 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Agnostic 3D Reconstruction via Adversarial Style Transfer
Paper and Code
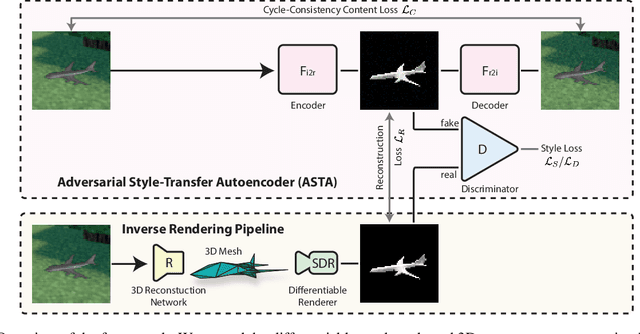
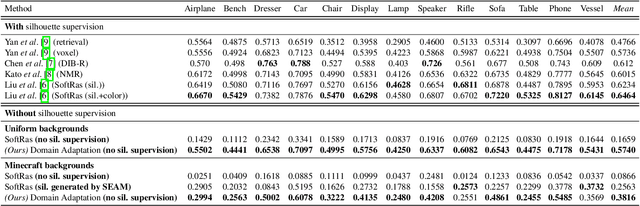
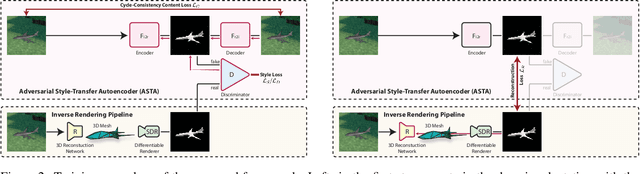

Reconstructing the 3D geometry of an object from an image is a major challenge in computer vision. Recently introduced differentiable renderers can be leveraged to learn the 3D geometry of objects from 2D images, but those approaches require additional supervision to enable the renderer to produce an output that can be compared to the input image. This can be scene information or constraints such as object silhouettes, uniform backgrounds, material, texture, and lighting. In this paper, we propose an approach that enables a differentiable rendering-based learning of 3D objects from images with backgrounds without the need for silhouette supervision. Instead of trying to render an image close to the input, we propose an adversarial style-transfer and domain adaptation pipeline that allows to translate the input image domain to the rendered image domain. This allows us to directly compare between a translated image and the differentiable rendering of a 3D object reconstruction in order to train the 3D object reconstruction network. We show that the approach learns 3D geometry from images with backgrounds and provides a better performance than constrained methods for single-view 3D object reconstruction on this task.