 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Continual Learning
Paper and Code
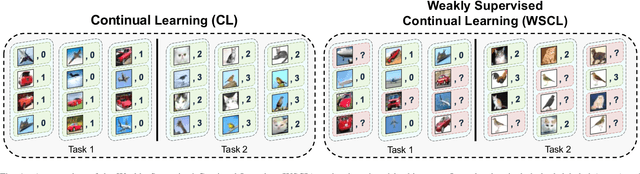
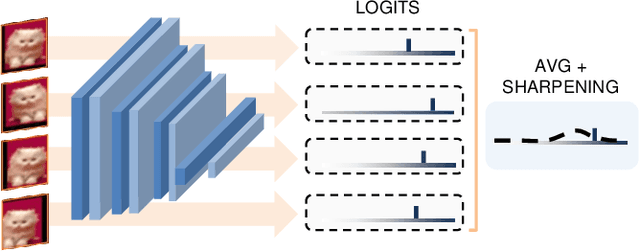
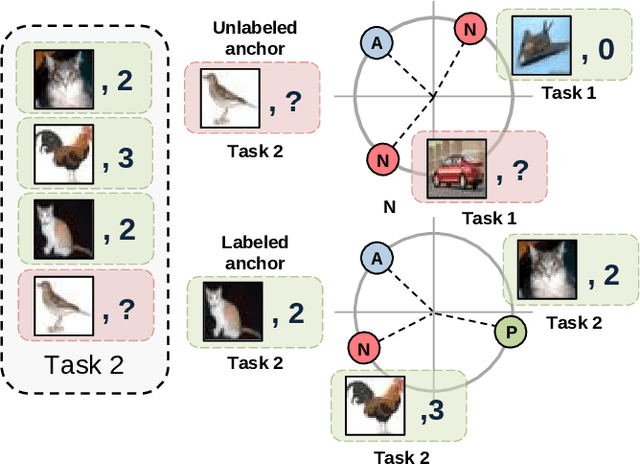
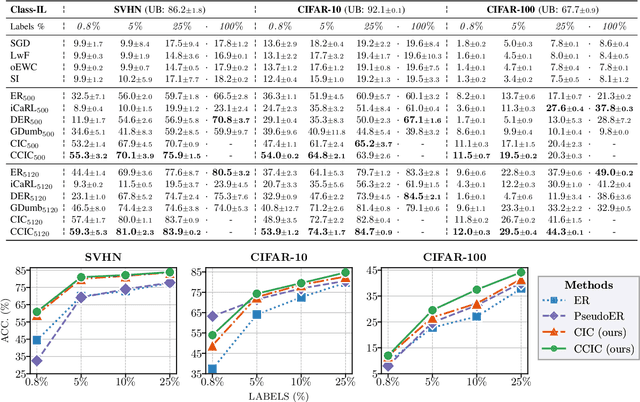
Continual Learning (CL) investigates how to train Deep Networks on a stream of tasks without incurring catastrophic forgetting. CL settings proposed in the literature assume that every incoming example is paired with ground-truth annotations. However, this clashes with many real-world applications: gathering labeled data, which is in itself tedious and expensive, becomes indeed infeasible when data flow as a stream and must be consumed in real-time. This work explores Weakly Supervised Continual Learning (WSCL): here, only a small fraction of labeled input examples are shown to the learner. We assess how current CL methods (e.g.: EWC, LwF, iCaRL, ER, GDumb, DER) perform in this novel and challenging scenario, in which overfitting entangles forgetting. Subsequently, we design two novel WSCL methods which exploit metric learning and consistency regularization to leverage unsupervised data while learning. In doing so, we show that not only our proposals exhibit higher flexibility when supervised information is scarce, but also that less than 25% labels can be enough to reach or even outperform SOTA methods trained under full supervision.