 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGECO: Geometrically Consistent Embedding with Lightspeed Inference
Aug 01, 2025Recent advances in feature learning have shown that self-supervised vision foundation models can capture semantic correspondences but often lack awareness of underlying 3D geometry. GECO addresses this gap by producing geometrically coherent features that semantically distinguish parts based on geometry (e.g., left/right eyes, front/back legs). We propose a training framework based on optimal transport, enabling supervision beyond keypoints, even under occlusions and disocclusions. With a lightweight architecture, GECO runs at 30 fps, 98.2% faster than prior methods, while achieving state-of-the-art performance on PFPascal, APK, and CUB, improving PCK by 6.0%, 6.2%, and 4.1%, respectively. Finally, we show that PCK alone is insufficient to capture geometric quality and introduce new metrics and insights for more geometry-aware feature learning. Link to project page: https://reginehartwig.github.io/publications/geco/
IPFormer: Visual 3D Panoptic Scene Completion with Context-Adaptive Instance Proposals
Jun 25, 2025Semantic Scene Completion (SSC) has emerged as a pivotal approach for jointly learning scene geometry and semantics, enabling downstream applications such as navigation in mobile robotics. The recent generalization to Panoptic Scene Completion (PSC) advances the SSC domain by integrating instance-level information, thereby enhancing object-level sensitivity in scene understanding. While PSC was introduced using LiDAR modality, methods based on camera images remain largely unexplored. Moreover, recent Transformer-based SSC approaches utilize a fixed set of learned queries to reconstruct objects within the scene volume. Although these queries are typically updated with image context during training, they remain static at test time, limiting their ability to dynamically adapt specifically to the observed scene. To overcome these limitations, we propose IPFormer, the first approach that leverages context-adaptive instance proposals at train and test time to address vision-based 3D Panoptic Scene Completion. Specifically, IPFormer adaptively initializes these queries as panoptic instance proposals derived from image context and further refines them through attention-based encoding and decoding to reason about semantic instance-voxel relationships. Experimental results show that our approach surpasses state-of-the-art methods in overall panoptic metrics PQ$^\dagger$ and PQ-All, matches performance in individual metrics, and achieves a runtime reduction exceeding 14$\times$. Furthermore, our ablation studies reveal that dynamically deriving instance proposals from image context, as opposed to random initialization, leads to a 3.62% increase in PQ-All and a remarkable average improvement of 18.65% in combined Thing-metrics. These results highlight our introduction of context-adaptive instance proposals as a pioneering effort in addressing vision-based 3D Panoptic Scene Completion.
AnyCam: Learning to Recover Camera Poses and Intrinsics from Casual Videos
Mar 30, 2025Estimating camera motion and intrinsics from casual videos is a core challenge in computer vision. Traditional bundle-adjustment based methods, such as SfM and SLAM, struggle to perform reliably on arbitrary data. Although specialized SfM approaches have been developed for handling dynamic scenes, they either require intrinsics or computationally expensive test-time optimization and often fall short in performance. Recently, methods like Dust3r have reformulated the SfM problem in a more data-driven way. While such techniques show promising results, they are still 1) not robust towards dynamic objects and 2) require labeled data for supervised training. As an alternative, we propose AnyCam, a fast transformer model that directly estimates camera poses and intrinsics from a dynamic video sequence in feed-forward fashion. Our intuition is that such a network can learn strong priors over realistic camera poses. To scale up our training, we rely on an uncertainty-based loss formulation and pre-trained depth and flow networks instead of motion or trajectory supervision. This allows us to use diverse, unlabelled video datasets obtained mostly from YouTube. Additionally, we ensure that the predicted trajectory does not accumulate drift over time through a lightweight trajectory refinement step. We test AnyCam on established datasets, where it delivers accurate camera poses and intrinsics both qualitatively and quantitatively. Furthermore, even with trajectory refinement, AnyCam is significantly faster than existing works for SfM in dynamic settings. Finally, by combining camera information, uncertainty, and depth, our model can produce high-quality 4D pointclouds.
