 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Decision Support System for Energy-Efficient Ferry Operation on Lake Constance based on Optimal Control
Dec 12, 2025The maritime sector is undergoing a disruptive technological change driven by three main factors: autonomy, decarbonization, and digital transformation. Addressing these factors necessitates a reassessment of inland vessel operations. This paper presents the design and development of a decision support system for ferry operations based on a shrinking-horizon optimal control framework. The problem formulation incorporates a mathematical model of the ferry's dynamics and environmental disturbances, specifically water currents and wind, which can significantly influence the dynamics. Real-world data and illustrative scenarios demonstrate the potential of the proposed system to effectively support ferry crews by providing real-time guidance. This enables enhanced operational efficiency while maintaining predefined maneuver durations. The findings suggest that optimal control applications hold substantial promise for advancing future ferry operations on inland waters. A video of the real-world ferry MS Insel Mainau operating on Lake Constance is available at: https://youtu.be/i1MjCdbEQyE
Evaluating Keyframe Layouts for Visual Known-Item Search in Homogeneous Collections
Oct 05, 2025Multimodal deep-learning models power interactive video retrieval by ranking keyframes in response to textual queries. Despite these advances, users must still browse ranked candidates manually to locate a target. Keyframe arrangement within the search grid highly affects browsing effectiveness and user efficiency, yet remains underexplored. We report a study with 49 participants evaluating seven keyframe layouts for the Visual Known-Item Search task. Beyond efficiency and accuracy, we relate browsing phenomena, such as overlooks, to layout characteristics. Our results show that a video-grouped layout is the most efficient, while a four-column, rank-preserving grid achieves the highest accuracy. Sorted grids reveal potentials and trade-offs, enabling rapid scanning of uninteresting regions but down-ranking relevant targets to less prominent positions, delaying first arrival times and increasing overlooks. These findings motivate hybrid designs that preserve positions of top-ranked items while sorting or grouping the remainder, and offer guidance for searching in grids beyond video retrieval.
Experimental Evaluation of Static Image Sub-Region-Based Search Models Using CLIP
Jun 07, 2025



Advances in multimodal text-image models have enabled effective text-based querying in extensive image collections. While these models show convincing performance for everyday life scenes, querying in highly homogeneous, specialized domains remains challenging. The primary problem is that users can often provide only vague textual descriptions as they lack expert knowledge to discriminate between homogenous entities. This work investigates whether adding location-based prompts to complement these vague text queries can enhance retrieval performance. Specifically, we collected a dataset of 741 human annotations, each containing short and long textual descriptions and bounding boxes indicating regions of interest in challenging underwater scenes. Using these annotations, we evaluate the performance of CLIP when queried on various static sub-regions of images compared to the full image. Our results show that both a simple 3-by-3 partitioning and a 5-grid overlap significantly improve retrieval effectiveness and remain robust to perturbations of the annotation box.
