 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Rigid 3D Shape Correspondences: From Foundations to Open Challenges and Opportunities
Apr 01, 2026Estimating correspondences between deformed shape instances is a long-standing problem in computer graphics; numerous applications, from texture transfer to statistical modelling, rely on recovering an accurate correspondence map. Many methods have thus been proposed to tackle this challenging problem from varying perspectives, depending on the downstream application. This state-of-the-art report is geared towards researchers, practitioners, and students seeking to understand recent trends and advances in the field. We categorise developments into three paradigms: spectral methods based on functional maps, combinatorial formulations that impose discrete constraints, and deformation-based methods that directly recover a global alignment. Each school of thought offers different advantages and disadvantages, which we discuss throughout the report. Meanwhile, we highlight the latest developments in each area and suggest new potential research directions. Finally, we provide an overview of emerging challenges and opportunities in this growing field, including the recent use of vision foundation models for zero-shot correspondence and the particularly challenging task of matching partial shapes.
RINO: Rotation-Invariant Non-Rigid Correspondences
Mar 29, 2026Dense 3D shape correspondence remains a central challenge in computer vision and graphics as many deep learning approaches still rely on intermediate geometric features or handcrafted descriptors, limiting their effectiveness under non-isometric deformations, partial data, and non-manifold inputs. To overcome these issues, we introduce RINO, an unsupervised, rotation-invariant dense correspondence framework that effectively unifies rigid and non-rigid shape matching. The core of our method is the novel RINONet, a feature extractor that integrates vector-based SO(3)-invariant learning with orientation-aware complex functional maps to extract robust features directly from raw geometry. This allows for a fully end-to-end, data-driven approach that bypasses the need for shape pre-alignment or handcrafted features. Extensive experiments show unprecedented performance of RINO across challenging non-rigid matching tasks, including arbitrary poses, non-isometry, partiality, non-manifoldness, and noise.
* 17 pages, 36 Figures, Computer Vision and Pattern Recognition (CVPR) 2026
ECHO: Ego-Centric modeling of Human-Object interactions
Aug 29, 2025
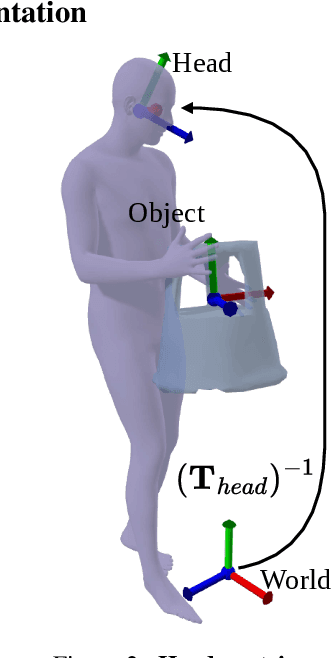
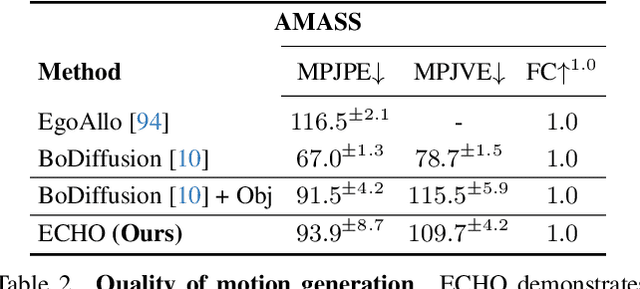
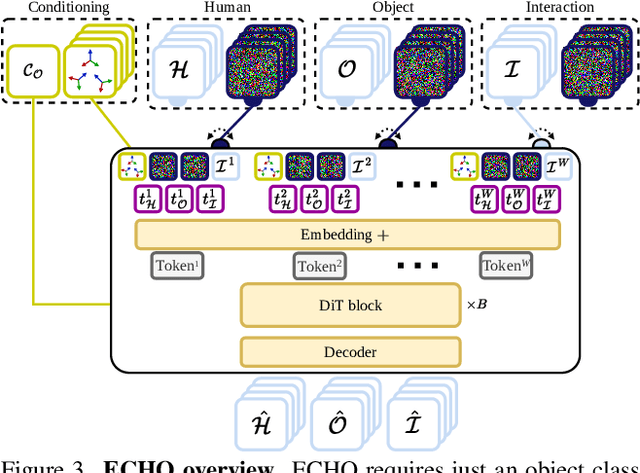
Modeling human-object interactions (HOI) from an egocentric perspective is a largely unexplored yet important problem due to the increasing adoption of wearable devices, such as smart glasses and watches. We investigate how much information about interaction can be recovered from only head and wrists tracking. Our answer is ECHO (Ego-Centric modeling of Human-Object interactions), which, for the first time, proposes a unified framework to recover three modalities: human pose, object motion, and contact from such minimal observation. ECHO employs a Diffusion Transformer architecture and a unique three-variate diffusion process, which jointly models human motion, object trajectory, and contact sequence, allowing for flexible input configurations. Our method operates in a head-centric canonical space, enhancing robustness to global orientation. We propose a conveyor-based inference, which progressively increases the diffusion timestamp with the frame position, allowing us to process sequences of any length. Through extensive evaluation, we demonstrate that ECHO outperforms existing methods that do not offer the same flexibility, setting a state-of-the-art in egocentric HOI reconstruction.
