 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustCLIP: Learning Private Visual Features via Adversarial Reconstruction
Jul 05, 2026Vision and vision-language models rely on high-level visual representations that are increasingly used across recognition, retrieval, and multimodal reasoning pipelines. However, recent advances in generative modeling have shown that such features can often be inverted, enabling realistic reconstructions of the underlying image and raising significant privacy risks. We revisit this problem through the lens of reconstruction and propose TrustCLIP, a reconstruction-driven framework that treats a feature-conditioned generator as an explicit privacy adversary. TrustCLIP learns a projection between encoder features and downstream modules that is explicitly optimized to degrade the reconstructions produced by generative attackers while retaining the necessary signals for downstream tasks. Unlike prior defenses that rely on discriminative privacy metrics, TrustCLIP directly optimizes against a generative reconstruction attacker, targeting a threat not captured by standard evaluation protocols. We demonstrate its effectiveness in both conventional classification and multimodal large language model pipelines. Across these settings, TrustCLIP consistently reduces the fidelity of generative inversions while maintaining downstream task performance. Project page: https://atnikos.github.io/trustclip/
ECHO: Ego-Centric modeling of Human-Object interactions
Aug 29, 2025
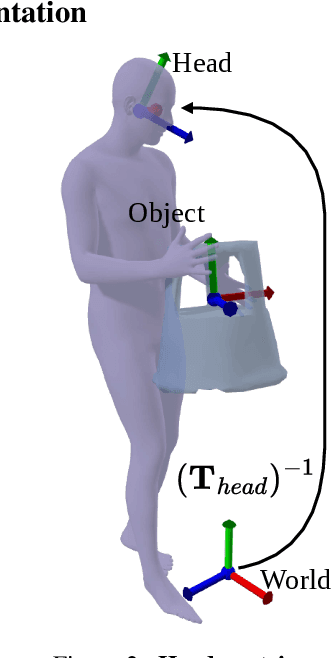
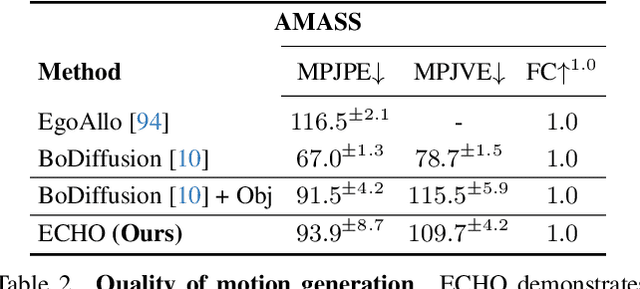
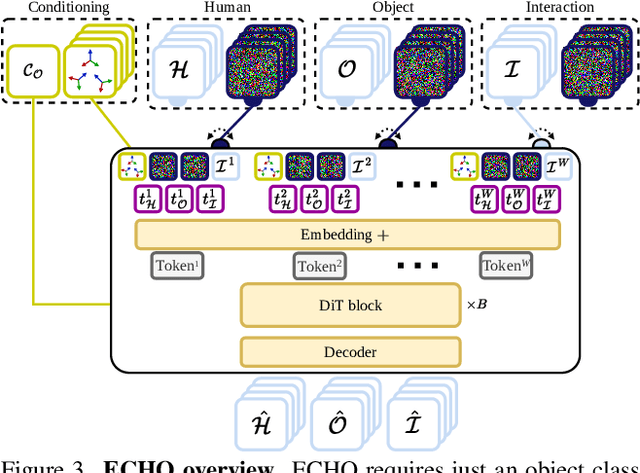
Modeling human-object interactions (HOI) from an egocentric perspective is a largely unexplored yet important problem due to the increasing adoption of wearable devices, such as smart glasses and watches. We investigate how much information about interaction can be recovered from only head and wrists tracking. Our answer is ECHO (Ego-Centric modeling of Human-Object interactions), which, for the first time, proposes a unified framework to recover three modalities: human pose, object motion, and contact from such minimal observation. ECHO employs a Diffusion Transformer architecture and a unique three-variate diffusion process, which jointly models human motion, object trajectory, and contact sequence, allowing for flexible input configurations. Our method operates in a head-centric canonical space, enhancing robustness to global orientation. We propose a conveyor-based inference, which progressively increases the diffusion timestamp with the frame position, allowing us to process sequences of any length. Through extensive evaluation, we demonstrate that ECHO outperforms existing methods that do not offer the same flexibility, setting a state-of-the-art in egocentric HOI reconstruction.
