 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastVMT: Eliminating Redundancy in Video Motion Transfer
Feb 05, 2026Video motion transfer aims to synthesize videos by generating visual content according to a text prompt while transferring the motion pattern observed in a reference video. Recent methods predominantly use the Diffusion Transformer (DiT) architecture. To achieve satisfactory runtime, several methods attempt to accelerate the computations in the DiT, but fail to address structural sources of inefficiency. In this work, we identify and remove two types of computational redundancy in earlier work: motion redundancy arises because the generic DiT architecture does not reflect the fact that frame-to-frame motion is small and smooth; gradient redundancy occurs if one ignores that gradients change slowly along the diffusion trajectory. To mitigate motion redundancy, we mask the corresponding attention layers to a local neighborhood such that interaction weights are not computed unnecessarily distant image regions. To exploit gradient redundancy, we design an optimization scheme that reuses gradients from previous diffusion steps and skips unwarranted gradient computations. On average, FastVMT achieves a 3.43x speedup without degrading the visual fidelity or the temporal consistency of the generated videos.
Gen-3Diffusion: Realistic Image-to-3D Generation via 2D & 3D Diffusion Synergy
Dec 09, 2024Creating realistic 3D objects and clothed avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot guarantee the generated multi-view images are 3D consistent. In this paper, we propose Gen-3Diffusion: Realistic Image-to-3D Generation via 2D & 3D Diffusion Synergy. We leverage a pre-trained 2D diffusion model and a 3D diffusion model via our elegantly designed process that synchronizes two diffusion models at both training and sampling time. The synergy between the 2D and 3D diffusion models brings two major advantages: 1) 2D helps 3D in generalization: the pretrained 2D model has strong generalization ability to unseen images, providing strong shape priors for the 3D diffusion model; 2) 3D helps 2D in multi-view consistency: the 3D diffusion model enhances the 3D consistency of 2D multi-view sampling process, resulting in more accurate multi-view generation. We validate our idea through extensive experiments in image-based objects and clothed avatar generation tasks. Results show that our method generates realistic 3D objects and avatars with high-fidelity geometry and texture. Extensive ablations also validate our design choices and demonstrate the strong generalization ability to diverse clothing and compositional shapes. Our code and pretrained models will be publicly released on https://yuxuan-xue.com/gen-3diffusion.
Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
Jun 12, 2024Creating realistic avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other, and by coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the priors from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models will be released on https://yuxuan-xue.com/human-3diffusion.
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Nov 10, 2023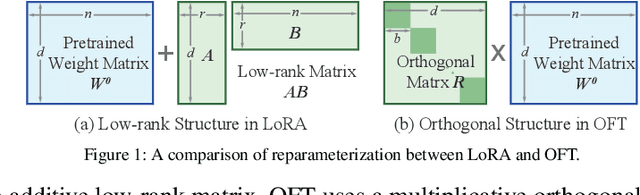
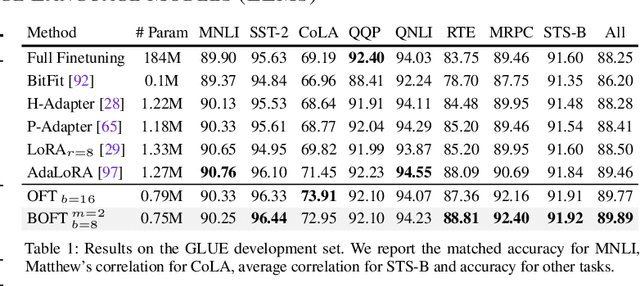
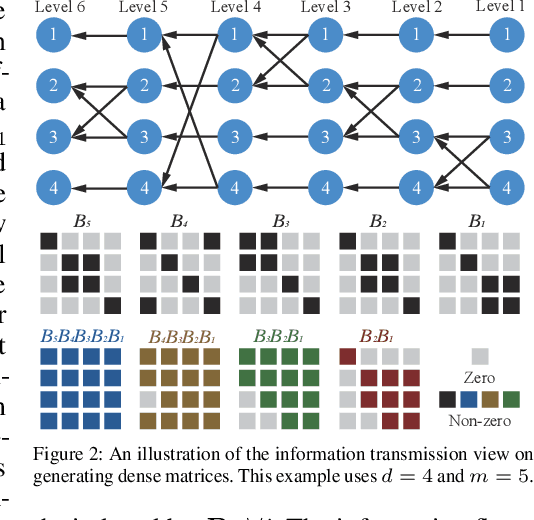
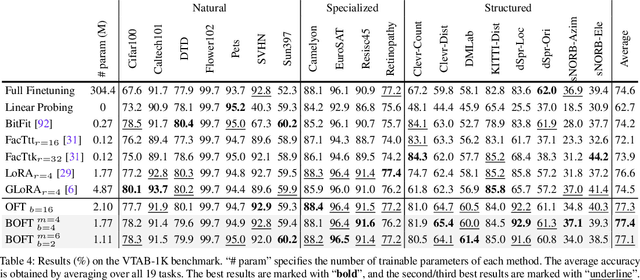
