 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoLingo: Motion-Language Alignment for Text-to-Motion Generation
Dec 15, 2025We introduce MoLingo, a text-to-motion (T2M) model that generates realistic, lifelike human motion by denoising in a continuous latent space. Recent works perform latent space diffusion, either on the whole latent at once or auto-regressively over multiple latents. In this paper, we study how to make diffusion on continuous motion latents work best. We focus on two questions: (1) how to build a semantically aligned latent space so diffusion becomes more effective, and (2) how to best inject text conditioning so the motion follows the description closely. We propose a semantic-aligned motion encoder trained with frame-level text labels so that latents with similar text meaning stay close, which makes the latent space more diffusion-friendly. We also compare single-token conditioning with a multi-token cross-attention scheme and find that cross-attention gives better motion realism and text-motion alignment. With semantically aligned latents, auto-regressive generation, and cross-attention text conditioning, our model sets a new state of the art in human motion generation on standard metrics and in a user study. We will release our code and models for further research and downstream usage.
NRDF: Neural Riemannian Distance Fields for Learning Articulated Pose Priors
Mar 05, 2024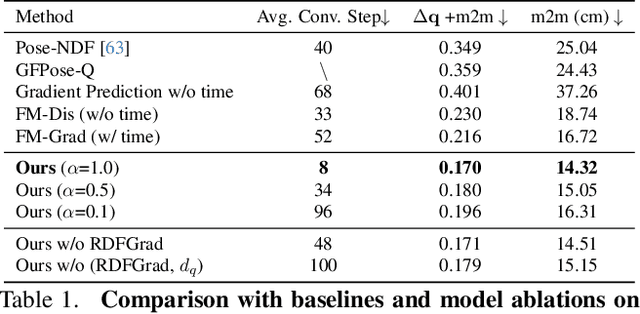
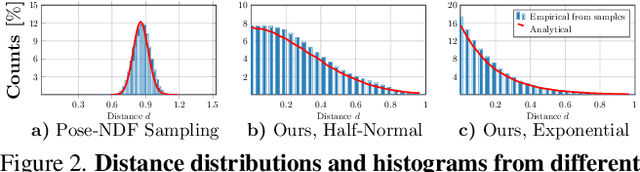
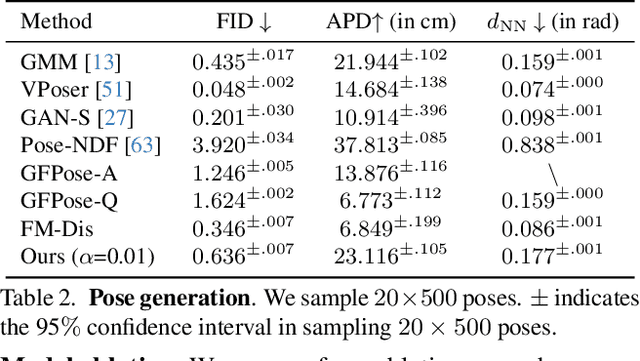
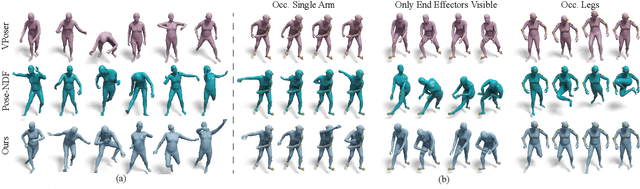
Faithfully modeling the space of articulations is a crucial task that allows recovery and generation of realistic poses, and remains a notorious challenge. To this end, we introduce Neural Riemannian Distance Fields (NRDFs), data-driven priors modeling the space of plausible articulations, represented as the zero-level-set of a neural field in a high-dimensional product-quaternion space. To train NRDFs only on positive examples, we introduce a new sampling algorithm, ensuring that the geodesic distances follow a desired distribution, yielding a principled distance field learning paradigm. We then devise a projection algorithm to map any random pose onto the level-set by an adaptive-step Riemannian optimizer, adhering to the product manifold of joint rotations at all times. NRDFs can compute the Riemannian gradient via backpropagation and by mathematical analogy, are related to Riemannian flow matching, a recent generative model. We conduct a comprehensive evaluation of NRDF against other pose priors in various downstream tasks, i.e., pose generation, image-based pose estimation, and solving inverse kinematics, highlighting NRDF's superior performance. Besides humans, NRDF's versatility extends to hand and animal poses, as it can effectively represent any articulation.
