 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Train Once: Differentiable Subset Selection for Omics Data
Dec 19, 2025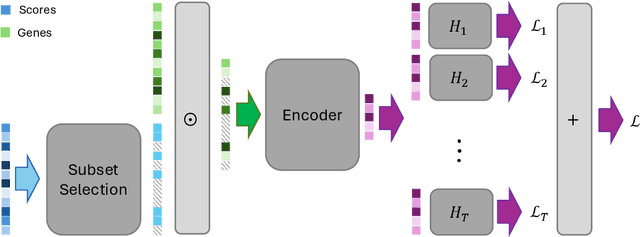

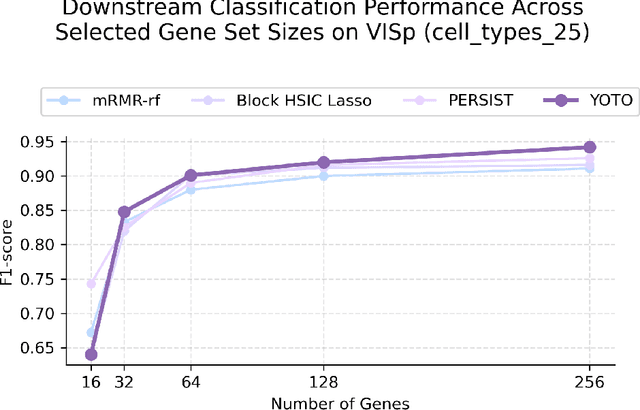
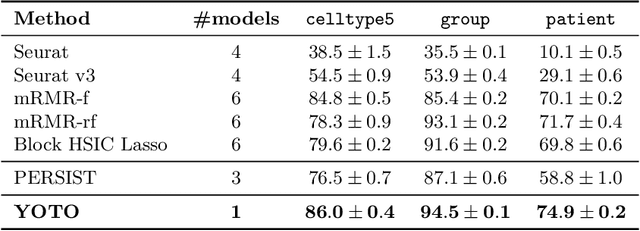
Selecting compact and informative gene subsets from single-cell transcriptomic data is essential for biomarker discovery, improving interpretability, and cost-effective profiling. However, most existing feature selection approaches either operate as multi-stage pipelines or rely on post hoc feature attribution, making selection and prediction weakly coupled. In this work, we present YOTO (you only train once), an end-to-end framework that jointly identifies discrete gene subsets and performs prediction within a single differentiable architecture. In our model, the prediction task directly guides which genes are selected, while the learned subsets, in turn, shape the predictive representation. This closed feedback loop enables the model to iteratively refine both what it selects and how it predicts during training. Unlike existing approaches, YOTO enforces sparsity so that only the selected genes contribute to inference, eliminating the need to train additional downstream classifiers. Through a multi-task learning design, the model learns shared representations across related objectives, allowing partially labeled datasets to inform one another, and discovering gene subsets that generalize across tasks without additional training steps. We evaluate YOTO on two representative single-cell RNA-seq datasets, showing that it consistently outperforms state-of-the-art baselines. These results demonstrate that sparse, end-to-end, multi-task gene subset selection improves predictive performance and yields compact and meaningful gene subsets, advancing biomarker discovery and single-cell analysis.
Detecting and Approximating Redundant Computational Blocks in Neural Networks
Oct 07, 2024Deep neural networks often learn similar internal representations, both across different models and within their own layers. While inter-network similarities have enabled techniques such as model stitching and merging, intra-network similarities present new opportunities for designing more efficient architectures. In this paper, we investigate the emergence of these internal similarities across different layers in diverse neural architectures, showing that similarity patterns emerge independently of the datataset used. We introduce a simple metric, Block Redundancy, to detect redundant blocks, providing a foundation for future architectural optimization methods. Building on this, we propose Redundant Blocks Approximation (RBA), a general framework that identifies and approximates one or more redundant computational blocks using simpler transformations. We show that the transformation $\mathcal{T}$ between two representations can be efficiently computed in closed-form, and it is enough to replace the redundant blocks from the network. RBA reduces model parameters and time complexity while maintaining good performance. We validate our method on classification tasks in the vision domain using a variety of pretrained foundational models and datasets.
From Charts to Atlas: Merging Latent Spaces into One
Nov 11, 2023