TriDi: Trilateral Diffusion of 3D Humans, Objects, and Interactions
Dec 09, 2024Modeling 3D human-object interaction (HOI) is a problem of great interest for computer vision and a key enabler for virtual and mixed-reality applications. Existing methods work in a one-way direction: some recover plausible human interactions conditioned on a 3D object; others recover the object pose conditioned on a human pose. Instead, we provide the first unified model - TriDi which works in any direction. Concretely, we generate Human, Object, and Interaction modalities simultaneously with a new three-way diffusion process, allowing to model seven distributions with one network. We implement TriDi as a transformer attending to the various modalities' tokens, thereby discovering conditional relations between them. The user can control the interaction either as a text description of HOI or a contact map. We embed these two representations into a shared latent space, combining the practicality of text descriptions with the expressiveness of contact maps. Using a single network, TriDi unifies all the special cases of prior work and extends to new ones, modeling a family of seven distributions. Remarkably, despite using a single model, TriDi generated samples surpass one-way specialized baselines on GRAB and BEHAVE in terms of both qualitative and quantitative metrics, and demonstrating better diversity. We show the applicability of TriDi to scene population, generating objects for human-contact datasets, and generalization to unseen object geometry. The project page is available at: https://virtualhumans.mpi-inf.mpg.de/tridi.
Blendify -- Python rendering framework for Blender
Oct 23, 2024

With the rapid growth of the volume of research fields like computer vision and computer graphics, researchers require effective and user-friendly rendering tools to visualize results. While advanced tools like Blender offer powerful capabilities, they also require a significant effort to master. This technical report introduces Blendify, a lightweight Python-based framework that seamlessly integrates with Blender, providing a high-level API for scene creation and rendering. Blendify reduces the complexity of working with Blender's native API by automating object creation, handling the colors and material linking, and implementing features such as shadow-catcher objects while maintaining support for high-quality ray-tracing rendering output. With a focus on usability Blendify enables efficient and flexible rendering workflow for rendering in common computer vision and computer graphics use cases. The code is available at https://github.com/ptrvilya/blendify
Object pop-up: Can we infer 3D objects and their poses from human interactions alone?
Jun 01, 2023The intimate entanglement between objects affordances and human poses is of large interest, among others, for behavioural sciences, cognitive psychology, and Computer Vision communities. In recent years, the latter has developed several object-centric approaches: starting from items, learning pipelines synthesizing human poses and dynamics in a realistic way, satisfying both geometrical and functional expectations. However, the inverse perspective is significantly less explored: Can we infer 3D objects and their poses from human interactions alone? Our investigation follows this direction, showing that a generic 3D human point cloud is enough to pop up an unobserved object, even when the user is just imitating a functionality (e.g., looking through a binocular) without involving a tangible counterpart. We validate our method qualitatively and quantitatively, with synthetic data and sequences acquired for the task, showing applicability for XR/VR. The code is available at https://github.com/ptrvilya/object-popup.
BEHAVE: Dataset and Method for Tracking Human Object Interactions
Apr 14, 2022



Modelling interactions between humans and objects in natural environments is central to many applications including gaming, virtual and mixed reality, as well as human behavior analysis and human-robot collaboration. This challenging operation scenario requires generalization to vast number of objects, scenes, and human actions. Unfortunately, there exist no such dataset. Moreover, this data needs to be acquired in diverse natural environments, which rules out 4D scanners and marker based capture systems. We present BEHAVE dataset, the first full body human- object interaction dataset with multi-view RGBD frames and corresponding 3D SMPL and object fits along with the annotated contacts between them. We record around 15k frames at 5 locations with 8 subjects performing a wide range of interactions with 20 common objects. We use this data to learn a model that can jointly track humans and objects in natural environments with an easy-to-use portable multi-camera setup. Our key insight is to predict correspondences from the human and the object to a statistical body model to obtain human-object contacts during interactions. Our approach can record and track not just the humans and objects but also their interactions, modeled as surface contacts, in 3D. Our code and data can be found at: http://virtualhumans.mpi-inf.mpg.de/behave
* Accepted at CVPR'22