 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Evict from Key-Value Cache
Feb 10, 2026The growing size of Large Language Models (LLMs) makes efficient inference challenging, primarily due to the memory demands of the autoregressive Key-Value (KV) cache. Existing eviction or compression methods reduce cost but rely on heuristics, such as recency or past attention scores, which serve only as indirect proxies for a token's future utility and introduce computational overhead. We reframe KV cache eviction as a reinforcement learning (RL) problem: learning to rank tokens by their predicted usefulness for future decoding. To this end, we introduce KV Policy (KVP), a framework of lightweight per-head RL agents trained on pre-computed generation traces using only key and value vectors. Each agent learns a specialized eviction policy guided by future utility, which evaluates the quality of the ranking across all cache budgets, requiring no modifications to the underlying LLM or additional inference. Evaluated across two different model families on the long-context benchmark RULER and the multi-turn dialogue benchmark OASST2-4k, KVP significantly outperforms baselines. Furthermore, zero-shot tests on standard downstream tasks (e.g., LongBench, BOOLQ, ARC) indicate that KVP generalizes well beyond its training distribution and to longer context lengths. These results demonstrate that learning to predict future token utility is a powerful and scalable paradigm for adaptive KV cache management.
Navigating the Latent Space Dynamics of Neural Models
May 28, 2025Neural networks transform high-dimensional data into compact, structured representations, often modeled as elements of a lower dimensional latent space. In this paper, we present an alternative interpretation of neural models as dynamical systems acting on the latent manifold. Specifically, we show that autoencoder models implicitly define a latent vector field on the manifold, derived by iteratively applying the encoding-decoding map, without any additional training. We observe that standard training procedures introduce inductive biases that lead to the emergence of attractor points within this vector field. Drawing on this insight, we propose to leverage the vector field as a representation for the network, providing a novel tool to analyze the properties of the model and the data. This representation enables to: (i) analyze the generalization and memorization regimes of neural models, even throughout training; (ii) extract prior knowledge encoded in the network's parameters from the attractors, without requiring any input data; (iii) identify out-of-distribution samples from their trajectories in the vector field. We further validate our approach on vision foundation models, showcasing the applicability and effectiveness of our method in real-world scenarios.
Escaping Plato's Cave: Towards the Alignment of 3D and Text Latent Spaces
Mar 07, 2025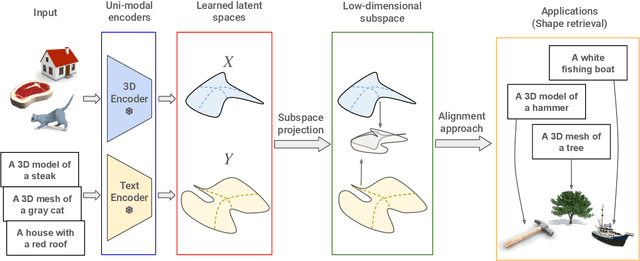
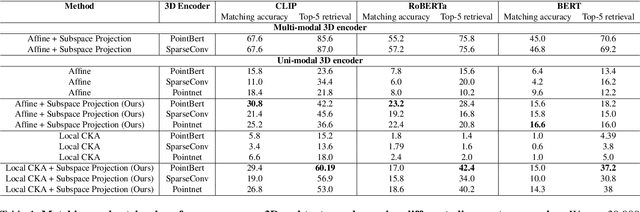
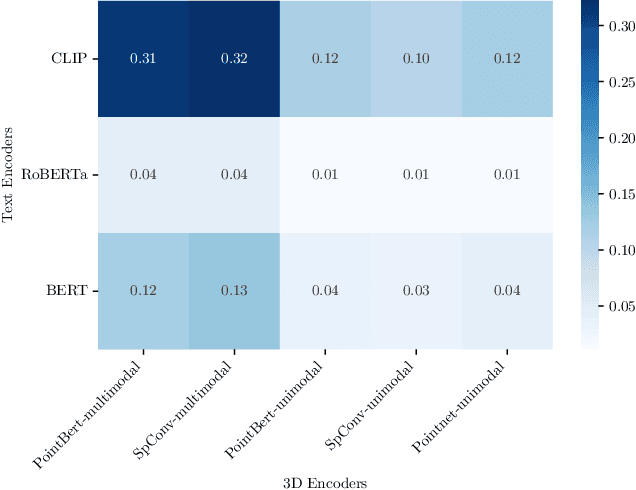
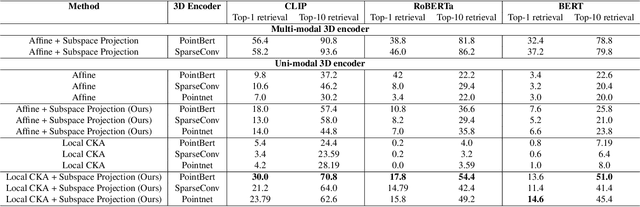
Recent works have shown that, when trained at scale, uni-modal 2D vision and text encoders converge to learned features that share remarkable structural properties, despite arising from different representations. However, the role of 3D encoders with respect to other modalities remains unexplored. Furthermore, existing 3D foundation models that leverage large datasets are typically trained with explicit alignment objectives with respect to frozen encoders from other representations. In this work, we investigate the possibility of a posteriori alignment of representations obtained from uni-modal 3D encoders compared to text-based feature spaces. We show that naive post-training feature alignment of uni-modal text and 3D encoders results in limited performance. We then focus on extracting subspaces of the corresponding feature spaces and discover that by projecting learned representations onto well-chosen lower-dimensional subspaces the quality of alignment becomes significantly higher, leading to improved accuracy on matching and retrieval tasks. Our analysis further sheds light on the nature of these shared subspaces, which roughly separate between semantic and geometric data representations. Overall, ours is the first work that helps to establish a baseline for post-training alignment of 3D uni-modal and text feature spaces, and helps to highlight both the shared and unique properties of 3D data compared to other representations.
Latent Space Translation via Inverse Relative Projection
Jun 21, 2024