Evaluating Autoencoders for Parametric and Invertible Multidimensional Projections
Apr 23, 2025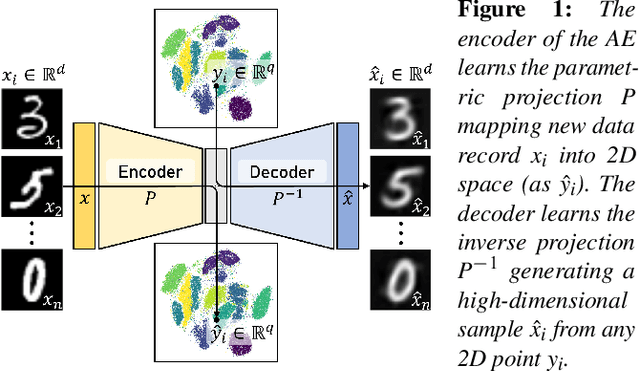
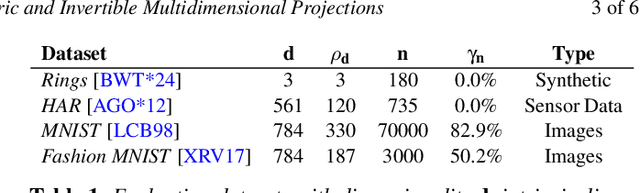
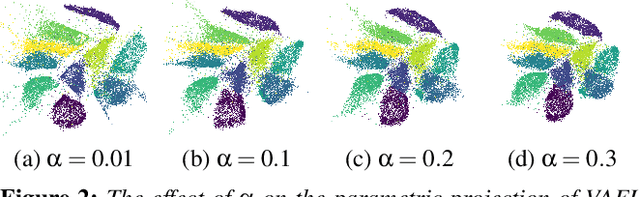
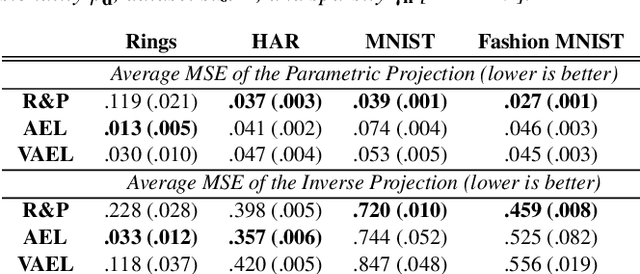
Recently, neural networks have gained attention for creating parametric and invertible multidimensional data projections. Parametric projections allow for embedding previously unseen data without recomputing the projection as a whole, while invertible projections enable the generation of new data points. However, these properties have never been explored simultaneously for arbitrary projection methods. We evaluate three autoencoder (AE) architectures for creating parametric and invertible projections. Based on a given projection, we train AEs to learn a mapping into 2D space and an inverse mapping into the original space. We perform a quantitative and qualitative comparison on four datasets of varying dimensionality and pattern complexity using t-SNE. Our results indicate that AEs with a customized loss function can create smoother parametric and inverse projections than feed-forward neural networks while giving users control over the strength of the smoothing effect.
A Multimedia Analytics Model for the Foundation Model Era
Apr 10, 2025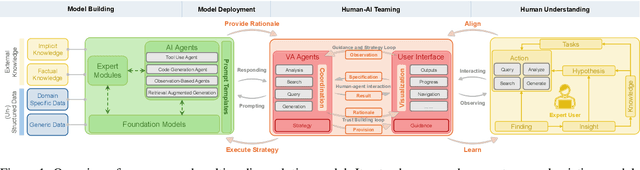
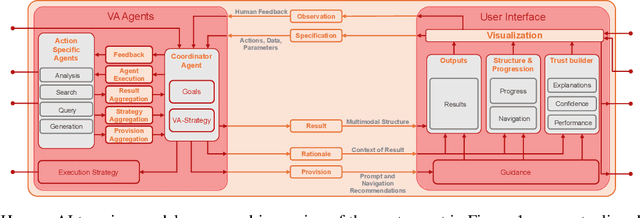
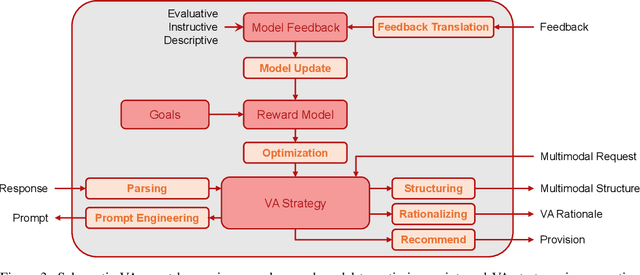
The rapid advances in Foundation Models and agentic Artificial Intelligence are transforming multimedia analytics by enabling richer, more sophisticated interactions between humans and analytical systems. Existing conceptual models for visual and multimedia analytics, however, do not adequately capture the complexity introduced by these powerful AI paradigms. To bridge this gap, we propose a comprehensive multimedia analytics model specifically designed for the foundation model era. Building upon established frameworks from visual analytics, multimedia analytics, knowledge generation, analytic task definition, mixed-initiative guidance, and human-in-the-loop reinforcement learning, our model emphasizes integrated human-AI teaming based on visual analytics agents from both technical and conceptual perspectives. Central to the model is a seamless, yet explicitly separable, interaction channel between expert users and semi-autonomous analytical processes, ensuring continuous alignment between user intent and AI behavior. The model addresses practical challenges in sensitive domains such as intelligence analysis, investigative journalism, and other fields handling complex, high-stakes data. We illustrate through detailed case studies how our model facilitates deeper understanding and targeted improvement of multimedia analytics solutions. By explicitly capturing how expert users can optimally interact with and guide AI-powered multimedia analytics systems, our conceptual framework sets a clear direction for system design, comparison, and future research.