GECO: Geometrically Consistent Embedding with Lightspeed Inference
Aug 01, 2025Recent advances in feature learning have shown that self-supervised vision foundation models can capture semantic correspondences but often lack awareness of underlying 3D geometry. GECO addresses this gap by producing geometrically coherent features that semantically distinguish parts based on geometry (e.g., left/right eyes, front/back legs). We propose a training framework based on optimal transport, enabling supervision beyond keypoints, even under occlusions and disocclusions. With a lightweight architecture, GECO runs at 30 fps, 98.2% faster than prior methods, while achieving state-of-the-art performance on PFPascal, APK, and CUB, improving PCK by 6.0%, 6.2%, and 4.1%, respectively. Finally, we show that PCK alone is insufficient to capture geometric quality and introduce new metrics and insights for more geometry-aware feature learning. Link to project page: https://reginehartwig.github.io/publications/geco/
TwoSquared: 4D Generation from 2D Image Pairs
Apr 17, 2025



Despite the astonishing progress in generative AI, 4D dynamic object generation remains an open challenge. With limited high-quality training data and heavy computing requirements, the combination of hallucinating unseen geometry together with unseen movement poses great challenges to generative models. In this work, we propose TwoSquared as a method to obtain a 4D physically plausible sequence starting from only two 2D RGB images corresponding to the beginning and end of the action. Instead of directly solving the 4D generation problem, TwoSquared decomposes the problem into two steps: 1) an image-to-3D module generation based on the existing generative model trained on high-quality 3D assets, and 2) a physically inspired deformation module to predict intermediate movements. To this end, our method does not require templates or object-class-specific prior knowledge and can take in-the-wild images as input. In our experiments, we demonstrate that TwoSquared is capable of producing texture-consistent and geometry-consistent 4D sequences only given 2D images.
4Deform: Neural Surface Deformation for Robust Shape Interpolation
Feb 27, 2025Generating realistic intermediate shapes between non-rigidly deformed shapes is a challenging task in computer vision, especially with unstructured data (e.g., point clouds) where temporal consistency across frames is lacking, and topologies are changing. Most interpolation methods are designed for structured data (i.e., meshes) and do not apply to real-world point clouds. In contrast, our approach, 4Deform, leverages neural implicit representation (NIR) to enable free topology changing shape deformation. Unlike previous mesh-based methods that learn vertex-based deformation fields, our method learns a continuous velocity field in Euclidean space. Thus, it is suitable for less structured data such as point clouds. Additionally, our method does not require intermediate-shape supervision during training; instead, we incorporate physical and geometrical constraints to regularize the velocity field. We reconstruct intermediate surfaces using a modified level-set equation, directly linking our NIR with the velocity field. Experiments show that our method significantly outperforms previous NIR approaches across various scenarios (e.g., noisy, partial, topology-changing, non-isometric shapes) and, for the first time, enables new applications like 4D Kinect sequence upsampling and real-world high-resolution mesh deformation.