Nonisotropic Gaussian Diffusion for Realistic 3D Human Motion Prediction
Jan 10, 2025Probabilistic human motion prediction aims to forecast multiple possible future movements from past observations. While current approaches report high diversity and realism, they often generate motions with undetected limb stretching and jitter. To address this, we introduce SkeletonDiffusion, a latent diffusion model that embeds an explicit inductive bias on the human body within its architecture and training. Our model is trained with a novel nonisotropic Gaussian diffusion formulation that aligns with the natural kinematic structure of the human skeleton. Results show that our approach outperforms conventional isotropic alternatives, consistently generating realistic predictions while avoiding artifacts such as limb distortion. Additionally, we identify a limitation in commonly used diversity metrics, which may inadvertently favor models that produce inconsistent limb lengths within the same sequence. SkeletonDiffusion sets a new benchmark on three real-world datasets, outperforming various baselines across multiple evaluation metrics. Visit our project page: https://ceveloper.github.io/publications/skeletondiffusion/
Boosting Self-Supervision for Single-View Scene Completion via Knowledge Distillation
Apr 11, 2024
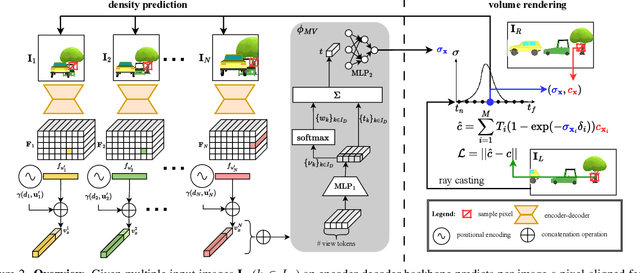

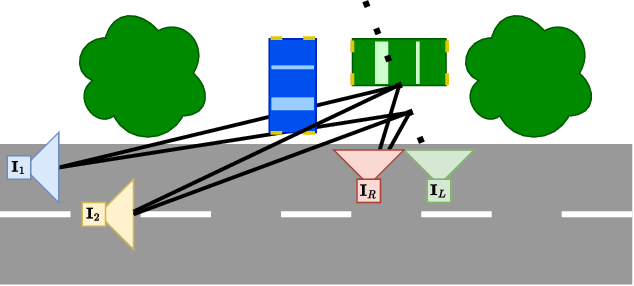
Inferring scene geometry from images via Structure from Motion is a long-standing and fundamental problem in computer vision. While classical approaches and, more recently, depth map predictions only focus on the visible parts of a scene, the task of scene completion aims to reason about geometry even in occluded regions. With the popularity of neural radiance fields (NeRFs), implicit representations also became popular for scene completion by predicting so-called density fields. Unlike explicit approaches. e.g. voxel-based methods, density fields also allow for accurate depth prediction and novel-view synthesis via image-based rendering. In this work, we propose to fuse the scene reconstruction from multiple images and distill this knowledge into a more accurate single-view scene reconstruction. To this end, we propose Multi-View Behind the Scenes (MVBTS) to fuse density fields from multiple posed images, trained fully self-supervised only from image data. Using knowledge distillation, we use MVBTS to train a single-view scene completion network via direct supervision called KDBTS. It achieves state-of-the-art performance on occupancy prediction, especially in occluded regions.
S4C: Self-Supervised Semantic Scene Completion with Neural Fields
Oct 12, 2023



3D semantic scene understanding is a fundamental challenge in computer vision. It enables mobile agents to autonomously plan and navigate arbitrary environments. SSC formalizes this challenge as jointly estimating dense geometry and semantic information from sparse observations of a scene. Current methods for SSC are generally trained on 3D ground truth based on aggregated LiDAR scans. This process relies on special sensors and annotation by hand which are costly and do not scale well. To overcome this issue, our work presents the first self-supervised approach to SSC called S4C that does not rely on 3D ground truth data. Our proposed method can reconstruct a scene from a single image and only relies on videos and pseudo segmentation ground truth generated from off-the-shelf image segmentation network during training. Unlike existing methods, which use discrete voxel grids, we represent scenes as implicit semantic fields. This formulation allows querying any point within the camera frustum for occupancy and semantic class. Our architecture is trained through rendering-based self-supervised losses. Nonetheless, our method achieves performance close to fully supervised state-of-the-art methods. Additionally, our method demonstrates strong generalization capabilities and can synthesize accurate segmentation maps for far away viewpoints.
