 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype Augmented Hypernetworks for Continual Learning
May 13, 2025Continual learning (CL) aims to learn a sequence of tasks without forgetting prior knowledge, but gradient updates for a new task often overwrite the weights learned earlier, causing catastrophic forgetting (CF). We propose Prototype-Augmented Hypernetworks (PAH), a framework where a single hypernetwork, conditioned on learnable task prototypes, dynamically generates task-specific classifier heads on demand. To mitigate forgetting, PAH combines cross-entropy with dual distillation losses, one to align logits and another to align prototypes, ensuring stable feature representations across tasks. Evaluations on Split-CIFAR100 and TinyImageNet demonstrate that PAH achieves state-of-the-art performance, reaching 74.5 % and 63.7 % accuracy with only 1.7 % and 4.4 % forgetting, respectively, surpassing prior methods without storing samples or heads.
Nonisotropic Gaussian Diffusion for Realistic 3D Human Motion Prediction
Jan 10, 2025Probabilistic human motion prediction aims to forecast multiple possible future movements from past observations. While current approaches report high diversity and realism, they often generate motions with undetected limb stretching and jitter. To address this, we introduce SkeletonDiffusion, a latent diffusion model that embeds an explicit inductive bias on the human body within its architecture and training. Our model is trained with a novel nonisotropic Gaussian diffusion formulation that aligns with the natural kinematic structure of the human skeleton. Results show that our approach outperforms conventional isotropic alternatives, consistently generating realistic predictions while avoiding artifacts such as limb distortion. Additionally, we identify a limitation in commonly used diversity metrics, which may inadvertently favor models that produce inconsistent limb lengths within the same sequence. SkeletonDiffusion sets a new benchmark on three real-world datasets, outperforming various baselines across multiple evaluation metrics. Visit our project page: https://ceveloper.github.io/publications/skeletondiffusion/
ZDySS -- Zero-Shot Dynamic Scene Stylization using Gaussian Splatting
Jan 07, 2025



Stylizing a dynamic scene based on an exemplar image is critical for various real-world applications, including gaming, filmmaking, and augmented and virtual reality. However, achieving consistent stylization across both spatial and temporal dimensions remains a significant challenge. Most existing methods are designed for static scenes and often require an optimization process for each style image, limiting their adaptability. We introduce ZDySS, a zero-shot stylization framework for dynamic scenes, allowing our model to generalize to previously unseen style images at inference. Our approach employs Gaussian splatting for scene representation, linking each Gaussian to a learned feature vector that renders a feature map for any given view and timestamp. By applying style transfer on the learned feature vectors instead of the rendered feature map, we enhance spatio-temporal consistency across frames. Our method demonstrates superior performance and coherence over state-of-the-art baselines in tests on real-world dynamic scenes, making it a robust solution for practical applications.
Gaussian Splatting in Style
Mar 13, 2024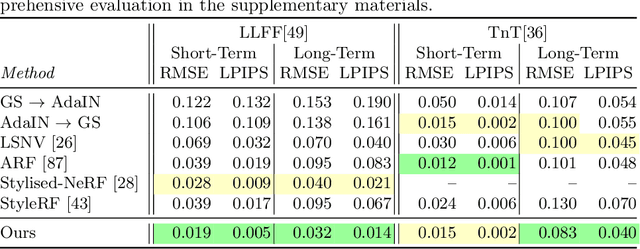


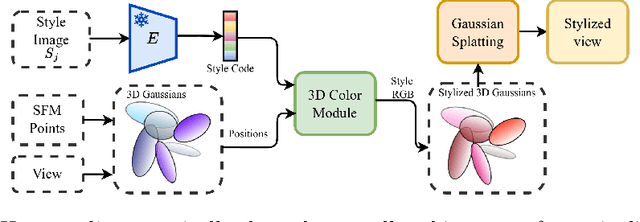
Scene stylization extends the work of neural style transfer to three spatial dimensions. A vital challenge in this problem is to maintain the uniformity of the stylized appearance across a multi-view setting. A vast majority of the previous works achieve this by optimizing the scene with a specific style image. In contrast, we propose a novel architecture trained on a collection of style images, that at test time produces high quality stylized novel views. Our work builds up on the framework of 3D Gaussian splatting. For a given scene, we take the pretrained Gaussians and process them using a multi resolution hash grid and a tiny MLP to obtain the conditional stylised views. The explicit nature of 3D Gaussians give us inherent advantages over NeRF-based methods including geometric consistency, along with having a fast training and rendering regime. This enables our method to be useful for vast practical use cases such as in augmented or virtual reality applications. Through our experiments, we show our methods achieve state-of-the-art performance with superior visual quality on various indoor and outdoor real-world data.