 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gaps: Measuring Visual Artifacts in Dimensionality Reduction
Nov 18, 2025Dimensionality Reduction (DR) techniques are commonly used for the visual exploration and analysis of high-dimensional data due to their ability to project datasets of high-dimensional points onto the 2D plane. However, projecting datasets in lower dimensions often entails some distortion, which is not necessarily easy to recognize but can lead users to misleading conclusions. Several Projection Quality Metrics (PQMs) have been developed as tools to quantify the goodness-of-fit of a DR projection; however, they mostly focus on measuring how well the projection captures the global or local structure of the data, without taking into account the visual distortion of the resulting plots, thus often ignoring the presence of outliers or artifacts that can mislead a visual analysis of the projection. In this work, we introduce the Warping Index (WI), a new metric for measuring the quality of DR projections onto the 2D plane, based on the assumption that the correct preservation of empty regions between points is of crucial importance towards a faithful visual representation of the data.
When Dimensionality Reduction Meets Graph (Drawing) Theory: Introducing a Common Framework, Challenges and Opportunities
Dec 09, 2024



In the vast landscape of visualization research, Dimensionality Reduction (DR) and graph analysis are two popular subfields, often essential to most visual data analytics setups. DR aims to create representations to support neighborhood and similarity analysis on complex, large datasets. Graph analysis focuses on identifying the salient topological properties and key actors within networked data, with specialized research on investigating how such features could be presented to the user to ease the comprehension of the underlying structure. Although these two disciplines are typically regarded as disjoint subfields, we argue that both fields share strong similarities and synergies that can potentially benefit both. Therefore, this paper discusses and introduces a unifying framework to help bridge the gap between DR and graph (drawing) theory. Our goal is to use the strongly math-grounded graph