Models trained on semantically related datasets and tasks exhibit comparable inter-sample relations within their latent spaces. We investigate in this study the aggregation of such latent spaces to create a unified space encompassing the combined information. To this end, we introduce Relative Latent Space Aggregation, a two-step approach that first renders the spaces comparable using relative representations, and then aggregates them via a simple mean. We carefully divide a classification problem into a series of learning tasks under three different settings: sharing samples, classes, or neither. We then train a model on each task and aggregate the resulting latent spaces. We compare the aggregated space with that derived from an end-to-end model trained over all tasks and show that the two spaces are similar. We then observe that the aggregated space is better suited for classification, and empirically demonstrate that it is due to the unique imprints left by task-specific embedders within the representations. We finally test our framework in scenarios where no shared region exists and show that it can still be used to merge the spaces, albeit with diminished benefits over naive merging.
From Bricks to Bridges: Product of Invariances to Enhance Latent Space Communication
Oct 02, 2023



It has been observed that representations learned by distinct neural networks conceal structural similarities when the models are trained under similar inductive biases. From a geometric perspective, identifying the classes of transformations and the related invariances that connect these representations is fundamental to unlocking applications, such as merging, stitching, and reusing different neural modules. However, estimating task-specific transformations a priori can be challenging and expensive due to several factors (e.g., weights initialization, training hyperparameters, or data modality). To this end, we introduce a versatile method to directly incorporate a set of invariances into the representations, constructing a product space of invariant components on top of the latent representations without requiring prior knowledge about the optimal invariance to infuse. We validate our solution on classification and reconstruction tasks, observing consistent latent similarity and downstream performance improvements in a zero-shot stitching setting. The experimental analysis comprises three modalities (vision, text, and graphs), twelve pretrained foundational models, eight benchmarks, and several architectures trained from scratch.
Bootstrapping Parallel Anchors for Relative Representations
Mar 01, 2023



The use of relative representations for latent embeddings has shown potential in enabling latent space communication and zero-shot model stitching across a wide range of applications. Nevertheless, relative representations rely on a certain amount of parallel anchors to be given as input, which can be impractical to obtain in certain scenarios. To overcome this limitation, we propose an optimization-based method to discover new parallel anchors from a limited number of seeds. Our approach can be used to find semantic correspondence between different domains, align their relative spaces, and achieve competitive results in several tasks.
AI-based Data Preparation and Data Analytics in Healthcare: The Case of Diabetes
Jun 13, 2022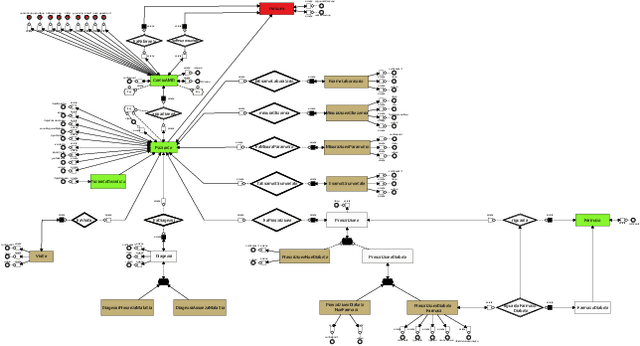
The Associazione Medici Diabetologi (AMD) collects and manages one of the largest worldwide-available collections of diabetic patient records, also known as the AMD database. This paper presents the initial results of an ongoing project whose focus is the application of Artificial Intelligence and Machine Learning techniques for conceptualizing, cleaning, and analyzing such an important and valuable dataset, with the goal of providing predictive insights to better support diabetologists in their diagnostic and therapeutic choices.