Nonisotropic Gaussian Diffusion for Realistic 3D Human Motion Prediction
Jan 10, 2025Probabilistic human motion prediction aims to forecast multiple possible future movements from past observations. While current approaches report high diversity and realism, they often generate motions with undetected limb stretching and jitter. To address this, we introduce SkeletonDiffusion, a latent diffusion model that embeds an explicit inductive bias on the human body within its architecture and training. Our model is trained with a novel nonisotropic Gaussian diffusion formulation that aligns with the natural kinematic structure of the human skeleton. Results show that our approach outperforms conventional isotropic alternatives, consistently generating realistic predictions while avoiding artifacts such as limb distortion. Additionally, we identify a limitation in commonly used diversity metrics, which may inadvertently favor models that produce inconsistent limb lengths within the same sequence. SkeletonDiffusion sets a new benchmark on three real-world datasets, outperforming various baselines across multiple evaluation metrics. Visit our project page: https://ceveloper.github.io/publications/skeletondiffusion/
TriDi: Trilateral Diffusion of 3D Humans, Objects, and Interactions
Dec 09, 2024Modeling 3D human-object interaction (HOI) is a problem of great interest for computer vision and a key enabler for virtual and mixed-reality applications. Existing methods work in a one-way direction: some recover plausible human interactions conditioned on a 3D object; others recover the object pose conditioned on a human pose. Instead, we provide the first unified model - TriDi which works in any direction. Concretely, we generate Human, Object, and Interaction modalities simultaneously with a new three-way diffusion process, allowing to model seven distributions with one network. We implement TriDi as a transformer attending to the various modalities' tokens, thereby discovering conditional relations between them. The user can control the interaction either as a text description of HOI or a contact map. We embed these two representations into a shared latent space, combining the practicality of text descriptions with the expressiveness of contact maps. Using a single network, TriDi unifies all the special cases of prior work and extends to new ones, modeling a family of seven distributions. Remarkably, despite using a single model, TriDi generated samples surpass one-way specialized baselines on GRAB and BEHAVE in terms of both qualitative and quantitative metrics, and demonstrating better diversity. We show the applicability of TriDi to scene population, generating objects for human-contact datasets, and generalization to unseen object geometry. The project page is available at: https://virtualhumans.mpi-inf.mpg.de/tridi.
Gen-3Diffusion: Realistic Image-to-3D Generation via 2D & 3D Diffusion Synergy
Dec 09, 2024Creating realistic 3D objects and clothed avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot guarantee the generated multi-view images are 3D consistent. In this paper, we propose Gen-3Diffusion: Realistic Image-to-3D Generation via 2D & 3D Diffusion Synergy. We leverage a pre-trained 2D diffusion model and a 3D diffusion model via our elegantly designed process that synchronizes two diffusion models at both training and sampling time. The synergy between the 2D and 3D diffusion models brings two major advantages: 1) 2D helps 3D in generalization: the pretrained 2D model has strong generalization ability to unseen images, providing strong shape priors for the 3D diffusion model; 2) 3D helps 2D in multi-view consistency: the 3D diffusion model enhances the 3D consistency of 2D multi-view sampling process, resulting in more accurate multi-view generation. We validate our idea through extensive experiments in image-based objects and clothed avatar generation tasks. Results show that our method generates realistic 3D objects and avatars with high-fidelity geometry and texture. Extensive ablations also validate our design choices and demonstrate the strong generalization ability to diverse clothing and compositional shapes. Our code and pretrained models will be publicly released on https://yuxuan-xue.com/gen-3diffusion.
Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
Jun 12, 2024Creating realistic avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other, and by coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the priors from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models will be released on https://yuxuan-xue.com/human-3diffusion.