 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-based Representation Distillation Baseline for Multi-Label Continual Learning
Jul 19, 2024


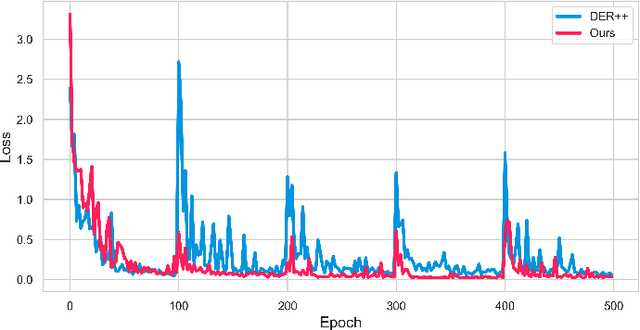
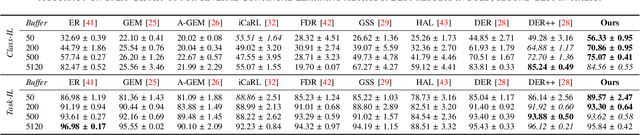
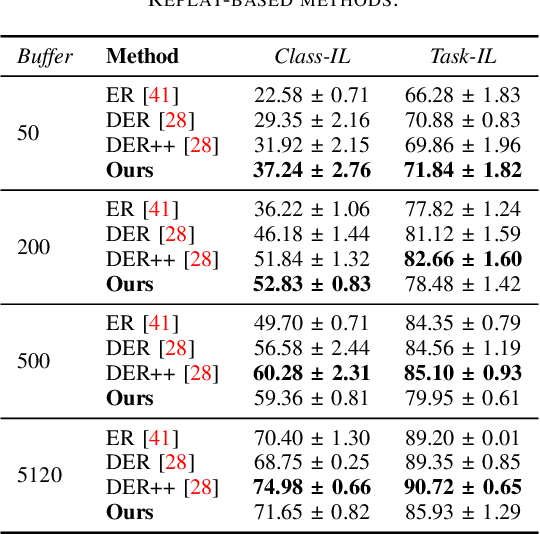
The field of Continual Learning (CL) has inspired numerous researchers over the years, leading to increasingly advanced countermeasures to the issue of catastrophic forgetting. Most studies have focused on the single-class scenario, where each example comes with a single label. The recent literature has successfully tackled such a setting, with impressive results. Differently, we shift our attention to the multi-label scenario, as we feel it to be more representative of real-world open problems. In our work, we show that existing state-of-the-art CL methods fail to achieve satisfactory performance, thus questioning the real advance claimed in recent years. Therefore, we assess both old-style and novel strategies and propose, on top of them, an approach called Selective Class Attention Distillation (SCAD). It relies on a knowledge transfer technique that seeks to align the representations of the student network -- which trains continuously and is subject to forgetting -- with the teacher ones, which is pretrained and kept frozen. Importantly, our method is able to selectively transfer the relevant information from the teacher to the student, thereby preventing irrelevant information from harming the student's performance during online training. To demonstrate the merits of our approach, we conduct experiments on two different multi-label datasets, showing that our method outperforms the current state-of-the-art Continual Learning methods. Our findings highlight the importance of addressing the unique challenges posed by multi-label environments in the field of Continual Learning. The code of SCAD is available at https://github.com/aimagelab/SCAD-LOD-2024.
Selective Attention-based Modulation for Continual Learning
Mar 29, 2024



We present SAM, a biologically-plausible selective attention-driven modulation approach to enhance classification models in a continual learning setting. Inspired by neurophysiological evidence that the primary visual cortex does not contribute to object manifold untangling for categorization and that primordial attention biases are still embedded in the modern brain, we propose to employ auxiliary saliency prediction features as a modulation signal to drive and stabilize the learning of a sequence of non-i.i.d. classification tasks. Experimental results confirm that SAM effectively enhances the performance (in some cases up to about twenty percent points) of state-of-the-art continual learning methods, both in class-incremental and task-incremental settings. Moreover, we show that attention-based modulation successfully encourages the learning of features that are more robust to the presence of spurious features and to adversarial attacks than baseline methods. Code is available at: https://github.com/perceivelab/SAM.