Learning Correspondence Uncertainty via Differentiable Nonlinear Least Squares
May 18, 2023We propose a differentiable nonlinear least squares framework to account for uncertainty in relative pose estimation from feature correspondences. Specifically, we introduce a symmetric version of the probabilistic normal epipolar constraint, and an approach to estimate the covariance of feature positions by differentiating through the camera pose estimation procedure. We evaluate our approach on synthetic, as well as the KITTI and EuRoC real-world datasets. On the synthetic dataset, we confirm that our learned covariances accurately approximate the true noise distribution. In real world experiments, we find that our approach consistently outperforms state-of-the-art non-probabilistic and probabilistic approaches, regardless of the feature extraction algorithm of choice.
The Probabilistic Normal Epipolar Constraint for Frame-To-Frame Rotation Optimization under Uncertain Feature Positions
Apr 05, 2022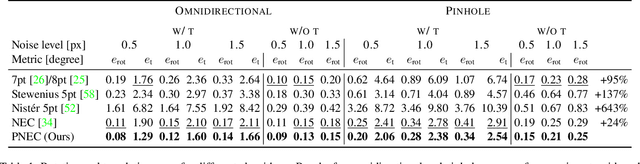

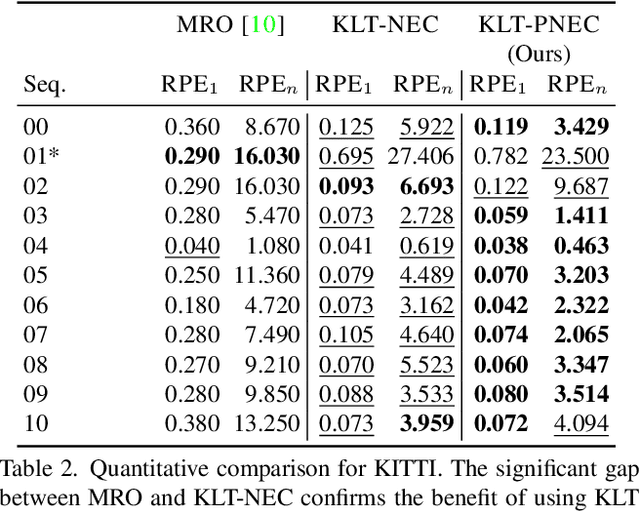
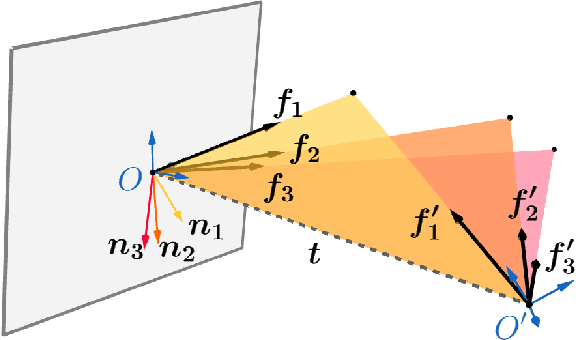
The estimation of the relative pose of two camera views is a fundamental problem in computer vision. Kneip et al. proposed to solve this problem by introducing the normal epipolar constraint (NEC). However, their approach does not take into account uncertainties, so that the accuracy of the estimated relative pose is highly dependent on accurate feature positions in the target frame. In this work, we introduce the probabilistic normal epipolar constraint (PNEC) that overcomes this limitation by accounting for anisotropic and inhomogeneous uncertainties in the feature positions. To this end, we propose a novel objective function, along with an efficient optimization scheme that effectively minimizes our objective while maintaining real-time performance. In experiments on synthetic data, we demonstrate that the novel PNEC yields more accurate rotation estimates than the original NEC and several popular relative rotation estimation algorithms. Furthermore, we integrate the proposed method into a state-of-the-art monocular rotation-only odometry system and achieve consistently improved results for the real-world KITTI dataset.