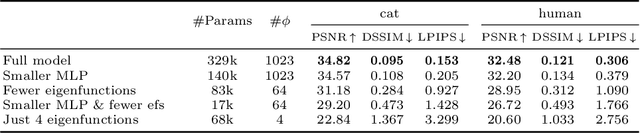
Neural fields have gained significant attention in the computer vision community due to their excellent performance in novel view synthesis, geometry reconstruction, and generative modeling. Some of their advantages are a sound theoretic foundation and an easy implementation in current deep learning frameworks. While neural fields have been applied to signals on manifolds, e.g., for texture reconstruction, their representation has been limited to extrinsically embedding the shape into Euclidean space. The extrinsic embedding ignores known intrinsic manifold properties and is inflexible wrt. transfer of the learned function. To overcome these limitations, this work introduces intrinsic neural fields, a novel and versatile representation for neural fields on manifolds. Intrinsic neural fields combine the advantages of neural fields with the spectral properties of the Laplace-Beltrami operator. We show theoretically that intrinsic neural fields inherit many desirable properties of the extrinsic neural field framework but exhibit additional intrinsic qualities, like isometry invariance. In experiments, we show intrinsic neural fields can reconstruct high-fidelity textures from images with state-of-the-art quality and are robust to the discretization of the underlying manifold. We demonstrate the versatility of intrinsic neural fields by tackling various applications: texture transfer between deformed shapes & different shapes, texture reconstruction from real-world images with view dependence, and discretization-agnostic learning on meshes and point clouds.
TANDEM: Tracking and Dense Mapping in Real-time using Deep Multi-view Stereo
Nov 14, 2021

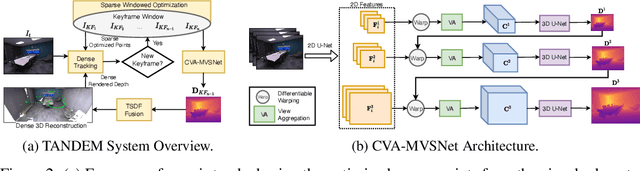
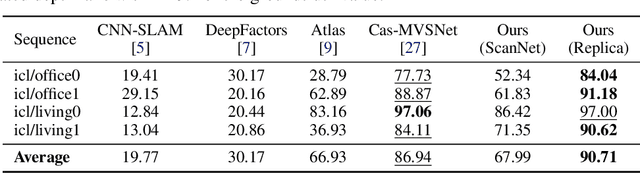
In this paper, we present TANDEM a real-time monocular tracking and dense mapping framework. For pose estimation, TANDEM performs photometric bundle adjustment based on a sliding window of keyframes. To increase the robustness, we propose a novel tracking front-end that performs dense direct image alignment using depth maps rendered from a global model that is built incrementally from dense depth predictions. To predict the dense depth maps, we propose Cascade View-Aggregation MVSNet (CVA-MVSNet) that utilizes the entire active keyframe window by hierarchically constructing 3D cost volumes with adaptive view aggregation to balance the different stereo baselines between the keyframes. Finally, the predicted depth maps are fused into a consistent global map represented as a truncated signed distance function (TSDF) voxel grid. Our experimental results show that TANDEM outperforms other state-of-the-art traditional and learning-based monocular visual odometry (VO) methods in terms of camera tracking. Moreover, TANDEM shows state-of-the-art real-time 3D reconstruction performance.