Large foundation models are becoming ubiquitous, but training them from scratch is prohibitively expensive. Thus, efficiently adapting these powerful models to downstream tasks is increasingly important. In this paper, we study a principled finetuning paradigm -- Orthogonal Finetuning (OFT) -- for downstream task adaptation. Despite demonstrating good generalizability, OFT still uses a fairly large number of trainable parameters due to the high dimensionality of orthogonal matrices. To address this, we start by examining OFT from an information transmission perspective, and then identify a few key desiderata that enable better parameter-efficiency. Inspired by how the Cooley-Tukey fast Fourier transform algorithm enables efficient information transmission, we propose an efficient orthogonal parameterization using butterfly structures. We apply this parameterization to OFT, creating a novel parameter-efficient finetuning method, called Orthogonal Butterfly (BOFT). By subsuming OFT as a special case, BOFT introduces a generalized orthogonal finetuning framework. Finally, we conduct an extensive empirical study of adapting large vision transformers, large language models, and text-to-image diffusion models to various downstream tasks in vision and language.
NSF: Neural Surface Fields for Human Modeling from Monocular Depth
Aug 30, 2023Obtaining personalized 3D animatable avatars from a monocular camera has several real world applications in gaming, virtual try-on, animation, and VR/XR, etc. However, it is very challenging to model dynamic and fine-grained clothing deformations from such sparse data. Existing methods for modeling 3D humans from depth data have limitations in terms of computational efficiency, mesh coherency, and flexibility in resolution and topology. For instance, reconstructing shapes using implicit functions and extracting explicit meshes per frame is computationally expensive and cannot ensure coherent meshes across frames. Moreover, predicting per-vertex deformations on a pre-designed human template with a discrete surface lacks flexibility in resolution and topology. To overcome these limitations, we propose a novel method `\keyfeature: Neural Surface Fields' for modeling 3D clothed humans from monocular depth. NSF defines a neural field solely on the base surface which models a continuous and flexible displacement field. NSF can be adapted to the base surface with different resolution and topology without retraining at inference time. Compared to existing approaches, our method eliminates the expensive per-frame surface extraction while maintaining mesh coherency, and is capable of reconstructing meshes with arbitrary resolution without retraining. To foster research in this direction, we release our code in project page at: https://yuxuan-xue.com/nsf.
Controlling Text-to-Image Diffusion by Orthogonal Finetuning
Jun 12, 2023Large text-to-image diffusion models have impressive capabilities in generating photorealistic images from text prompts. How to effectively guide or control these powerful models to perform different downstream tasks becomes an important open problem. To tackle this challenge, we introduce a principled finetuning method -- Orthogonal Finetuning (OFT), for adapting text-to-image diffusion models to downstream tasks. Unlike existing methods, OFT can provably preserve hyperspherical energy which characterizes the pairwise neuron relationship on the unit hypersphere. We find that this property is crucial for preserving the semantic generation ability of text-to-image diffusion models. To improve finetuning stability, we further propose Constrained Orthogonal Finetuning (COFT) which imposes an additional radius constraint to the hypersphere. Specifically, we consider two important finetuning text-to-image tasks: subject-driven generation where the goal is to generate subject-specific images given a few images of a subject and a text prompt, and controllable generation where the goal is to enable the model to take in additional control signals. We empirically show that our OFT framework outperforms existing methods in generation quality and convergence speed.
