 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Incremental Continual Learning into the eXtended DER-verse
Paper and Code
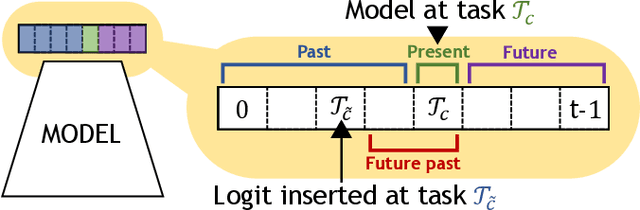



The staple of human intelligence is the capability of acquiring knowledge in a continuous fashion. In stark contrast, Deep Networks forget catastrophically and, for this reason, the sub-field of Class-Incremental Continual Learning fosters methods that learn a sequence of tasks incrementally, blending sequentially-gained knowledge into a comprehensive prediction. This work aims at assessing and overcoming the pitfalls of our previous proposal Dark Experience Replay (DER), a simple and effective approach that combines rehearsal and Knowledge Distillation. Inspired by the way our minds constantly rewrite past recollections and set expectations for the future, we endow our model with the abilities to i) revise its replay memory to welcome novel information regarding past data ii) pave the way for learning yet unseen classes. We show that the application of these strategies leads to remarkable improvements; indeed, the resulting method - termed eXtended-DER (X-DER) - outperforms the state of the art on both standard benchmarks (such as CIFAR-100 and miniImagenet) and a novel one here introduced. To gain a better understanding, we further provide extensive ablation studies that corroborate and extend the findings of our previous research (e.g. the value of Knowledge Distillation and flatter minima in continual learning setups).