 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-Based Random Forest Visualization and Interpretation
Jul 30, 2025

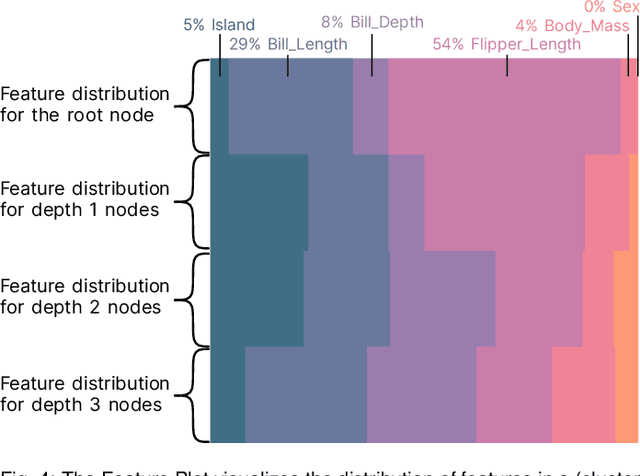

Random forests are a machine learning method used to automatically classify datasets and consist of a multitude of decision trees. While these random forests often have higher performance and generalize better than a single decision tree, they are also harder to interpret. This paper presents a visualization method and system to increase interpretability of random forests. We cluster similar trees which enables users to interpret how the model performs in general without needing to analyze each individual decision tree in detail, or interpret an oversimplified summary of the full forest. To meaningfully cluster the decision trees, we introduce a new distance metric that takes into account both the decision rules as well as the predictions of a pair of decision trees. We also propose two new visualization methods that visualize both clustered and individual decision trees: (1) The Feature Plot, which visualizes the topological position of features in the decision trees, and (2) the Rule Plot, which visualizes the decision rules of the decision trees. We demonstrate the efficacy of our approach through a case study on the "Glass" dataset, which is a relatively complex standard machine learning dataset, as well as a small user study.
A Multimedia Analytics Model for the Foundation Model Era
Apr 10, 2025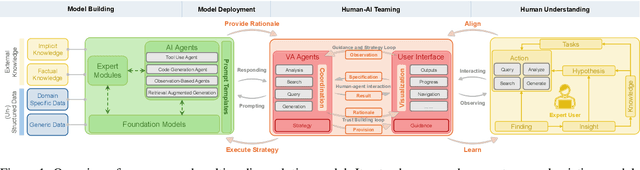
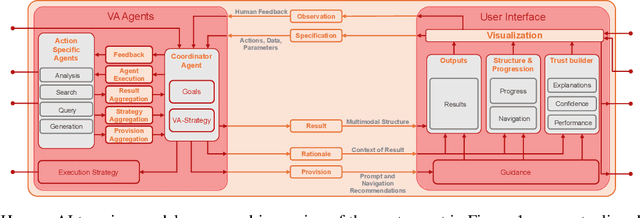
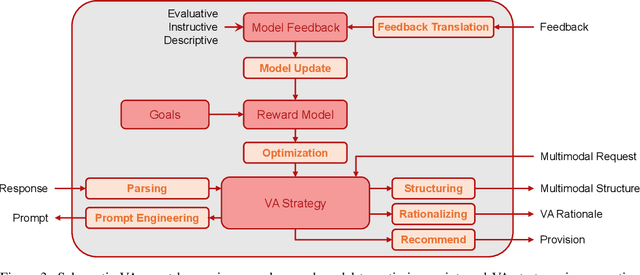
The rapid advances in Foundation Models and agentic Artificial Intelligence are transforming multimedia analytics by enabling richer, more sophisticated interactions between humans and analytical systems. Existing conceptual models for visual and multimedia analytics, however, do not adequately capture the complexity introduced by these powerful AI paradigms. To bridge this gap, we propose a comprehensive multimedia analytics model specifically designed for the foundation model era. Building upon established frameworks from visual analytics, multimedia analytics, knowledge generation, analytic task definition, mixed-initiative guidance, and human-in-the-loop reinforcement learning, our model emphasizes integrated human-AI teaming based on visual analytics agents from both technical and conceptual perspectives. Central to the model is a seamless, yet explicitly separable, interaction channel between expert users and semi-autonomous analytical processes, ensuring continuous alignment between user intent and AI behavior. The model addresses practical challenges in sensitive domains such as intelligence analysis, investigative journalism, and other fields handling complex, high-stakes data. We illustrate through detailed case studies how our model facilitates deeper understanding and targeted improvement of multimedia analytics solutions. By explicitly capturing how expert users can optimally interact with and guide AI-powered multimedia analytics systems, our conceptual framework sets a clear direction for system design, comparison, and future research.
When Dimensionality Reduction Meets Graph (Drawing) Theory: Introducing a Common Framework, Challenges and Opportunities
Dec 09, 2024



