 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pixels: Visual Metaphor Transfer via Schema-Driven Agentic Reasoning
Feb 01, 2026A visual metaphor constitutes a high-order form of human creativity, employing cross-domain semantic fusion to transform abstract concepts into impactful visual rhetoric. Despite the remarkable progress of generative AI, existing models remain largely confined to pixel-level instruction alignment and surface-level appearance preservation, failing to capture the underlying abstract logic necessary for genuine metaphorical generation. To bridge this gap, we introduce the task of Visual Metaphor Transfer (VMT), which challenges models to autonomously decouple the "creative essence" from a reference image and re-materialize that abstract logic onto a user-specified target subject. We propose a cognitive-inspired, multi-agent framework that operationalizes Conceptual Blending Theory (CBT) through a novel Schema Grammar ("G"). This structured representation decouples relational invariants from specific visual entities, providing a rigorous foundation for cross-domain logic re-instantiation. Our pipeline executes VMT through a collaborative system of specialized agents: a perception agent that distills the reference into a schema, a transfer agent that maintains generic space invariance to discover apt carriers, a generation agent for high-fidelity synthesis and a hierarchical diagnostic agent that mimics a professional critic, performing closed-loop backtracking to identify and rectify errors across abstract logic, component selection, and prompt encoding. Extensive experiments and human evaluations demonstrate that our method significantly outperforms SOTA baselines in metaphor consistency, analogy appropriateness, and visual creativity, paving the way for automated high-impact creative applications in advertising and media. Source code will be made publicly available.
Neural Image Abstraction Using Long Smoothing B-Splines
Nov 07, 2025We integrate smoothing B-splines into a standard differentiable vector graphics (DiffVG) pipeline through linear mapping, and show how this can be used to generate smooth and arbitrarily long paths within image-based deep learning systems. We take advantage of derivative-based smoothing costs for parametric control of fidelity vs. simplicity tradeoffs, while also enabling stylization control in geometric and image spaces. The proposed pipeline is compatible with recent vector graphics generation and vectorization methods. We demonstrate the versatility of our approach with four applications aimed at the generation of stylized vector graphics: stylized space-filling path generation, stroke-based image abstraction, closed-area image abstraction, and stylized text generation.
In-Context Brush: Zero-shot Customized Subject Insertion with Context-Aware Latent Space Manipulation
May 26, 2025Recent advances in diffusion models have enhanced multimodal-guided visual generation, enabling customized subject insertion that seamlessly "brushes" user-specified objects into a given image guided by textual prompts. However, existing methods often struggle to insert customized subjects with high fidelity and align results with the user's intent through textual prompts. In this work, we propose "In-Context Brush", a zero-shot framework for customized subject insertion by reformulating the task within the paradigm of in-context learning. Without loss of generality, we formulate the object image and the textual prompts as cross-modal demonstrations, and the target image with the masked region as the query. The goal is to inpaint the target image with the subject aligning textual prompts without model tuning. Building upon a pretrained MMDiT-based inpainting network, we perform test-time enhancement via dual-level latent space manipulation: intra-head "latent feature shifting" within each attention head that dynamically shifts attention outputs to reflect the desired subject semantics and inter-head "attention reweighting" across different heads that amplifies prompt controllability through differential attention prioritization. Extensive experiments and applications demonstrate that our approach achieves superior identity preservation, text alignment, and image quality compared to existing state-of-the-art methods, without requiring dedicated training or additional data collection.
Bringing Characters to New Stories: Training-Free Theme-Specific Image Generation via Dynamic Visual Prompting
Jan 26, 2025



