 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Texture- And Shape-Independent 3D Keypoint Estimation in Birds
May 22, 2025In this paper, we present a texture-independent approach to estimate and track 3D joint positions of multiple pigeons. For this purpose, we build upon the existing 3D-MuPPET framework, which estimates and tracks the 3D poses of up to 10 pigeons using a multi-view camera setup. We extend this framework by using a segmentation method that generates silhouettes of the individuals, which are then used to estimate 2D keypoints. Following 3D-MuPPET, these 2D keypoints are triangulated to infer 3D poses, and identities are matched in the first frame and tracked in 2D across subsequent frames. Our proposed texture-independent approach achieves comparable accuracy to the original texture-dependent 3D-MuPPET framework. Additionally, we explore our approach's applicability to other bird species. To do that, we infer the 2D joint positions of four bird species without additional fine-tuning the model trained on pigeons and obtain preliminary promising results. Thus, we think that our approach serves as a solid foundation and inspires the development of more robust and accurate texture-independent pose estimation frameworks.
Sparse Views, Near Light: A Practical Paradigm for Uncalibrated Point-light Photometric Stereo
Mar 29, 2024Neural approaches have shown a significant progress on camera-based reconstruction. But they require either a fairly dense sampling of the viewing sphere, or pre-training on an existing dataset, thereby limiting their generalizability. In contrast, photometric stereo (PS) approaches have shown great potential for achieving high-quality reconstruction under sparse viewpoints. Yet, they are impractical because they typically require tedious laboratory conditions, are restricted to dark rooms, and often multi-staged, making them subject to accumulated errors. To address these shortcomings, we propose an end-to-end uncalibrated multi-view PS framework for reconstructing high-resolution shapes acquired from sparse viewpoints in a real-world environment. We relax the dark room assumption, and allow a combination of static ambient lighting and dynamic near LED lighting, thereby enabling easy data capture outside the lab. Experimental validation confirms that it outperforms existing baseline approaches in the regime of sparse viewpoints by a large margin. This allows to bring high-accuracy 3D reconstruction from the dark room to the real world, while maintaining a reasonable data capture complexity.
Neural Texture Puppeteer: A Framework for Neural Geometry and Texture Rendering of Articulated Shapes, Enabling Re-Identification at Interactive Speed
Nov 28, 2023In this paper, we present a neural rendering pipeline for textured articulated shapes that we call Neural Texture Puppeteer. Our method separates geometry and texture encoding. The geometry pipeline learns to capture spatial relationships on the surface of the articulated shape from ground truth data that provides this geometric information. A texture auto-encoder makes use of this information to encode textured images into a global latent code. This global texture embedding can be efficiently trained separately from the geometry, and used in a downstream task to identify individuals. The neural texture rendering and the identification of individuals run at interactive speeds. To the best of our knowledge, we are the first to offer a promising alternative to CNN- or transformer-based approaches for re-identification of articulated individuals based on neural rendering. Realistic looking novel view and pose synthesis for different synthetic cow textures further demonstrate the quality of our method. Restricted by the availability of ground truth data for the articulated shape's geometry, the quality for real-world data synthesis is reduced. We further demonstrate the flexibility of our model for real-world data by applying a synthetic to real-world texture domain shift where we reconstruct the texture from a real-world 2D RGB image. Thus, our method can be applied to endangered species where data is limited. Our novel synthetic texture dataset NePuMoo is publicly available to inspire further development in the field of neural rendering-based re-identification.