Leveraging Color Channel Independence for Improved Unsupervised Object Detection
Dec 19, 2024


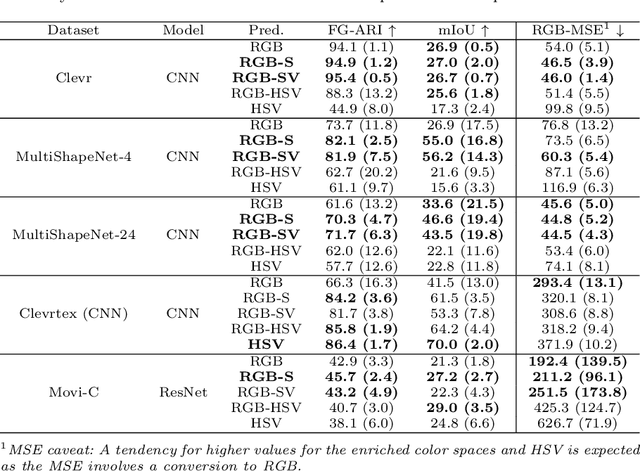
Object-centric architectures can learn to extract distinct object representations from visual scenes, enabling downstream applications on the object level. Similarly to autoencoder-based image models, object-centric approaches have been trained on the unsupervised reconstruction loss of images encoded by RGB color spaces. In our work, we challenge the common assumption that RGB images are the optimal color space for unsupervised learning in computer vision. We discuss conceptually and empirically that other color spaces, such as HSV, bear essential characteristics for object-centric representation learning, like robustness to lighting conditions. We further show that models improve when requiring them to predict additional color channels. Specifically, we propose to transform the predicted targets to the RGB-S space, which extends RGB with HSV's saturation component and leads to markedly better reconstruction and disentanglement for five common evaluation datasets. The use of composite color spaces can be implemented with basically no computational overhead, is agnostic of the models' architecture, and is universally applicable across a wide range of visual computing tasks and training types. The findings of our approach encourage additional investigations in computer vision tasks beyond object-centric learning.
Interactive dense pixel visualizations for time series and model attribution explanations
Aug 27, 2024

The field of Explainable Artificial Intelligence (XAI) for Deep Neural Network models has developed significantly, offering numerous techniques to extract explanations from models. However, evaluating explanations is often not trivial, and differences in applied metrics can be subtle, especially with non-intelligible data. Thus, there is a need for visualizations tailored to explore explanations for domains with such data, e.g., time series. We propose DAVOTS, an interactive visual analytics approach to explore raw time series data, activations of neural networks, and attributions in a dense-pixel visualization to gain insights into the data, models' decisions, and explanations. To further support users in exploring large datasets, we apply clustering approaches to the visualized data domains to highlight groups and present ordering strategies for individual and combined data exploration to facilitate finding patterns. We visualize a CNN trained on the FordA dataset to demonstrate the approach.