The stories and characters that captivate us as we grow up shape unique fantasy worlds, with images serving as the primary medium for visually experiencing these realms. Personalizing generative models through fine-tuning with theme-specific data has become a prevalent approach in text-to-image generation. However, unlike object customization, which focuses on learning specific objects, theme-specific generation encompasses diverse elements such as characters, scenes, and objects. Such diversity also introduces a key challenge: how to adaptively generate multi-character, multi-concept, and continuous theme-specific images (TSI). Moreover, fine-tuning approaches often come with significant computational overhead, time costs, and risks of overfitting. This paper explores a fundamental question: Can image generation models directly leverage images as contextual input, similarly to how large language models use text as context? To address this, we present T-Prompter, a novel training-free TSI method for generation. T-Prompter introduces visual prompting, a mechanism that integrates reference images into generative models, allowing users to seamlessly specify the target theme without requiring additional training. To further enhance this process, we propose a Dynamic Visual Prompting (DVP) mechanism, which iteratively optimizes visual prompts to improve the accuracy and quality of generated images. Our approach enables diverse applications, including consistent story generation, character design, realistic character generation, and style-guided image generation. Comparative evaluations against state-of-the-art personalization methods demonstrate that T-Prompter achieves significantly better results and excels in maintaining character identity preserving, style consistency and text alignment, offering a robust and flexible solution for theme-specific image generation.
Mesh2SLAM in VR: A Fast Geometry-Based SLAM Framework for Rapid Prototyping in Virtual Reality Applications
Jan 16, 2025SLAM is a foundational technique with broad applications in robotics and AR/VR. SLAM simulations evaluate new concepts, but testing on resource-constrained devices, such as VR HMDs, faces challenges: high computational cost and restricted sensor data access. This work proposes a sparse framework using mesh geometry projections as features, which improves efficiency and circumvents direct sensor data access, advancing SLAM research as we demonstrate in VR and through numerical evaluation.
HeadRouter: A Training-free Image Editing Framework for MM-DiTs by Adaptively Routing Attention Heads
Nov 22, 2024



Diffusion Transformers (DiTs) have exhibited robust capabilities in image generation tasks. However, accurate text-guided image editing for multimodal DiTs (MM-DiTs) still poses a significant challenge. Unlike UNet-based structures that could utilize self/cross-attention maps for semantic editing, MM-DiTs inherently lack support for explicit and consistent incorporated text guidance, resulting in semantic misalignment between the edited results and texts. In this study, we disclose the sensitivity of different attention heads to different image semantics within MM-DiTs and introduce HeadRouter, a training-free image editing framework that edits the source image by adaptively routing the text guidance to different attention heads in MM-DiTs. Furthermore, we present a dual-token refinement module to refine text/image token representations for precise semantic guidance and accurate region expression. Experimental results on multiple benchmarks demonstrate HeadRouter's performance in terms of editing fidelity and image quality.
Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms
Oct 24, 2024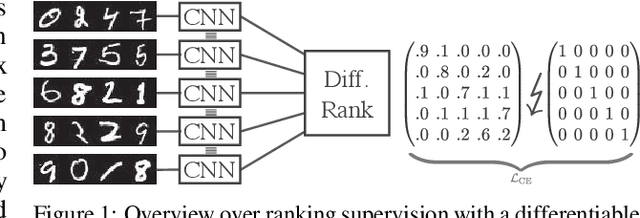
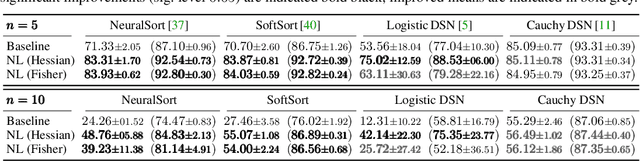


When training neural networks with custom objectives, such as ranking losses and shortest-path losses, a common problem is that they are, per se, non-differentiable. A popular approach is to continuously relax the objectives to provide gradients, enabling learning. However, such differentiable relaxations are often non-convex and can exhibit vanishing and exploding gradients, making them (already in isolation) hard to optimize. Here, the loss function poses the bottleneck when training a deep neural network. We present Newton Losses, a method for improving the performance of existing hard to optimize losses by exploiting their second-order information via their empirical Fisher and Hessian matrices. Instead of training the neural network with second-order techniques, we only utilize the loss function's second-order information to replace it by a Newton Loss, while training the network with gradient descent. This makes our method computationally efficient. We apply Newton Losses to eight differentiable algorithms for sorting and shortest-paths, achieving significant improvements for less-optimized differentiable algorithms, and consistent improvements, even for well-optimized differentiable algorithms.
Break-for-Make: Modular Low-Rank Adaptations for Composable Content-Style Customization
Mar 31, 2024



