 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Splatting in Style
Mar 13, 2024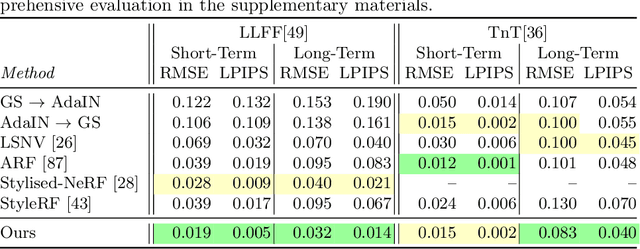


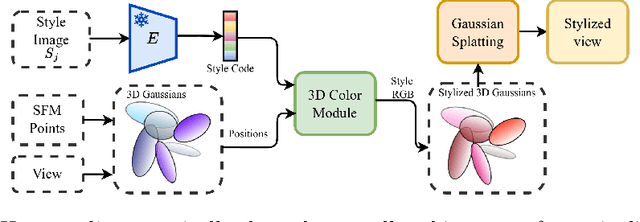
Scene stylization extends the work of neural style transfer to three spatial dimensions. A vital challenge in this problem is to maintain the uniformity of the stylized appearance across a multi-view setting. A vast majority of the previous works achieve this by optimizing the scene with a specific style image. In contrast, we propose a novel architecture trained on a collection of style images, that at test time produces high quality stylized novel views. Our work builds up on the framework of 3D Gaussian splatting. For a given scene, we take the pretrained Gaussians and process them using a multi resolution hash grid and a tiny MLP to obtain the conditional stylised views. The explicit nature of 3D Gaussians give us inherent advantages over NeRF-based methods including geometric consistency, along with having a fast training and rendering regime. This enables our method to be useful for vast practical use cases such as in augmented or virtual reality applications. Through our experiments, we show our methods achieve state-of-the-art performance with superior visual quality on various indoor and outdoor real-world data.
Urban-StyleGAN: Learning to Generate and Manipulate Images of Urban Scenes
May 16, 2023



A promise of Generative Adversarial Networks (GANs) is to provide cheap photorealistic data for training and validating AI models in autonomous driving. Despite their huge success, their performance on complex images featuring multiple objects is understudied. While some frameworks produce high-quality street scenes with little to no control over the image content, others offer more control at the expense of high-quality generation. A common limitation of both approaches is the use of global latent codes for the whole image, which hinders the learning of independent object distributions. Motivated by SemanticStyleGAN (SSG), a recent work on latent space disentanglement in human face generation, we propose a novel framework, Urban-StyleGAN, for urban scene generation and manipulation. We find that a straightforward application of SSG leads to poor results because urban scenes are more complex than human faces. To provide a more compact yet disentangled latent representation, we develop a class grouping strategy wherein individual classes are grouped into super-classes. Moreover, we employ an unsupervised latent exploration algorithm in the $\mathcal{S}$-space of the generator and show that it is more efficient than the conventional $\mathcal{W}^{+}$-space in controlling the image content. Results on the Cityscapes and Mapillary datasets show the proposed approach achieves significantly more controllability and improved image quality than previous approaches on urban scenes and is on par with general-purpose non-controllable generative models (like StyleGAN2) in terms of quality.
SupeRVol: Super-Resolution Shape and Reflectance Estimation in Inverse Volume Rendering
Dec 09, 2022



We propose an end-to-end inverse rendering pipeline called SupeRVol that allows us to recover 3D shape and material parameters from a set of color images in a super-resolution manner. To this end, we represent both the bidirectional reflectance distribution function (BRDF) and the signed distance function (SDF) by multi-layer perceptrons. In order to obtain both the surface shape and its reflectance properties, we revert to a differentiable volume renderer with a physically based illumination model that allows us to decouple reflectance and lighting. This physical model takes into account the effect of the camera's point spread function thereby enabling a reconstruction of shape and material in a super-resolution quality. Experimental validation confirms that SupeRVol achieves state of the art performance in terms of inverse rendering quality. It generates reconstructions that are sharper than the individual input images, making this method ideally suited for 3D modeling from low-resolution imagery.
Implicit Shape Completion via Adversarial Shape Priors
Apr 21, 2022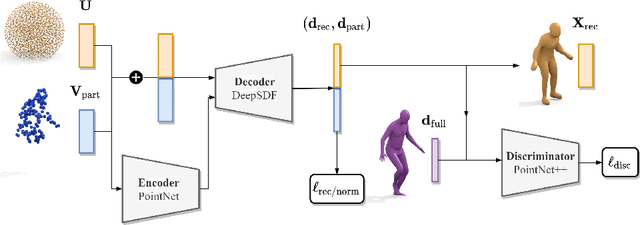