theory to improve the overall process of creating DR visual representations. We propose how to break the DR process into well-defined stages, discussing how to match some of the DR state-of-the-art techniques to this framework and presenting ideas on how graph drawing, topology features, and some popular algorithms and strategies used in graph analysis can be employed to improve DR topology extraction, embedding generation, and result validation. We also discuss the challenges and identify opportunities for implementing and using our framework, opening directions for future visualization research.
Knowledge-Decks: Automatically Generating Presentation Slide Decks of Visual Analytics Knowledge Discovery Applications
Dec 02, 2022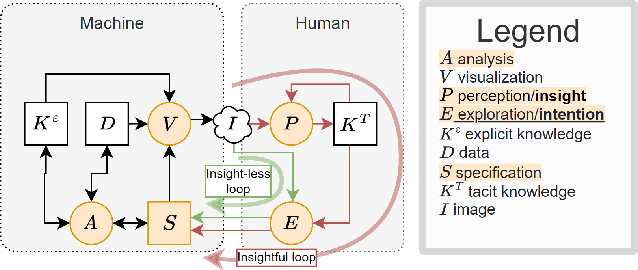
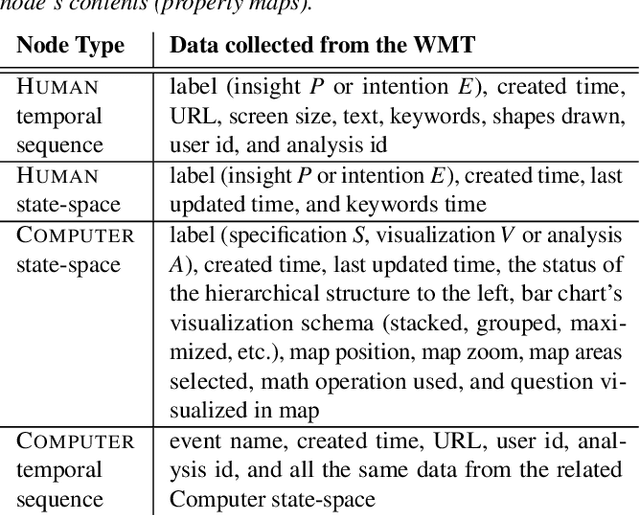
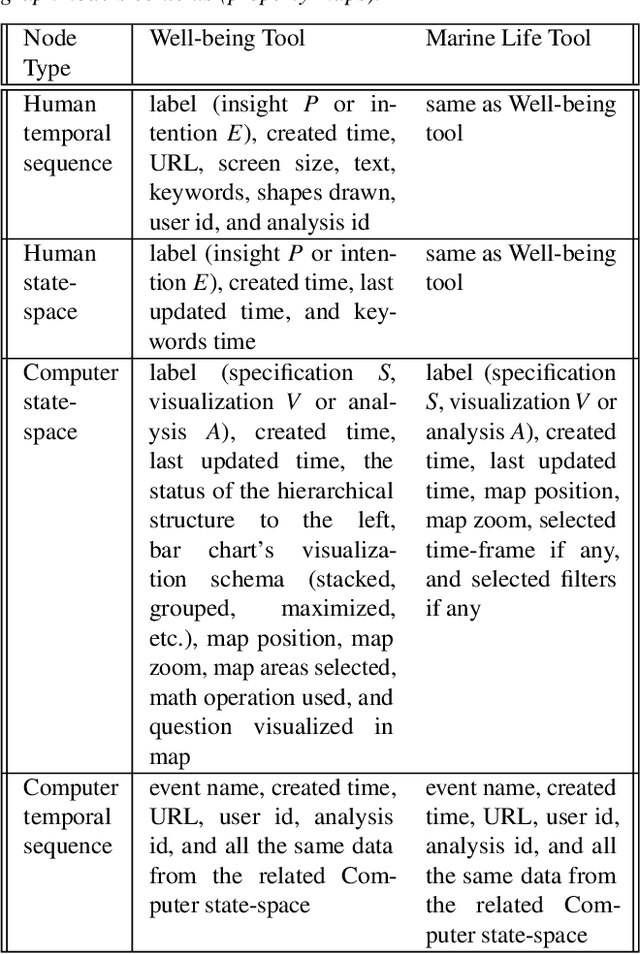
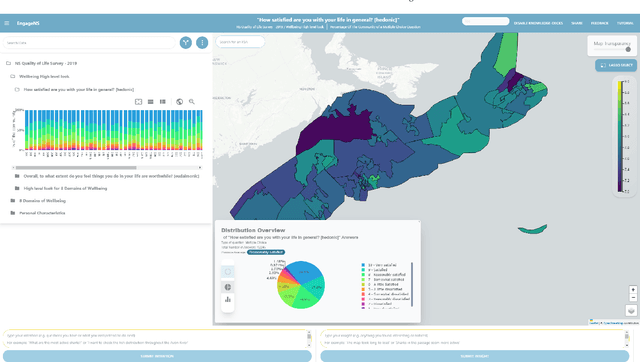
Visual Analytics (VA) tools provide ways for users to harness insights and knowledge from datasets. Recalling and retelling user experiences while utilizing VA tools has attracted significant interest. Nevertheless, each user sessions are unique. Even when different users have the same intention when using a VA tool, they may follow different paths and uncover different insights. Current methods of manually processing such data to recall and retell users' knowledge discovery paths may also be time-consuming, especially when there is the need to present users' findings to third parties. This paper presents a novel system that collects user intentions, behavior, and insights during knowledge discovery sessions, automatically structure the data, and extracts narrations of knowledge discovery as PowerPoint slide decks. The system is powered by a Knowledge Graph designed based on a formal and reproducible modeling process. To evaluate our system, we have attached it to two existing VA tools where users were asked to perform pre-defined tasks. Several slide decks and other analysis metrics were extracted from the generated Knowledge Graph. Experts scrutinized and confirmed the usefulness of our automated process for using the slide decks to disclose knowledge discovery paths to others and to verify whether the VA tools themselves were effective.