Interactive Counterfactual Generation for Univariate Time Series
Aug 20, 2024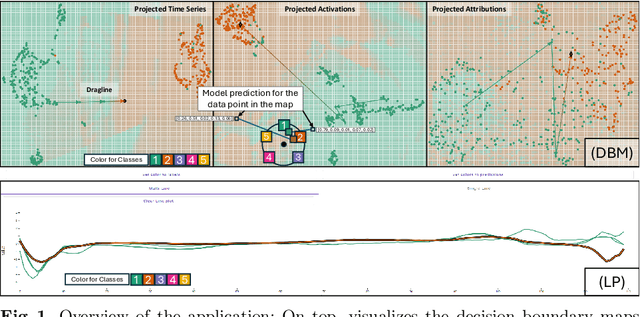
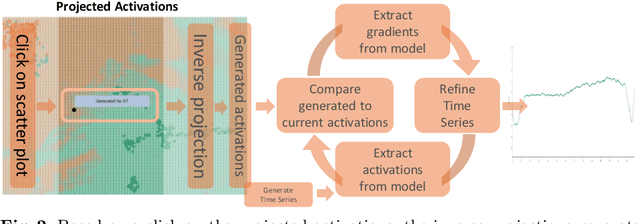
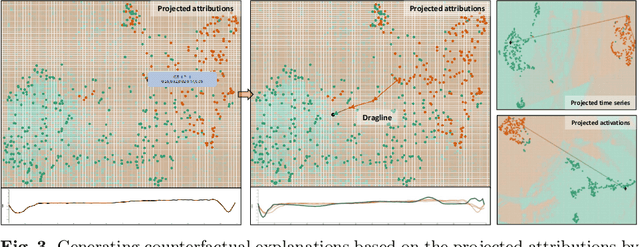
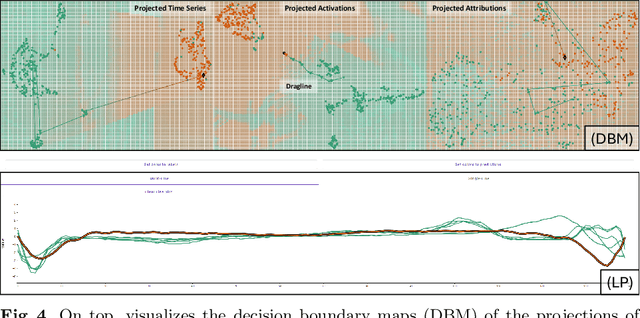
We propose an interactive methodology for generating counterfactual explanations for univariate time series data in classification tasks by leveraging 2D projections and decision boundary maps to tackle interpretability challenges. Our approach aims to enhance the transparency and understanding of deep learning models' decision processes. The application simplifies the time series data analysis by enabling users to interactively manipulate projected data points, providing intuitive insights through inverse projection techniques. By abstracting user interactions with the projected data points rather than the raw time series data, our method facilitates an intuitive generation of counterfactual explanations. This approach allows for a more straightforward exploration of univariate time series data, enabling users to manipulate data points to comprehend potential outcomes of hypothetical scenarios. We validate this method using the ECG5000 benchmark dataset, demonstrating significant improvements in interpretability and user understanding of time series classification. The results indicate a promising direction for enhancing explainable AI, with potential applications in various domains requiring transparent and interpretable deep learning models. Future work will explore the scalability of this method to multivariate time series data and its integration with other interpretability techniques.
Finding the DeepDream for Time Series: Activation Maximization for Univariate Time Series
Aug 20, 2024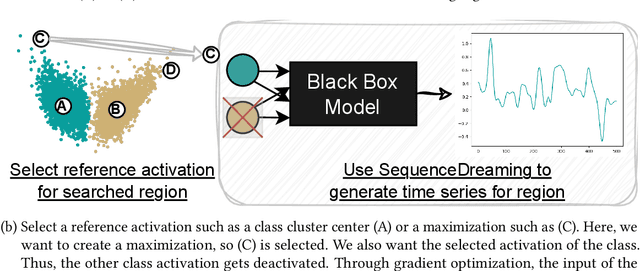

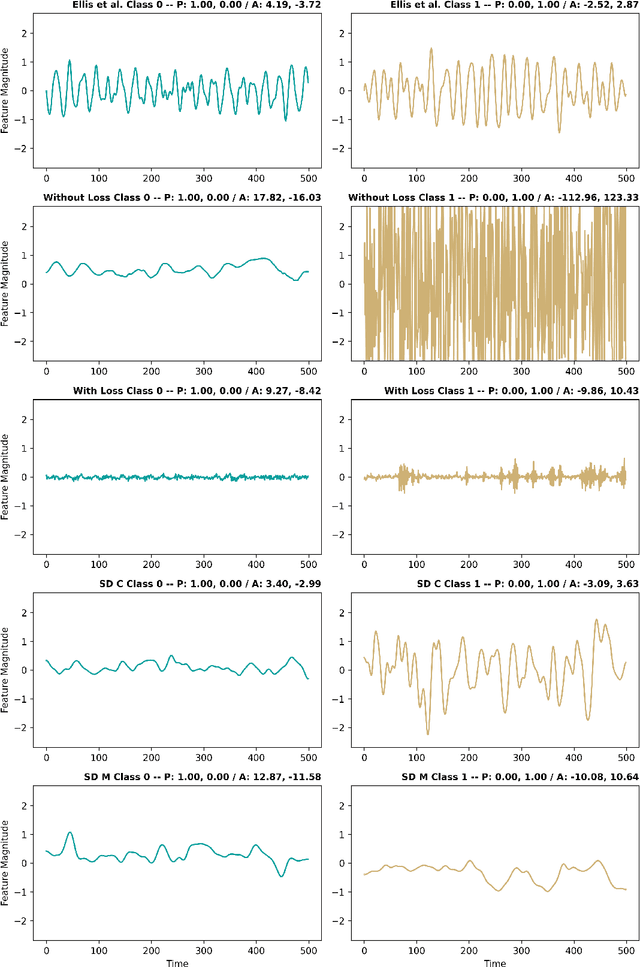
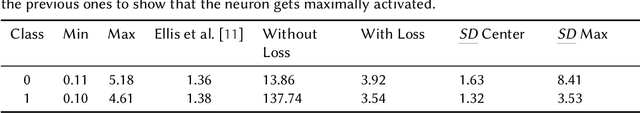
Understanding how models process and interpret time series data remains a significant challenge in deep learning to enable applicability in safety-critical areas such as healthcare. In this paper, we introduce Sequence Dreaming, a technique that adapts Activation Maximization to analyze sequential information, aiming to enhance the interpretability of neural networks operating on univariate time series. By leveraging this method, we visualize the temporal dynamics and patterns most influential in model decision-making processes. To counteract the generation of unrealistic or excessively noisy sequences, we enhance Sequence Dreaming with a range of regularization techniques, including exponential smoothing. This approach ensures the production