Semantic Residual Prompts for Continual Learning
Mar 14, 2024Prompt-tuning methods for Continual Learning (CL) freeze a large pre-trained model and focus training on a few parameter vectors termed prompts. Most of these methods organize these vectors in a pool of key-value pairs, and use the input image as query to retrieve the prompts (values). However, as keys are learned while tasks progress, the prompting selection strategy is itself subject to catastrophic forgetting, an issue often overlooked by existing approaches. For instance, prompts introduced to accommodate new tasks might end up interfering with previously learned prompts. To make the selection strategy more stable, we ask a foundational model (CLIP) to select our prompt within a two-level adaptation mechanism. Specifically, the first level leverages standard textual prompts for the CLIP textual encoder, leading to stable class prototypes. The second level, instead, uses these prototypes along with the query image as keys to index a second pool. The retrieved prompts serve to adapt a pre-trained ViT, granting plasticity. In doing so, we also propose a novel residual mechanism to transfer CLIP semantics to the ViT layers. Through extensive analysis on established CL benchmarks, we show that our method significantly outperforms both state-of-the-art CL approaches and the zero-shot CLIP test. Notably, our findings hold true even for datasets with a substantial domain gap w.r.t. the pre-training knowledge of the backbone model, as showcased by experiments on satellite imagery and medical datasets.
On the Effectiveness of Equivariant Regularization for Robust Online Continual Learning
May 05, 2023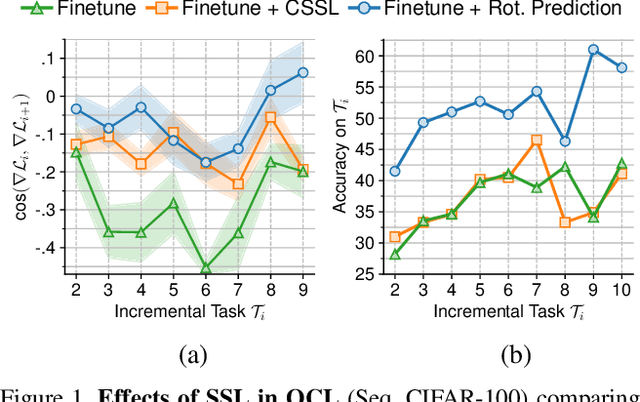
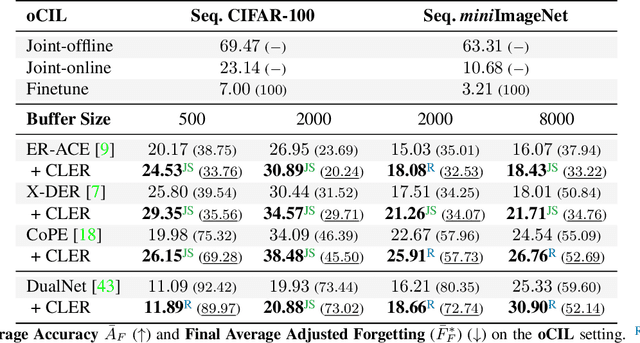
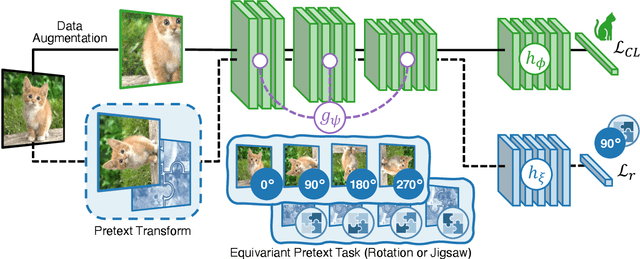
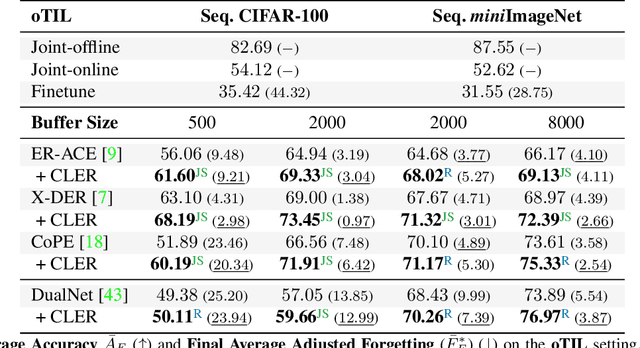
Humans can learn incrementally, whereas neural networks forget previously acquired information catastrophically. Continual Learning (CL) approaches seek to bridge this gap by facilitating the transfer of knowledge to both previous tasks (backward transfer) and future ones (forward transfer) during training. Recent research has shown that self-supervision can produce versatile models that can generalize well to diverse downstream tasks. However, contrastive self-supervised learning (CSSL), a