Event-based Non-Rigid Reconstruction from Contours
Oct 12, 2022



Visual reconstruction of fast non-rigid object deformations over time is a challenge for conventional frame-based cameras. In this paper, we propose a novel approach for reconstructing such deformations using measurements from event-based cameras. Under the assumption of a static background, where all events are generated by the motion, our approach estimates the deformation of objects from events generated at the object contour in a probabilistic optimization framework. It associates events to mesh faces on the contour and maximizes the alignment of the line of sight through the event pixel with the associated face. In experiments on synthetic and real data, we demonstrate the advantages of our method over state-of-the-art optimization and learning-based approaches for reconstructing the motion of human hands. A video of the experiments is available at https://youtu.be/gzfw7i5OKjg
Robust Event Detection based on Spatio-Temporal Latent Action Unit using Skeletal Information
Oct 01, 2021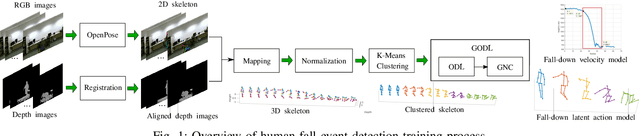
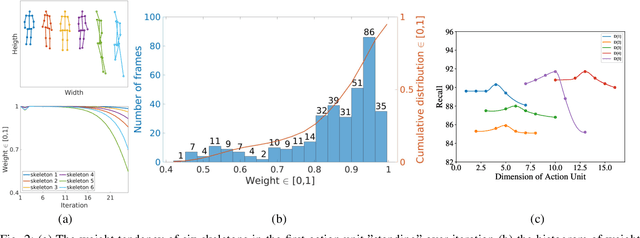
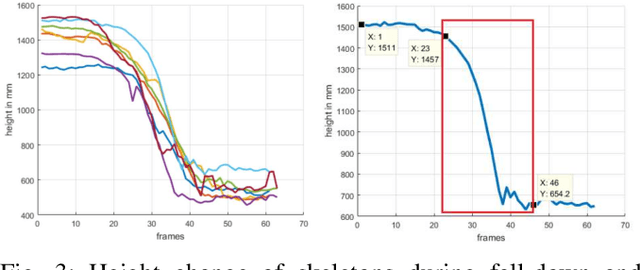
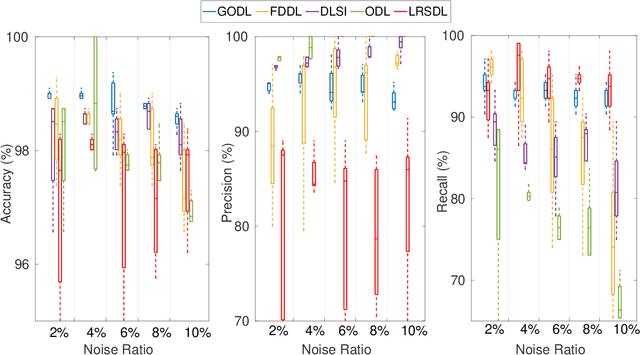
This paper propose a novel dictionary learning approach to detect event action using skeletal information extracted from RGBD video. The event action is represented as several latent atoms and composed of latent spatial and temporal attributes. We perform the method at the example of fall event detection. The skeleton frames are clustered by an initial K-means method. Each skeleton frame is assigned with a varying weight parameter and fed into our Gradual Online Dictionary Learning (GODL) algorithm. During the training process, outlier frames will be gradually filtered by reducing the weight that is inversely proportional to a cost. In order to strictly distinguish the event action from similar actions and robustly acquire its action unit, we build a latent unit temporal structure for each sub-action. We evaluate the proposed method on parts of the NTURGB+D dataset, which includes 209 fall videos, 405 ground-lift videos, 420 sit-down videos, and 280 videos of 46 otheractions. We present the experimental validation of the achieved accuracy, recall and precision. Our approach achieves the bestperformance on precision and accuracy of human fall event detection, compared with other existing dictionary learning methods. With increasing noise ratio, our method remains the highest accuracy and the lowest variance.