of sequences that more accurately reflect the critical features identified by the neural network. Our approach is tested on a time series classification dataset encompassing applications in predictive maintenance. The results show that our proposed Sequence Dreaming approach demonstrates targeted activation maximization for different use cases so that either centered class or border activation maximization can be generated. The results underscore the versatility of Sequence Dreaming in uncovering salient temporal features learned by neural networks, thereby advancing model transparency and trustworthiness in decision-critical domains.
Cutting Through the Clutter: The Potential of LLMs for Efficient Filtration in Systematic Literature Reviews
Jul 15, 2024



In academic research, systematic literature reviews are foundational and highly relevant, yet tedious to create due to the high volume of publications and labor-intensive processes involved. Systematic selection of relevant papers through conventional means like keyword-based filtering techniques can sometimes be inadequate, plagued by semantic ambiguities and inconsistent terminology, which can lead to sub-optimal outcomes. To mitigate the required extensive manual filtering, we explore and evaluate the potential of using Large Language Models (LLMs) to enhance the efficiency, speed, and precision of literature review filtering, reducing the amount of manual screening required. By using models as classification agents acting on a structured database only, we prevent common problems inherent in LLMs, such as hallucinations. We evaluate the real-world performance of such a setup during the construction of a recent literature survey paper with initially more than 8.3k potentially relevant articles under consideration and compare this with human performance on the same dataset. Our findings indicate that employing advanced LLMs like GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Flash, or Llama3 with simple prompting can significantly reduce the time required for literature filtering - from usually weeks of manual research to only a few minutes. Simultaneously, we crucially show that false negatives can indeed be controlled through a consensus scheme, achieving recalls >98.8% at or even beyond the typical human error threshold, thereby also providing for more accurate and relevant articles selected. Our research not only demonstrates a substantial improvement in the methodology of literature reviews but also sets the stage for further integration and extensive future applications of responsible AI in academic research practices.