 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer without Forgetting
Paper and Code
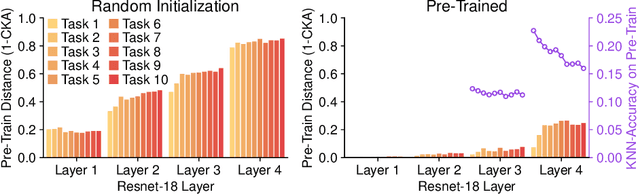
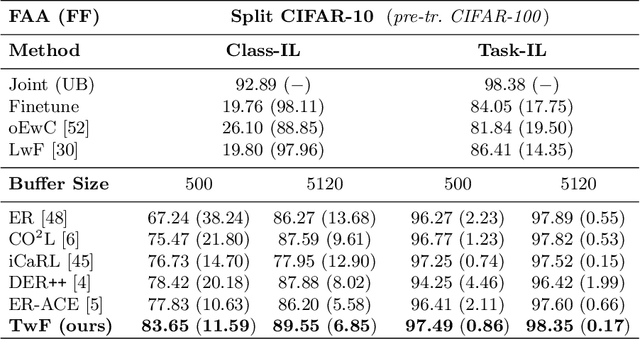
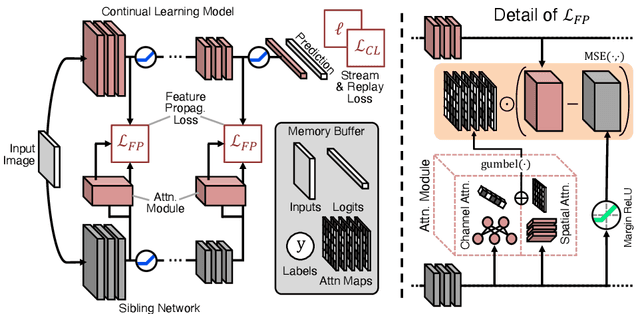
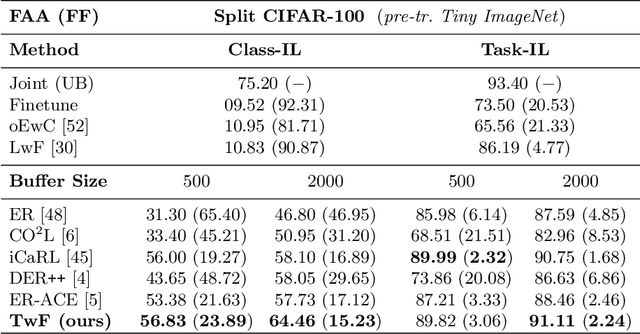
This work investigates the entanglement between Continual Learning (CL) and Transfer Learning (TL). In particular, we shed light on the widespread application of network pretraining, highlighting that it is itself subject to catastrophic forgetting. Unfortunately, this issue leads to the under-exploitation of knowledge transfer during later tasks. On this ground, we propose Transfer without Forgetting (TwF), a hybrid Continual Transfer Learning approach building upon a fixed pretrained sibling network, which continuously propagates the knowledge inherent in the source domain through a layer-wise loss term. Our experiments indicate that TwF steadily outperforms other CL methods across a variety of settings, averaging a 4.81% gain in Class-Incremental accuracy over a variety of datasets and different buffer sizes.