3D-MuPPET: 3D Multi-Pigeon Pose Estimation and Tracking
Aug 29, 2023
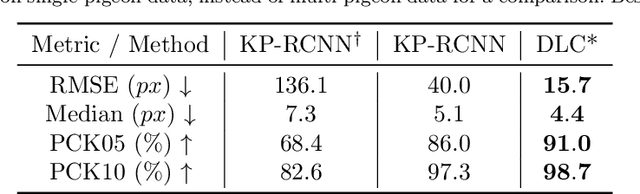
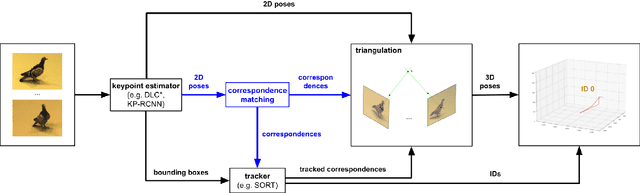

Markerless methods for animal posture tracking have been developing recently, but frameworks and benchmarks for tracking large animal groups in 3D are still lacking. To overcome this gap in the literature, we present 3D-MuPPET, a framework to estimate and track 3D poses of up to 10 pigeons at interactive speed using multiple-views. We train a pose estimator to infer 2D keypoints and bounding boxes of multiple pigeons, then triangulate the keypoints to 3D. For correspondence matching, we first dynamically match 2D detections to global identities in the first frame, then use a 2D tracker to maintain correspondences accross views in subsequent frames. We achieve comparable accuracy to a state of the art 3D pose estimator for Root Mean Square Error (RMSE) and Percentage of Correct Keypoints (PCK). We also showcase a novel use case where our model trained with data of single pigeons provides comparable results on data containing multiple pigeons. This can simplify the domain shift to new species because annotating single animal data is less labour intensive than multi-animal data. Additionally, we benchmark the inference speed of 3D-MuPPET, with up to 10 fps in 2D and 1.5 fps in 3D, and perform quantitative tracking evaluation, which yields encouraging results. Finally, we show that 3D-MuPPET also works in natural environments without model fine-tuning on additional annotations. To the best of our knowledge we are the first to present a framework for 2D/3D posture and trajectory tracking that works in both indoor and outdoor environments.
Towards Monocular Shape from Refraction
May 31, 2023Refraction is a common physical phenomenon and has long been researched in computer vision. Objects imaged through a refractive object appear distorted in the image as a function of the shape of the interface between the media. This hinders many computer vision applications, but can be utilized for obtaining the geometry of the refractive interface. Previous approaches for refractive surface recovery largely relied on various priors or additional information like multiple images of the analyzed surface. In contrast, we claim that a simple energy function based on Snell's law enables the reconstruction of an arbitrary refractive surface geometry using just a single image and known background texture and geometry. In the case of a single point, Snell's law has two degrees of freedom, therefore to estimate a surface depth, we need additional information. We show that solving for an entire surface at once introduces implicit parameter-free spatial regularization and yields convincing results when an intelligent initial guess is provided. We demonstrate our approach through simulations and real-world experiments, where the reconstruction shows encouraging results in the single-frame monocular setting.
* 12 pages, 6 figures, The 32nd British Machine Vision Conference (BMVC)
SupeRVol: Super-Resolution Shape and Reflectance Estimation in Inverse Volume Rendering
Dec 09, 2022



We propose an end-to-end inverse rendering pipeline called SupeRVol that allows us to recover 3D shape and material parameters from a set of color images in a super-resolution manner. To this end, we represent both the bidirectional reflectance distribution function (BRDF) and the signed distance function (SDF) by multi-layer perceptrons. In order to obtain both the surface shape and its reflectance properties, we revert to a differentiable volume renderer with a physically based illumination model that allows us to decouple reflectance and lighting. This physical model takes into account the effect of the camera's point spread function thereby enabling a reconstruction of shape and material in a super-resolution quality. Experimental validation confirms that SupeRVol achieves state of the art performance in terms of inverse rendering quality. It generates reconstructions that are sharper than the individual input images, making this method ideally suited for 3D modeling from low-resolution imagery.
