 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAMOND-SSS: Diffusion-Augmented Multi-View Optimization for Data-efficient SubSurface Scattering
Jan 17, 2026Subsurface scattering (SSS) gives translucent materials -- such as wax, jade, marble, and skin -- their characteristic soft shadows, color bleeding, and diffuse glow. Modeling these effects in neural rendering remains challenging due to complex light transport and the need for densely captured multi-view, multi-light datasets (often more than 100 views and 112 OLATs). We present DIAMOND-SSS, a data-efficient framework for high-fidelity translucent reconstruction from extremely sparse supervision -- even as few as ten images. We fine-tune diffusion models for novel-view synthesis and relighting, conditioned on estimated geometry and trained on less than 7 percent of the dataset, producing photorealistic augmentations that can replace up to 95 percent of missing captures. To stabilize reconstruction under sparse or synthetic supervision, we introduce illumination-independent geometric priors: a multi-view silhouette consistency loss and a multi-view depth consistency loss. Across all sparsity regimes, DIAMOND-SSS achieves state-of-the-art quality in relightable Gaussian rendering, reducing real capture requirements by up to 90 percent compared to SSS-3DGS.
On Neural BRDFs: A Thorough Comparison of State-of-the-Art Approaches
Feb 21, 2025The bidirectional reflectance distribution function (BRDF) is an essential tool to capture the complex interaction of light and matter. Recently, several works have employed neural methods for BRDF modeling, following various strategies, ranging from utilizing existing parametric models to purely neural parametrizations. While all methods yield impressive results, a comprehensive comparison of the different approaches is missing in the literature. In this work, we present a thorough evaluation of several approaches, including results for qualitative and quantitative reconstruction quality and an analysis of reciprocity and energy conservation. Moreover, we propose two extensions that can be added to existing approaches: A novel additive combination strategy for neural BRDFs that split the reflectance into a diffuse and a specular part, and an input mapping that ensures reciprocity exactly by construction, while previous approaches only ensure it by soft constraints.
ZDySS -- Zero-Shot Dynamic Scene Stylization using Gaussian Splatting
Jan 07, 2025



Stylizing a dynamic scene based on an exemplar image is critical for various real-world applications, including gaming, filmmaking, and augmented and virtual reality. However, achieving consistent stylization across both spatial and temporal dimensions remains a significant challenge. Most existing methods are designed for static scenes and often require an optimization process for each style image, limiting their adaptability. We introduce ZDySS, a zero-shot stylization framework for dynamic scenes, allowing our model to generalize to previously unseen style images at inference. Our approach employs Gaussian splatting for scene representation, linking each Gaussian to a learned feature vector that renders a feature map for any given view and timestamp. By applying style transfer on the learned feature vectors instead of the rendered feature map, we enhance spatio-temporal consistency across frames. Our method demonstrates superior performance and coherence over state-of-the-art baselines in tests on real-world dynamic scenes, making it a robust solution for practical applications.
MeshFeat: Multi-Resolution Features for Neural Fields on Meshes
Jul 18, 2024



Parametric feature grid encodings have gained significant attention as an encoding approach for neural fields since they allow for much smaller MLPs, which significantly decreases the inference time of the models. In this work, we propose MeshFeat, a parametric feature encoding tailored to meshes, for which we adapt the idea of multi-resolution feature grids from Euclidean space. We start from the structure provided by the given vertex topology and use a mesh simplification algorithm to construct a multi-resolution feature representation directly on the mesh. The approach allows the usage of small MLPs for neural fields on meshes, and we show a significant speed-up compared to previous representations while maintaining comparable reconstruction quality for texture reconstruction and BRDF representation. Given its intrinsic coupling to the vertices, the method is particularly well-suited for representations on deforming meshes, making it a good fit for object animation.
Neural Implicit Representations for Physical Parameter Inference from a Single Video
Apr 29, 2022
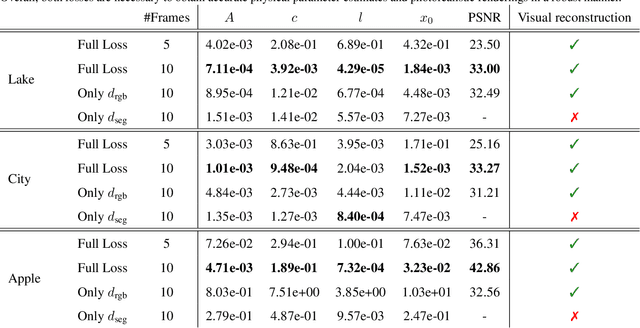
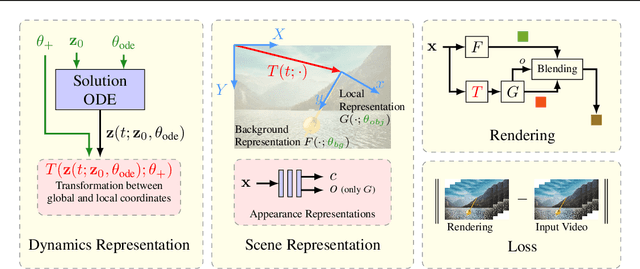

Neural networks have recently been used to analyze diverse physical systems and to identify the underlying dynamics. While existing methods achieve impressive results, they are limited by their strong demand for training data and their weak generalization abilities to out-of-distribution data. To overcome these limitations, in this work we propose to combine neural implicit representations for appearance modeling with neural ordinary differential equations (ODEs) for modelling physical phenomena to obtain a dynamic scene representation that can be identified directly from visual observations. Our proposed model combines several unique advantages: (i) Contrary to existing approaches that require large training datasets, we are able to identify physical parameters from only a single video. (ii) The use of neural implicit representations enables the processing of high-resolution videos and the synthesis of photo-realistic images. (iii) The embedded neural ODE has a known parametric form that allows for the identification of interpretable physical parameters, and (iv) long-term prediction in state space. (v) Furthermore, the photo-realistic rendering of novel scenes with modified physical parameters becomes possible.