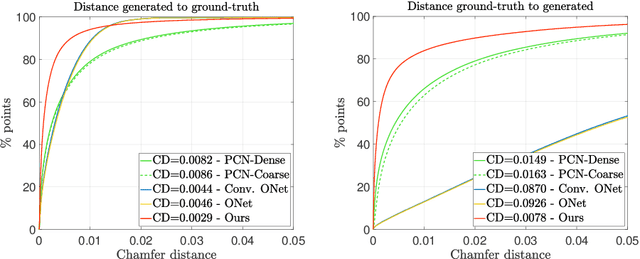

We present a novel neural implicit shape method for partial point cloud completion. To that end, we combine a conditional Deep-SDF architecture with learned, adversarial shape priors. More specifically, our network converts partial inputs into a global latent code and then recovers the full geometry via an implicit, signed distance generator. Additionally, we train a PointNet++ discriminator that impels the generator to produce plausible, globally consistent reconstructions. In that way, we effectively decouple the challenges of predicting shapes that are both realistic, i.e. imitate the training set's pose distribution, and accurate in the sense that they replicate the partial input observations. In our experiments, we demonstrate state-of-the-art performance for completing partial shapes, considering both man-made objects (e.g. airplanes, chairs, ...) and deformable shape categories (human bodies). Finally, we show that our adversarial training approach leads to visually plausible reconstructions that are highly consistent in recovering missing parts of a given object.
HDSDF: Hybrid Directional and Signed Distance Functions for Fast Inverse Rendering
Mar 30, 2022



Implicit neural representations of 3D shapes form strong priors that are useful for various applications, such as single and multiple view 3D reconstruction. A downside of existing neural representations is that they require multiple network evaluations for rendering, which leads to high computational costs. This limitation forms a bottleneck particularly in the context of inverse problems, such as image-based 3D reconstruction. To address this issue, in this paper (i) we propose a novel hybrid 3D object representation based on a signed distance function (SDF) that we augment with a directional distance function (DDF), so that we can predict distances to the object surface from any point on a sphere enclosing the object. Moreover, (ii) using the proposed hybrid representation we address the multi-view consistency problem common in existing DDF representations. We evaluate our novel hybrid representation on the task of single-view depth reconstruction and show that our method is several times faster compared to competing methods, while at the same time achieving better reconstruction accuracy.
Joint Deep Multi-Graph Matching and 3D Geometry Learning from Inhomogeneous 2D Image Collections
Mar 31, 2021
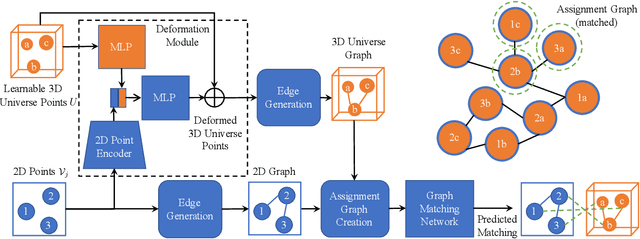


Graph matching aims to establish correspondences between vertices of graphs such that both the node and edge attributes agree. Various learning-based methods were recently proposed for finding correspondences between image key points based on deep graph matching formulations. While these approaches mainly focus on learning node and edge attributes, they completely ignore the 3D geometry of the underlying 3D objects depicted in the 2D images. We fill this gap by proposing a trainable framework that takes advantage of graph neural networks for learning a deformable 3D geometry model from inhomogeneous image collections, i.e. a set of images that depict different instances of objects from the same category. Experimentally we demonstrate that our method outperforms recent learning-based approaches for graph matching considering both accuracy and cycle-consistency error, while we in addition obtain the underlying 3D geometry of the objects depicted in the 2D images.
i3DMM: Deep Implicit 3D Morphable Model of Human Heads
Nov 28, 2020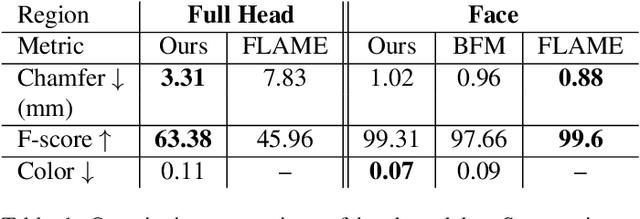