The emergence of similar representations between independently trained neural models has sparked significant interest in the representation learning community, leading to the development of various methods to obtain communication between latent spaces. "Latent space communication" can be achieved in two ways: i) by independently mapping the original spaces to a shared or relative one; ii) by directly estimating a transformation from a source latent space to a target one. In this work, we combine the two into a novel method to obtain latent space translation through the relative space. By formalizing the invertibility of angle-preserving relative representations and assuming the scale invariance of decoder modules in neural models, we can effectively use the relative space as an intermediary, independently projecting onto and from other semantically similar spaces. Extensive experiments over various architectures and datasets validate our scale invariance assumption and demonstrate the high accuracy of our method in latent space translation. We also apply our method to zero-shot stitching between arbitrary pre-trained text and image encoders and their classifiers, even across modalities. Our method has significant potential for facilitating the reuse of models in a practical manner via compositionality.
Latent Communication in Artificial Neural Networks
Jun 16, 2024
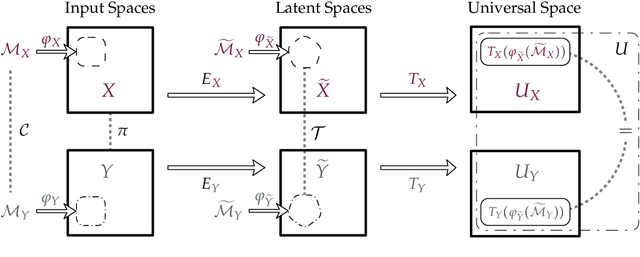