CloSe: A 3D Clothing Segmentation Dataset and Model
Jan 22, 2024



3D Clothing modeling and datasets play crucial role in the entertainment, animation, and digital fashion industries. Existing work often lacks detailed semantic understanding or uses synthetic datasets, lacking realism and personalization. To address this, we first introduce CloSe-D: a novel large-scale dataset containing 3D clothing segmentation of 3167 scans, covering a range of 18 distinct clothing classes. Additionally, we propose CloSe-Net, the first learning-based 3D clothing segmentation model for fine-grained segmentation from colored point clouds. CloSe-Net uses local point features, body-clothing correlation, and a garment-class and point features-based attention module, improving performance over baselines and prior work. The proposed attention module enables our model to learn appearance and geometry-dependent clothing prior from data. We further validate the efficacy of our approach by successfully segmenting publicly available datasets of people in clothing. We also introduce CloSe-T, a 3D interactive tool for refining segmentation labels. Combining the tool with CloSe-T in a continual learning setup demonstrates improved generalization on real-world data. Dataset, model, and tool can be found at https://virtualhumans.mpi-inf.mpg.de/close3dv24/.
Pose-NDF: Modeling Human Pose Manifolds with Neural Distance Fields
Jul 27, 2022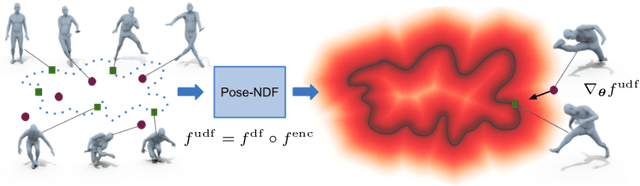
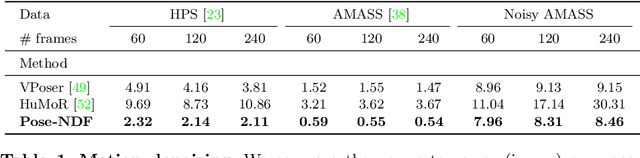
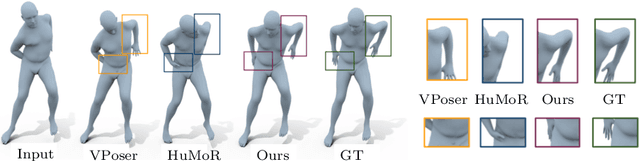
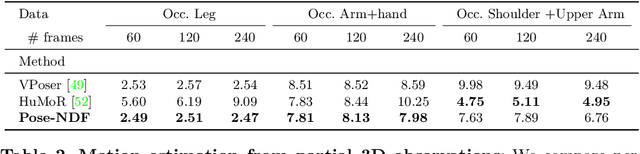
We present Pose-NDF, a continuous model for plausible human poses based on neural distance fields (NDFs). Pose or motion priors are important for generating realistic new poses and for reconstructing accurate poses from noisy or partial observations. Pose-NDF learns a manifold of plausible poses as the zero level set of a neural implicit function, extending the idea of modeling implicit surfaces in 3D to the high-dimensional domain SO(3)^K, where a human pose is defined by a single data point, represented by K quaternions. The resulting high-dimensional implicit function can be differentiated with respect to the input poses and thus can be used to project arbitrary poses onto the manifold by using gradient descent on the set of 3-dimensional hyperspheres. In contrast to previous VAE-based human pose priors, which transform the pose space into a Gaussian distribution, we model the actual pose manifold, preserving the distances between poses. We demonstrate that PoseNDF outperforms existing state-of-the-art methods as a prior in various downstream tasks, ranging from denoising real-world human mocap data, pose recovery from occluded data to 3D pose reconstruction from images. Furthermore, we show that it can be used to generate more diverse poses by random sampling and projection than VAE-based methods.