popular self-supervision technique, has limited effectiveness in online CL (OCL). OCL only permits one iteration of the input dataset, and CSSL's low sample efficiency hinders its use on the input data-stream. In this work, we propose Continual Learning via Equivariant Regularization (CLER), an OCL approach that leverages equivariant tasks for self-supervision, avoiding CSSL's limitations. Our method represents the first attempt at combining equivariant knowledge with CL and can be easily integrated with existing OCL methods. Extensive ablations shed light on how equivariant pretext tasks affect the network's information flow and its impact on CL dynamics.
CaSpeR: Latent Spectral Regularization for Continual Learning
Jan 09, 2023While biological intelligence grows organically as new knowledge is gathered throughout life, Artificial Neural Networks forget catastrophically whenever they face a changing training data distribution. Rehearsal-based Continual Learning (CL) approaches have been established as a versatile and reliable solution to overcome this limitation; however, sudden input disruptions and memory constraints are known to alter the consistency of their predictions. We study this phenomenon by investigating the geometric characteristics of the learner's latent space and find that replayed data points of different classes increasingly mix up, interfering with classification. Hence, we propose a geometric regularizer that enforces weak requirements on the Laplacian spectrum of the latent space, promoting a partitioning behavior. We show that our proposal, called Continual Spectral Regularizer (CaSpeR), can be easily combined with any rehearsal-based CL approach and improves the performance of SOTA methods on standard benchmarks. Finally, we conduct additional analysis to provide insights into CaSpeR's effects and applicability.
On the Effectiveness of Lipschitz-Driven Rehearsal in Continual Learning
Oct 16, 2022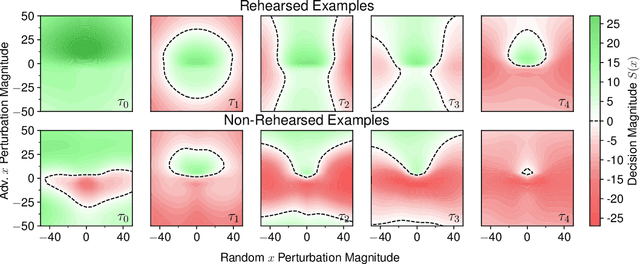
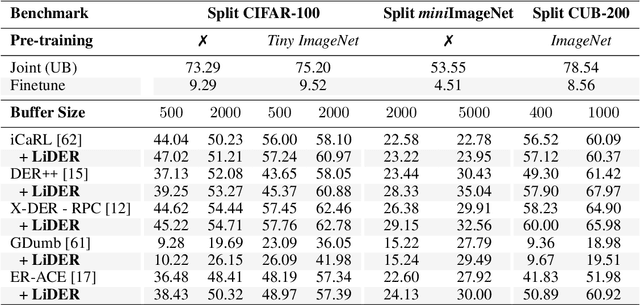
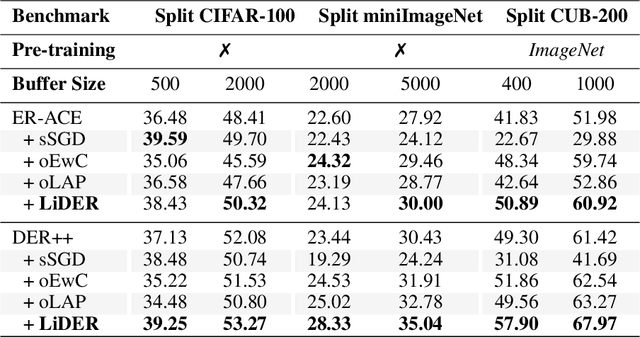