As NNs permeate various scientific and industrial domains, understanding the universality and reusability of their representations becomes crucial. At their core, these networks create intermediate neural representations, indicated as latent spaces, of the input data and subsequently leverage them to perform specific downstream tasks. This dissertation focuses on the universality and reusability of neural representations. Do the latent representations crafted by a NN remain exclusive to a particular trained instance, or can they generalize across models, adapting to factors such as randomness during training, model architecture, or even data domain? This adaptive quality introduces the notion of Latent Communication -- a phenomenon that describes when representations can be unified or reused across neural spaces. A salient observation from our research is the emergence of similarities in latent representations, even when these originate from distinct or seemingly unrelated NNs. By exploiting a partial correspondence between the two data distributions that establishes a semantic link, we found that these representations can either be projected into a universal representation, coined as Relative Representation, or be directly translated from one space to another. Latent Communication allows for a bridge between independently trained NN, irrespective of their training regimen, architecture, or the data modality they were trained on -- as long as the data semantic content stays the same (e.g., images and their captions). This holds true for both generation, classification and retrieval downstream tasks; in supervised, weakly supervised, and unsupervised settings; and spans various data modalities including images, text, audio, and graphs -- showcasing the universality of the Latent Communication phenomenon. [...]
Zero-Shot Stitching in Reinforcement Learning using Relative Representations
Apr 19, 2024Visual Reinforcement Learning is a popular and powerful framework that takes full advantage of the Deep Learning breakthrough. However, it is also known that variations in the input (e.g., different colors of the panorama due to the season of the year) or the task (e.g., changing the speed limit for a car to respect) could require complete retraining of the agents. In this work, we leverage recent developments in unifying latent representations to demonstrate that it is possible to combine the components of an agent, rather than retrain it from scratch. We build upon the recent relative representations framework and adapt it for Visual RL. This allows us to create completely new agents capable of handling environment-task combinations never seen during training. Our work paves the road toward a more accessible and flexible use of reinforcement learning.
From Charts to Atlas: Merging Latent Spaces into One
Nov 11, 2023



Models trained on semantically related datasets and tasks exhibit comparable inter-sample relations within their latent spaces. We investigate in this study the aggregation of such latent spaces to create a unified space encompassing the combined information. To this end, we introduce Relative Latent Space Aggregation, a two-step approach that first renders the spaces comparable using relative representations, and then aggregates them via a simple mean. We carefully divide a classification problem into a series of learning tasks under three different settings: sharing samples, classes, or neither. We then train a model on each task and aggregate the resulting latent spaces. We compare the aggregated space with that derived from an end-to-end model trained over all tasks and show that the two spaces are similar. We then observe that the aggregated space is better suited for classification, and empirically demonstrate that it is due to the unique imprints left by task-specific embedders within the representations. We finally test our framework in scenarios where no shared region exists and show that it can still be used to merge the spaces, albeit with diminished benefits over naive merging.
Latent Space Translation via Semantic Alignment
Nov 01, 2023



While different neural models often exhibit latent spaces that are alike when exposed to semantically related data, this intrinsic similarity is not always immediately discernible. Towards a better understanding of this phenomenon, our work shows how representations learned from these neural modules can be translated between different pre-trained networks via simpler transformations than previously thought. An advantage of this approach is the ability to estimate these transformations using standard, well-understood algebraic procedures that have closed-form solutions. Our method directly estimates a transformation between two given latent spaces, thereby enabling effective stitching of encoders and decoders without additional training. We extensively validate the adaptability of this translation procedure in different experimental settings: across various trainings, domains, architectures (e.g., ResNet, CNN, ViT), and in multiple downstream tasks (classification, reconstruction). Notably, we show how it is possible to zero-shot stitch text encoders and vision decoders, or vice-versa, yielding surprisingly good classification performance in this multimodal setting.
From Bricks to Bridges: Product of Invariances to Enhance Latent Space Communication
Oct 02, 2023



It has been observed that representations learned by distinct neural networks conceal structural similarities when the models are trained under similar inductive biases. From a geometric perspective, identifying the classes of transformations and the related invariances that connect these representations is fundamental to unlocking applications, such as merging, stitching, and reusing different neural modules. However, estimating task-specific transformations a priori can be challenging and expensive due to several factors (e.g., weights initialization, training hyperparameters, or data modality). To this end, we introduce a versatile method to directly incorporate a set of invariances into the representations, constructing a product space of invariant components on top of the latent representations without requiring prior knowledge about the optimal invariance to infuse. We validate our solution on classification and reconstruction tasks, observing consistent latent similarity and downstream performance improvements in a zero-shot stitching setting. The experimental analysis comprises three modalities (vision, text, and graphs), twelve pretrained foundational models, eight benchmarks, and several architectures trained from scratch.
Bootstrapping Parallel Anchors for Relative Representations
Mar 01, 2023



The use of relative representations for latent embeddings has shown potential in enabling latent space communication and zero-shot model stitching across a wide range of applications. Nevertheless, relative representations rely on a certain amount of parallel anchors to be given as input, which can be impractical to obtain in certain scenarios. To overcome this limitation, we propose an optimization-based method to discover new parallel anchors from a limited number of seeds. Our approach can be used to find semantic correspondence between different domains, align their relative spaces, and achieve competitive results in several tasks.