GenDR: A Generalized Differentiable Renderer
Apr 29, 2022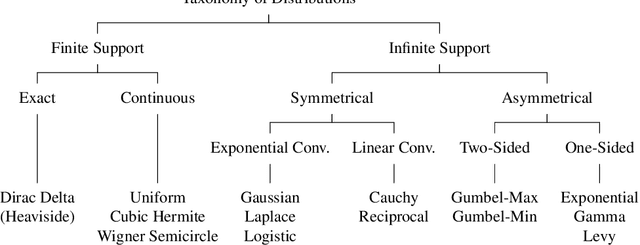
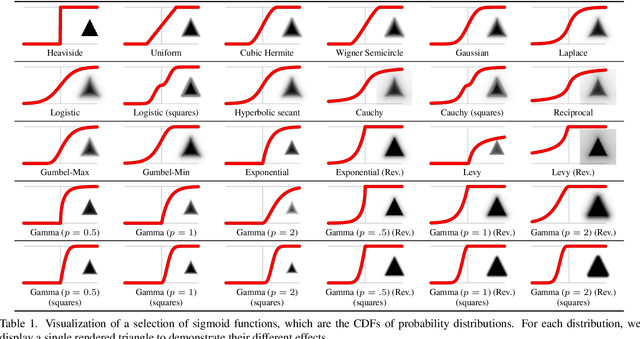
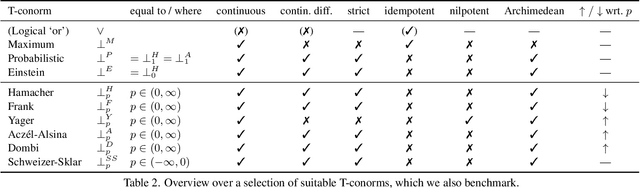
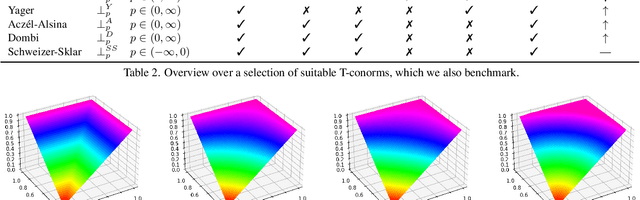
In this work, we present and study a generalized family of differentiable renderers. We discuss from scratch which components are necessary for differentiable rendering and formalize the requirements for each component. We instantiate our general differentiable renderer, which generalizes existing differentiable renderers like SoftRas and DIB-R, with an array of different smoothing distributions to cover a large spectrum of reasonable settings. We evaluate an array of differentiable renderer instantiations on the popular ShapeNet 3D reconstruction benchmark and analyze the implications of our results. Surprisingly, the simple uniform distribution yields the best overall results when averaged over 13 classes; in general, however, the optimal choice of distribution heavily depends on the task.
Style Agnostic 3D Reconstruction via Adversarial Style Transfer
Oct 20, 2021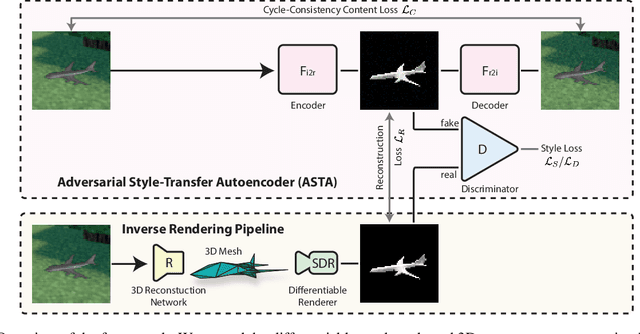
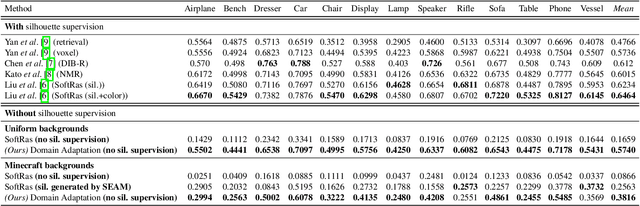
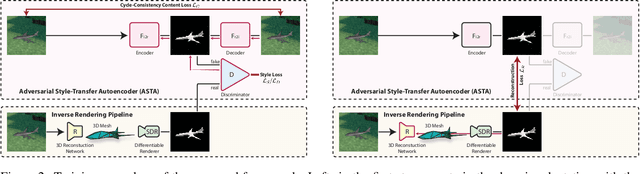

Reconstructing the 3D geometry of an object from an image is a major challenge in computer vision. Recently introduced differentiable renderers can be leveraged to learn the 3D geometry of objects from 2D images, but those approaches require additional supervision to enable the renderer to produce an output that can be compared to the input image. This can be scene information or constraints such as object silhouettes, uniform backgrounds, material, texture, and lighting. In this paper, we propose an approach that enables a differentiable rendering-based learning of 3D objects from images with backgrounds without the need for silhouette supervision. Instead of trying to render an image close to the input, we propose an adversarial style-transfer and domain adaptation pipeline that allows to translate the input image domain to the rendered image domain. This allows us to directly compare between a translated image and the differentiable rendering of a 3D object reconstruction in order to train the 3D object reconstruction network. We show that the approach learns 3D geometry from images with backgrounds and provides a better performance than constrained methods for single-view 3D object reconstruction on this task.