Rehearsal approaches enjoy immense popularity with Continual Learning (CL) practitioners. These methods collect samples from previously encountered data distributions in a small memory buffer; subsequently, they repeatedly optimize on the latter to prevent catastrophic forgetting. This work draws attention to a hidden pitfall of this widespread practice: repeated optimization on a small pool of data inevitably leads to tight and unstable decision boundaries, which are a major hindrance to generalization. To address this issue, we propose Lipschitz-DrivEn Rehearsal (LiDER), a surrogate objective that induces smoothness in the backbone network by constraining its layer-wise Lipschitz constants w.r.t. replay examples. By means of extensive experiments, we show that applying LiDER delivers a stable performance gain to several state-of-the-art rehearsal CL methods across multiple datasets, both in the presence and absence of pre-training. Through additional ablative experiments, we highlight peculiar aspects of buffer overfitting in CL and better characterize the effect produced by LiDER. Code is available at https://github.com/aimagelab/LiDER
Effects of Auxiliary Knowledge on Continual Learning
Jun 03, 2022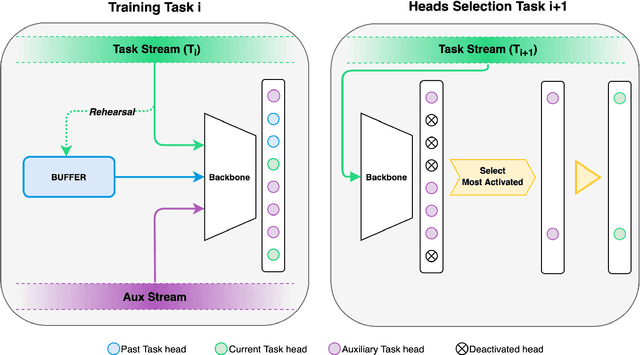
In Continual Learning (CL), a neural network is trained on a stream of data whose distribution changes over time. In this context, the main problem is how to learn new information without forgetting old knowledge (i.e., Catastrophic Forgetting). Most existing CL approaches focus on finding solutions to preserve acquired knowledge, so working on the past of the model. However, we argue that as the model has to continually learn new tasks, it is also important to put focus on the present knowledge that could improve following tasks learning. In this paper we propose a new, simple, CL algorithm that focuses on solving the current task in a way that might facilitate the learning of the next ones. More specifically, our approach combines the main data stream with a secondary, diverse and uncorrelated stream, from which the network can draw auxiliary knowledge. This helps the model from different perspectives, since auxiliary data may contain useful features for the current and the next tasks and incoming task classes can be mapped onto auxiliary classes. Furthermore, the addition of data to the current task is implicitly making the classifier more robust as we are forcing the extraction of more discriminative features. Our method can outperform existing state-of-the-art models on the most common CL Image Classification benchmarks.