Personalized generation paradigms empower designers to customize visual intellectual properties with the help of textual descriptions by tuning or adapting pre-trained text-to-image models on a few images. Recent works explore approaches for concurrently customizing both content and detailed visual style appearance. However, these existing approaches often generate images where the content and style are entangled. In this study, we reconsider the customization of content and style concepts from the perspective of parameter space construction. Unlike existing methods that utilize a shared parameter space for content and style, we propose a learning framework that separates the parameter space to facilitate individual learning of content and style, thereby enabling disentangled content and style. To achieve this goal, we introduce "partly learnable projection" (PLP) matrices to separate the original adapters into divided sub-parameter spaces. We propose "break-for-make" customization learning pipeline based on PLP, which is simple yet effective. We break the original adapters into "up projection" and "down projection", train content and style PLPs individually with the guidance of corresponding textual prompts in the separate adapters, and maintain generalization by employing a multi-correspondence projection learning strategy. Based on the adapters broken apart for separate training content and style, we then make the entity parameter space by reconstructing the content and style PLPs matrices, followed by fine-tuning the combined adapter to generate the target object with the desired appearance. Experiments on various styles, including textures, materials, and artistic style, show that our method outperforms state-of-the-art single/multiple concept learning pipelines in terms of content-style-prompt alignment.
generAItor: Tree-in-the-Loop Text Generation for Language Model Explainability and Adaptation
Mar 12, 2024



Large language models (LLMs) are widely deployed in various downstream tasks, e.g., auto-completion, aided writing, or chat-based text generation. However, the considered output candidates of the underlying search algorithm are under-explored and under-explained. We tackle this shortcoming by proposing a tree-in-the-loop approach, where a visual representation of the beam search tree is the central component for analyzing, explaining, and adapting the generated outputs. To support these tasks, we present generAItor, a visual analytics technique, augmenting the central beam search tree with various task-specific widgets, providing targeted visualizations and interaction possibilities. Our approach allows interactions on multiple levels and offers an iterative pipeline that encompasses generating, exploring, and comparing output candidates, as well as fine-tuning the model based on adapted data. Our case study shows that our tool generates new insights in gender bias analysis beyond state-of-the-art template-based methods. Additionally, we demonstrate the applicability of our approach in a qualitative user study. Finally, we quantitatively evaluate the adaptability of the model to few samples, as occurring in text-generation use cases.
Uncertainty Quantification via Stable Distribution Propagation
Feb 13, 2024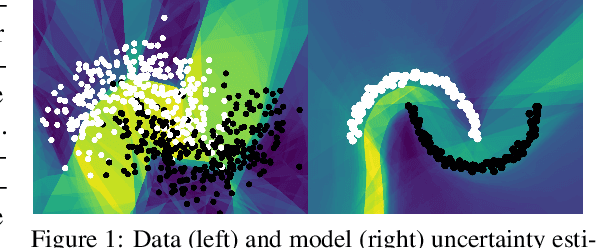

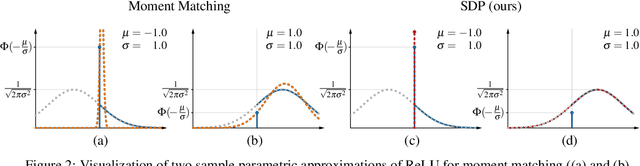

We propose a new approach for propagating stable probability distributions through neural networks. Our method is based on local linearization, which we show to be an optimal approximation in terms of total variation distance for the ReLU non-linearity. This allows propagating Gaussian and Cauchy input uncertainties through neural networks to quantify their output uncertainties. To demonstrate the utility of propagating distributions, we apply the proposed method to predicting calibrated confidence intervals and selective prediction on out-of-distribution data. The results demonstrate a broad applicability of propagating distributions and show the advantages of our method over other approaches such as moment matching.