In the vast landscape of visualization research, Dimensionality Reduction (DR) and graph analysis are two popular subfields, often essential to most visual data analytics setups. DR aims to create representations to support neighborhood and similarity analysis on complex, large datasets. Graph analysis focuses on identifying the salient topological properties and key actors within networked data, with specialized research on investigating how such features could be presented to the user to ease the comprehension of the underlying structure. Although these two disciplines are typically regarded as disjoint subfields, we argue that both fields share strong similarities and synergies that can potentially benefit both. Therefore, this paper discusses and introduces a unifying framework to help bridge the gap between DR and graph (drawing) theory. Our goal is to use the strongly math-grounded graph theory to improve the overall process of creating DR visual representations. We propose how to break the DR process into well-defined stages, discussing how to match some of the DR state-of-the-art techniques to this framework and presenting ideas on how graph drawing, topology features, and some popular algorithms and strategies used in graph analysis can be employed to improve DR topology extraction, embedding generation, and result validation. We also discuss the challenges and identify opportunities for implementing and using our framework, opening directions for future visualization research.
Pfeed: Generating near real-time personalized feeds using precomputed embedding similarities
Mar 06, 2024



In personalized recommender systems, embeddings are often used to encode customer actions and items, and retrieval is then performed in the embedding space using approximate nearest neighbor search. However, this approach can lead to two challenges: 1) user embeddings can restrict the diversity of interests captured and 2) the need to keep them up-to-date requires an expensive, real-time infrastructure. In this paper, we propose a method that overcomes these challenges in a practical, industrial setting. The method dynamically updates customer profiles and composes a feed every two minutes, employing precomputed embeddings and their respective similarities. We tested and deployed this method to personalise promotional items at Bol, one of the largest e-commerce platforms of the Netherlands and Belgium. The method enhanced customer engagement and experience, leading to a significant 4.9% uplift in conversions.
Class-constrained t-SNE: Combining Data Features and Class Probabilities
Aug 26, 2023Data features and class probabilities are two main perspectives when, e.g., evaluating model results and identifying problematic items. Class probabilities represent the likelihood that each instance belongs to a particular class, which can be produced by probabilistic classifiers or even human labeling with uncertainty. Since both perspectives are multi-dimensional data, dimensionality reduction (DR) techniques are commonly used to extract informative characteristics from them. However, existing methods either focus solely on the data feature perspective or rely on class probability estimates to guide the DR process. In contrast to previous work where separate views are linked to conduct the analysis, we propose a novel approach, class-constrained t-SNE, that combines data features and class probabilities in the same DR result. Specifically, we combine them by balancing two corresponding components in a cost function to optimize the positions of data points and iconic representation of classes -- class landmarks. Furthermore, an interactive user-adjustable parameter balances these two components so that users can focus on the weighted perspectives of interest and also empowers a smooth visual transition between varying perspectives to preserve the mental map. We illustrate its application potential in model evaluation and visual-interactive labeling. A comparative analysis is performed to evaluate the DR results.