Transfer without Forgetting
Jun 01, 2022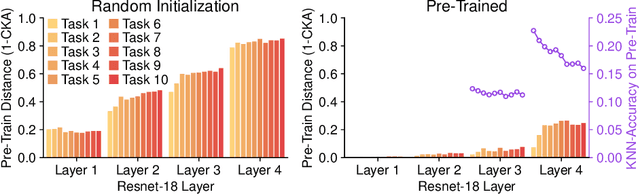
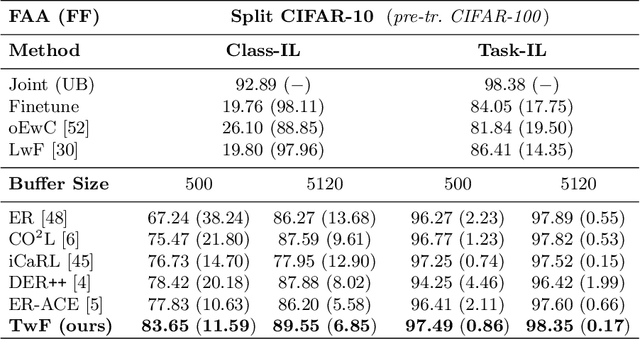
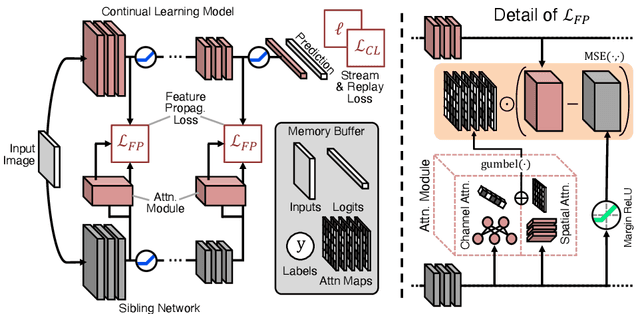
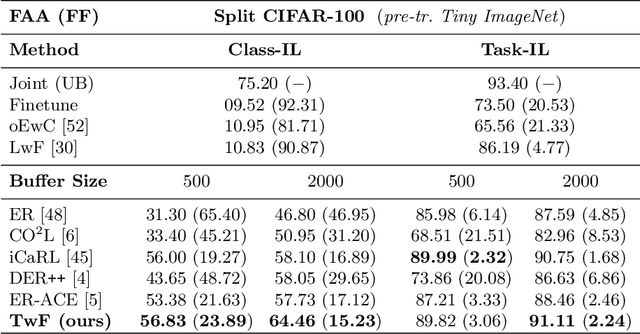
This work investigates the entanglement between Continual Learning (CL) and Transfer Learning (TL). In particular, we shed light on the widespread application of network pretraining, highlighting that it is itself subject to catastrophic forgetting. Unfortunately, this issue leads to the under-exploitation of knowledge transfer during later tasks. On this ground, we propose Transfer without Forgetting (TwF), a hybrid Continual Transfer Learning approach building upon a fixed pretrained sibling network, which continuously propagates the knowledge inherent in the source domain through a layer-wise loss term. Our experiments indicate that TwF steadily outperforms other CL methods across a variety of settings, averaging a 4.81% gain in Class-Incremental accuracy over a variety of datasets and different buffer sizes.
Class-Incremental Continual Learning into the eXtended DER-verse
Jan 03, 2022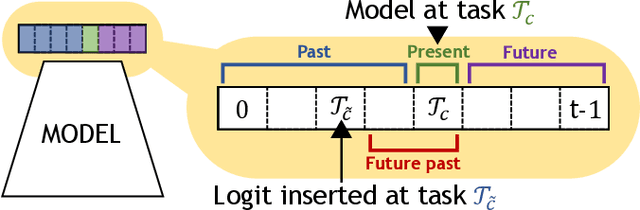



The staple of human intelligence is the capability of acquiring knowledge in a continuous fashion. In stark contrast, Deep Networks forget catastrophically and, for this reason, the sub-field of Class-Incremental Continual Learning fosters methods that learn a sequence of tasks incrementally, blending sequentially-gained knowledge into a comprehensive prediction. This work aims at assessing and overcoming the pitfalls of our previous proposal Dark Experience Replay (DER), a simple and effective approach that combines rehearsal and Knowledge Distillation. Inspired by the way our minds constantly rewrite past recollections and set expectations for the future, we endow our model with the abilities to i) revise its replay memory to welcome novel information regarding past data ii) pave the way for learning yet unseen classes. We show that the application of these strategies leads to remarkable improvements; indeed, the resulting method - termed eXtended-DER (X-DER) - outperforms the state of the art on both standard benchmarks (such as CIFAR-100 and miniImagenet) and a novel one here introduced. To gain a better understanding, we further provide extensive ablation studies that corroborate and extend the findings of our previous research (e.g. the value of Knowledge Distillation and flatter minima in continual learning setups).