Active learning for medical code assignment
Apr 12, 2021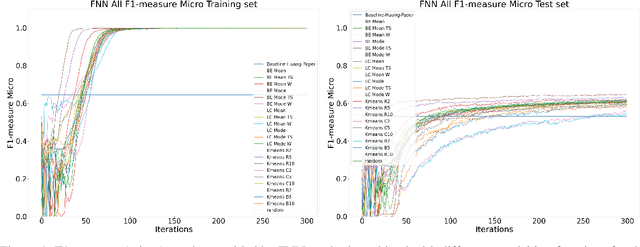
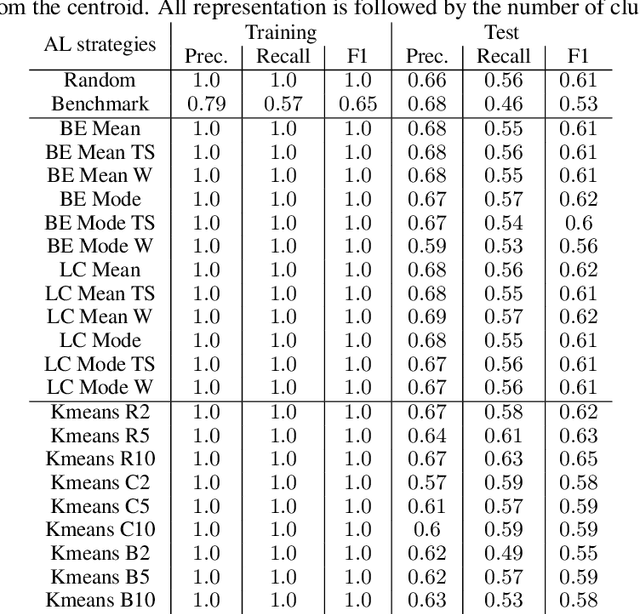
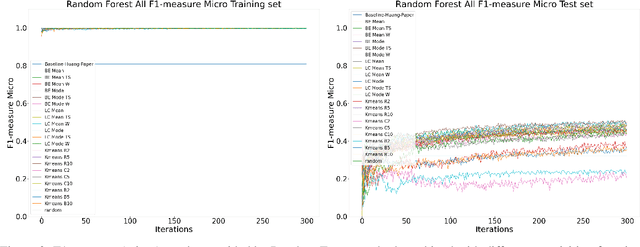
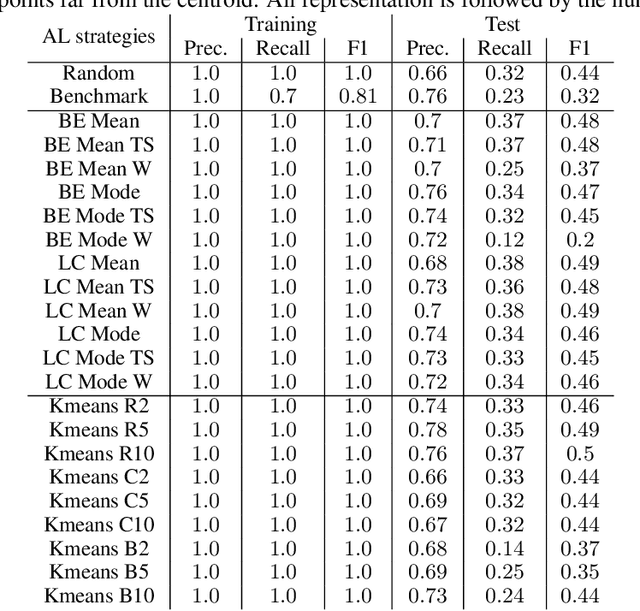
Machine Learning (ML) is widely used to automatically extract meaningful information from Electronic Health Records (EHR) to support operational, clinical, and financial decision-making. However, ML models require a large number of annotated examples to provide satisfactory results, which is not possible in most healthcare scenarios due to the high cost of clinician-labeled data. Active Learning (AL) is a process of selecting the most informative instances to be labeled by an expert to further train a supervised algorithm. We demonstrate the effectiveness of AL in multi-label text classification in the clinical domain. In this context, we apply a set of well-known AL methods to help automatically assign ICD-9 codes on the MIMIC-III dataset. Our results show that the selection of informative instances provides satisfactory classification with a significantly reduced training set (8.3\% of the total instances). We conclude that AL methods can significantly reduce the manual annotation cost while preserving model performance.