* Project page: https://virtualhumans.mpi-inf.mpg.de/posendf
Neural-GIF: Neural Generalized Implicit Functions for Animating People in Clothing
Aug 20, 2021
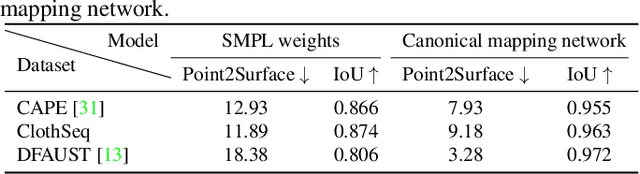


We present Neural Generalized Implicit Functions(Neural-GIF), to animate people in clothing as a function of the body pose. Given a sequence of scans of a subject in various poses, we learn to animate the character for new poses. Existing methods have relied on template-based representations of the human body (or clothing). However such models usually have fixed and limited resolutions, require difficult data pre-processing steps and cannot be used with complex clothing. We draw inspiration from template-based methods, which factorize motion into articulation and non-rigid deformation, but generalize this concept for implicit shape learning to obtain a more flexible model. We learn to map every point in the space to a canonical space, where a learned deformation field is applied to model non-rigid effects, before evaluating the signed distance field. Our formulation allows the learning of complex and non-rigid deformations of clothing and soft tissue, without computing a template registration as it is common with current approaches. Neural-GIF can be trained on raw 3D scans and reconstructs detailed complex surface geometry and deformations. Moreover, the model can generalize to new poses. We evaluate our method on a variety of characters from different public datasets in diverse clothing styles and show significant improvements over baseline methods, quantitatively and qualitatively. We also extend our model to multiple shape setting. To stimulate further research, we will make the model, code and data publicly available at: https://virtualhumans.mpi-inf.mpg.de/neuralgif/
SIZER: A Dataset and Model for Parsing 3D Clothing and Learning Size Sensitive 3D Clothing
Jul 22, 2020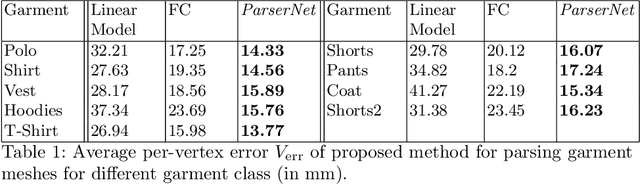
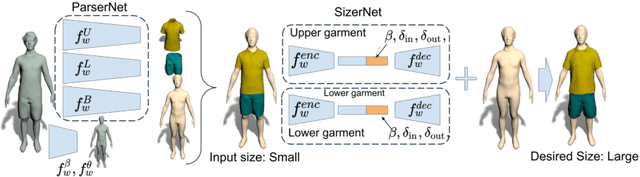
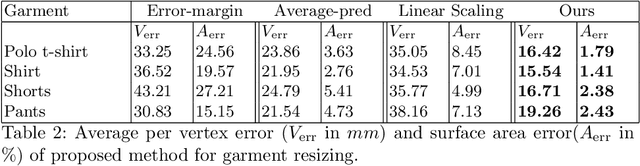
While models of 3D clothing learned from real data exist, no method can predict clothing deformation as a function of garment size. In this paper, we introduce SizerNet to predict 3D clothing conditioned on human body shape and garment size parameters, and ParserNet to infer garment meshes and shape under clothing with personal details in a single pass from an input mesh. SizerNet allows to estimate and visualize the dressing effect of a garment in various sizes, and ParserNet allows to edit clothing of an input mesh directly, removing the need for scan segmentation, which is a challenging problem in itself. To learn these models, we introduce the SIZER dataset of clothing size variation which includes $100$ different subjects wearing casual clothing items in various sizes, totaling to approximately 2000 scans. This dataset includes the scans, registrations to the SMPL model, scans segmented in clothing parts, garment category and size labels. Our experiments show better parsing accuracy and size prediction than baseline methods trained on SIZER. The code, model and dataset will be released for research purposes.