Weakly Supervised Continual Learning
Aug 14, 2021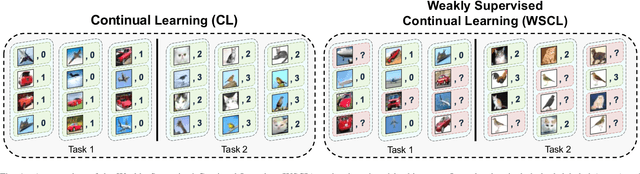
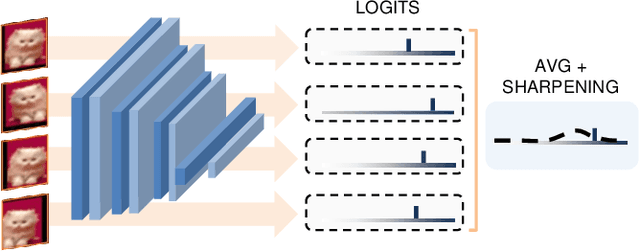
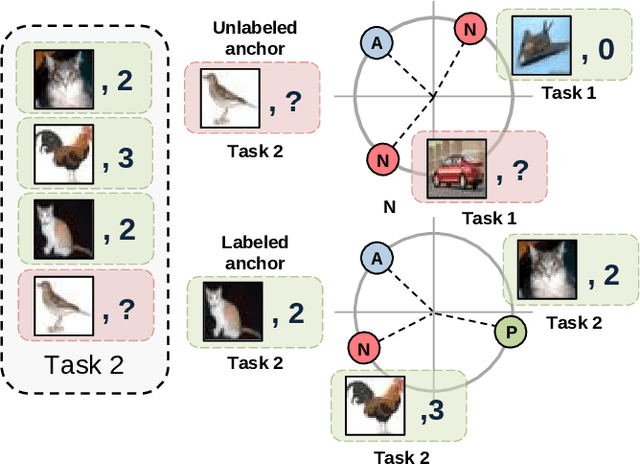
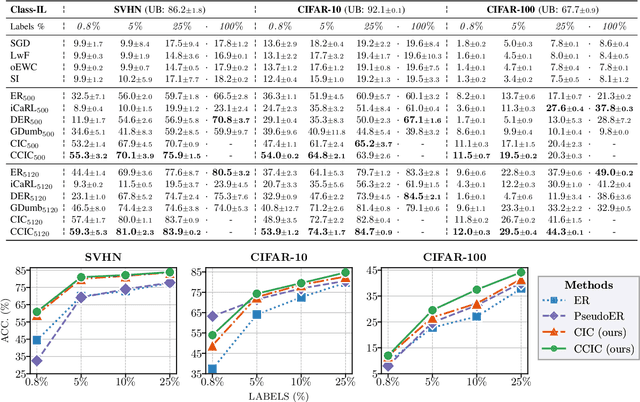
Continual Learning (CL) investigates how to train Deep Networks on a stream of tasks without incurring catastrophic forgetting. CL settings proposed in the literature assume that every incoming example is paired with ground-truth annotations. However, this clashes with many real-world applications: gathering labeled data, which is in itself tedious and expensive, becomes indeed infeasible when data flow as a stream and must be consumed in real-time. This work explores Weakly Supervised Continual Learning (WSCL): here, only a small fraction of labeled input examples are shown to the learner. We assess how current CL methods (e.g.: EWC, LwF, iCaRL, ER, GDumb, DER) perform in this novel and challenging scenario, in which overfitting entangles forgetting. Subsequently, we design two novel WSCL methods which exploit metric learning and consistency regularization to leverage unsupervised data while learning. In doing so, we show that not only our proposals exhibit higher flexibility when supervised information is scarce, but also that less than 25% labels can be enough to reach or even outperform SOTA methods trained under full supervision.