Multi-point dimensionality reduction to improve projection layout reliability
Jan 15, 2021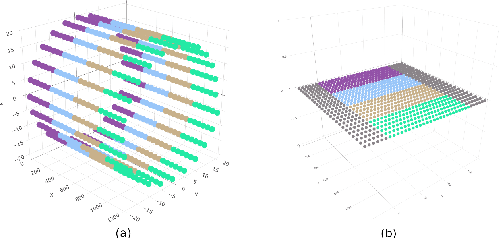
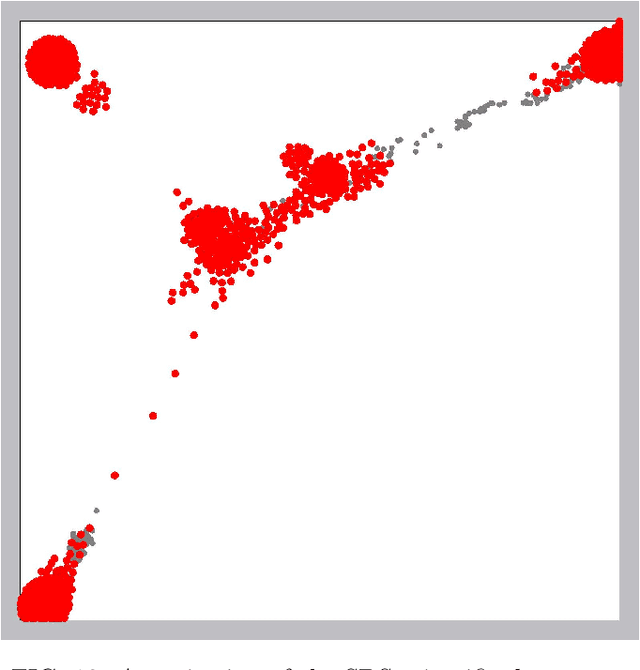

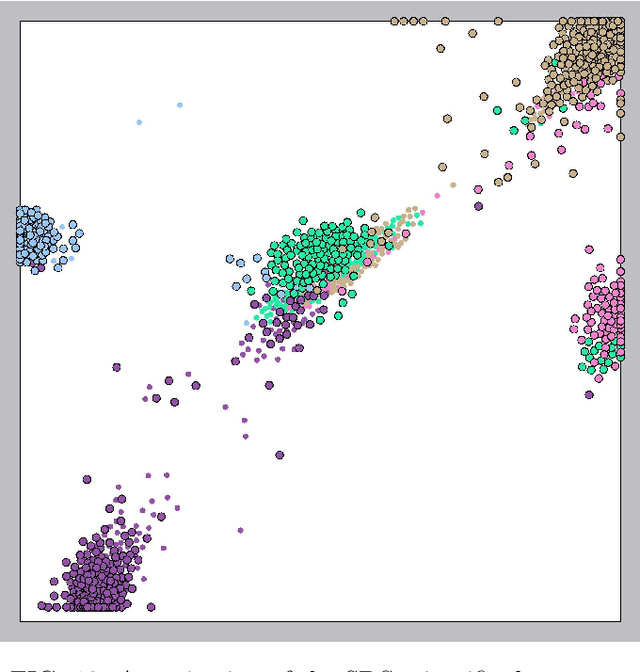
In ordinary Dimensionality Reduction (DR), each data instance in an m-dimensional space (original space) is mapped to one point in a d-dimensional space (visual space), preserving as much as possible distance and/or neighborhood relationships. Despite their popularity, even for simple datasets, the existing DR techniques unavoidably may produce misleading visual representations. The problem is not with the existing solutions but with problem formulation. For two dimensional visual space, if data instances are not co-planar or do not lie on a 2D manifold, there is no solution for the problem, and the possible approximations usually result in layouts with inaccuracies in the distance preservation and overlapped neighborhoods. In this paper, we elaborate on the concept of Multi-point Dimensionality Reduction where each data instance can be mapped to possibly more than one point in the visual space by providing the first general solution to it as a step toward mitigating this issue. By duplicating points, background information is added to the visual representation making local neighborhoods in the visual space more faithful to the original space. Our solution, named Red Gray Plus, is built upon and extends a combination of ordinary DR and graph drawing techniques. We show that not only Multi-point Dimensionality Reduction can be one of the potential directions to improve DR layouts' reliability but also that our initial solution to the problem outperforms popular ordinary DR methods quantitatively.
Visual Feature Fusion and its Application to Support Unsupervised Clustering Tasks
Jan 16, 2019


On visual analytics applications, the concept of putting the user on the loop refers to the ability to replace heuristics by user knowledge on machine learning and data mining tasks. On supervised tasks, the user engagement occurs via the manipulation of the training data. However, on unsupervised tasks, the user involvement is limited to changes in the algorithm parametrization or the input data representation, also known as features. Depending on the application domain, different types of features can be extracted from the raw data. Therefore, the result of unsupervised algorithms heavily depends on the type of employed feature. Since there is no perfect feature extractor, combining different features have been explored in a process called feature fusion. The feature fusion is straightforward when the machine learning or data mining task has a cost function. However, when such a function does not exist, user support for combination needs to be provided otherwise the process is impractical. In this paper, we present a novel feature fusion approach that uses small data samples to allows users not only to effortless control the combination of different feature sets but also to interpret the attained results. The effectiveness of our approach is confirmed by a comprehensive set of qualitative and quantitative tests, opening up different possibilities of user-guided analytical scenarios not covered yet. The ability of our approach to providing real-time feedback for the feature fusion is exploited on the context of unsupervised clustering techniques, where the composed groups reflect the semantics of the feature combination.