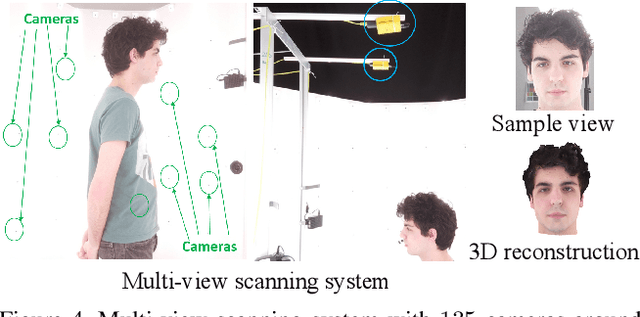
We present the first deep implicit 3D morphable model (i3DMM) of full heads. Unlike earlier morphable face models it not only captures identity-specific geometry, texture, and expressions of the frontal face, but also models the entire head, including hair. We collect a new dataset consisting of 64 people with different expressions and hairstyles to train i3DMM. Our approach has the following favorable properties: (i) It is the first full head morphable model that includes hair. (ii) In contrast to mesh-based models it can be trained on merely rigidly aligned scans, without requiring difficult non-rigid registration. (iii) We design a novel architecture to decouple the shape model into an implicit reference shape and a deformation of this reference shape. With that, dense correspondences between shapes can be learned implicitly. (iv) This architecture allows us to semantically disentangle the geometry and color components, as color is learned in the reference space. Geometry is further disentangled as identity, expressions, and hairstyle, while color is disentangled as identity and hairstyle components. We show the merits of i3DMM using ablation studies, comparisons to state-of-the-art models, and applications such as semantic head editing and texture transfer. We will make our model publicly available.
Convex Optimisation for Inverse Kinematics
Oct 24, 2019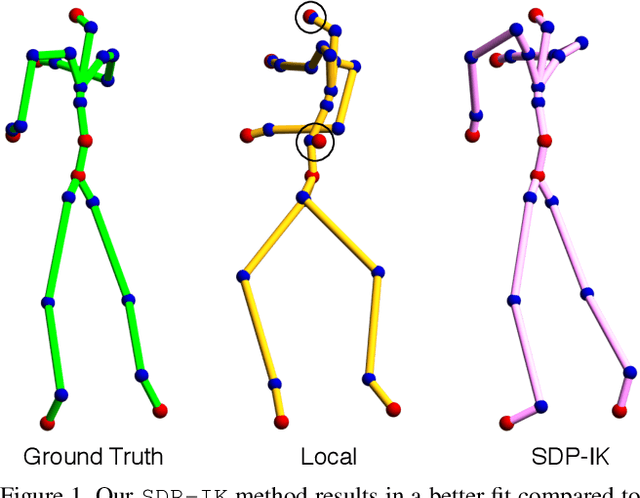
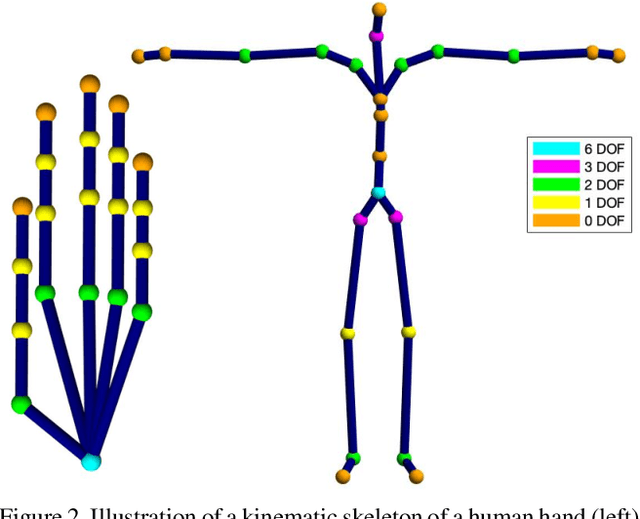
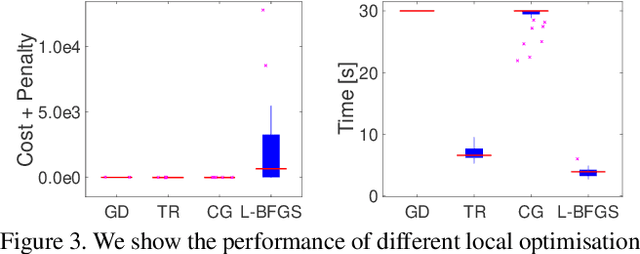
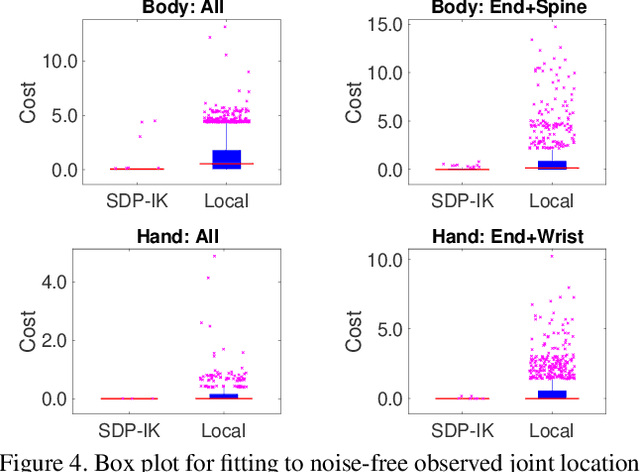
We consider the problem of inverse kinematics (IK), where one wants to find the parameters of a given kinematic skeleton that best explain a set of observed 3D joint locations. The kinematic skeleton has a tree structure, where each node is a joint that has an associated geometric transformation that is propagated to all its child nodes. The IK problem has various applications in vision and graphics, for example for tracking or reconstructing articulated objects, such as human hands or bodies. Most commonly, the IK problem is tackled using local optimisation methods. A major downside of these approaches is that, due to the non-convex nature of the problem, such methods are prone to converge to unwanted local optima and therefore require a good initialisation. In this paper we propose a convex optimisation approach for the IK problem based on semidefinite programming, which admits a polynomial-time algorithm that globally solves (a relaxation of) the IK problem. Experimentally, we demonstrate that the proposed method significantly outperforms local optimisation methods using different real-world skeletons.