Multi-Garment Net: Learning to Dress 3D People from Images
Aug 20, 2019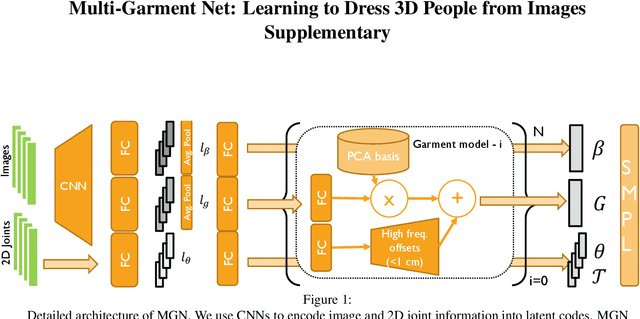
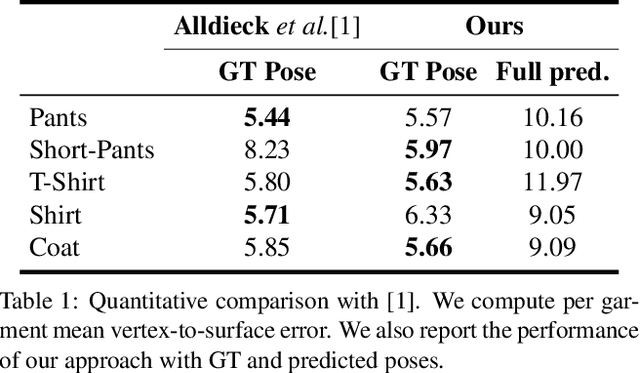
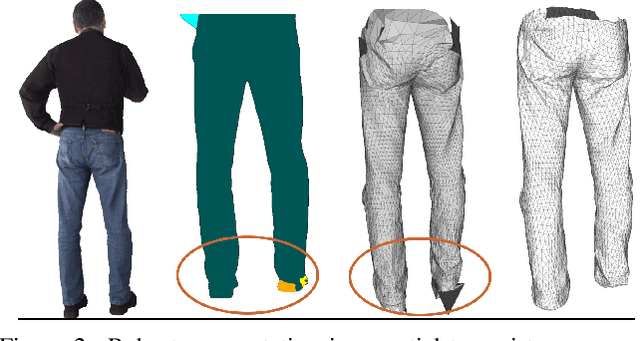
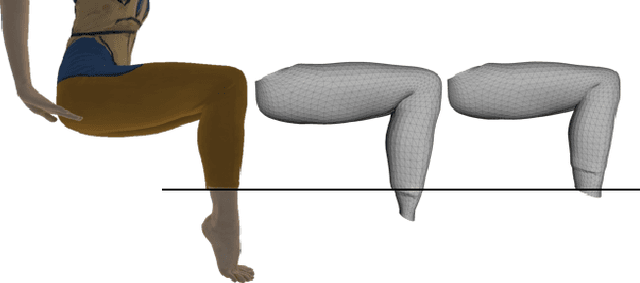
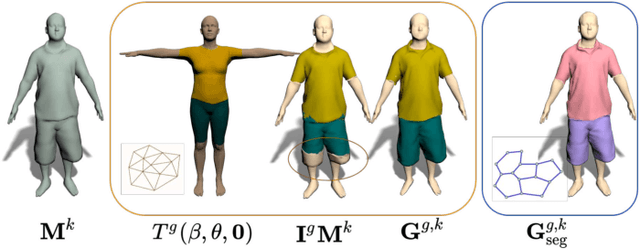
We present Multi-Garment Network (MGN), a method to predict body shape and clothing, layered on top of the SMPL model from a few frames (1-8) of a video. Several experiments demonstrate that this representation allows higher level of control when compared to single mesh or voxel representations of shape. Our model allows to predict garment geometry, relate it to the body shape, and transfer it to new body shapes and poses. To train MGN, we leverage a digital wardrobe containing 712 digital garments in correspondence, obtained with a novel method to register a set of clothing templates to a dataset of real 3D scans of people in different clothing and poses. Garments from the digital wardrobe, or predicted by MGN, can be used to dress any body shape in arbitrary poses. We will make publicly available the digital wardrobe, the MGN model, and code to dress SMPL with the garments.