 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance Preserving Grid Layouts
Mar 08, 2019

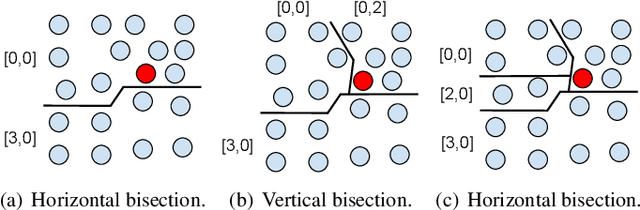
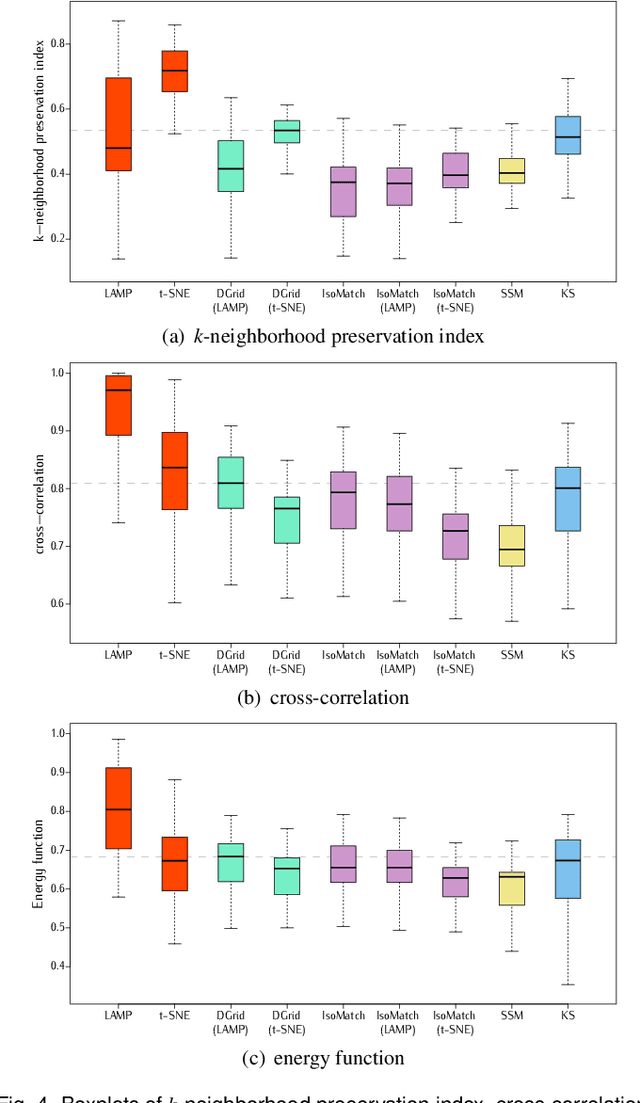
Distance preserving visualization techniques have emerged as one of the fundamental tools for data analysis. One example are the techniques that arrange data instances into two-dimensional grids so that the pairwise distances among the instances are preserved into the produced layouts. Currently, the state-of-the-art approaches produce such grids by solving assignment problems or using permutations to optimize cost functions. Although precise, such strategies are computationally expensive, limited to small datasets or being dependent on specialized hardware to speed up the process. In this paper, we present a new technique, called Distance-preserving Grid (DGrid), that employs a binary space partitioning process in combination with multidimensional projections to create orthogonal regular grid layouts. Our results show that DGrid is as precise as the existing state-of-the-art techniques whereas requiring only a fraction of the running time and computational resources.
Visual Feature Fusion and its Application to Support Unsupervised Clustering Tasks
Jan 16, 2019


On visual analytics applications, the concept of putting the user on the loop refers to the ability to replace heuristics by user knowledge on machine learning and data mining tasks. On supervised tasks, the user engagement occurs via the manipulation of the training data. However, on unsupervised tasks, the user involvement is limited to changes in the algorithm parametrization or the input data representation, also known as features. Depending on the application domain, different types of features can be extracted from the raw data. Therefore, the result of unsupervised algorithms heavily depends on the type of employed feature. Since there is no perfect feature extractor, combining different features have been explored in a process called feature fusion. The feature fusion is straightforward when the machine learning or data mining task has a cost function. However, when such a function does not exist, user support for combination needs to be provided otherwise the process is impractical. In this paper, we present a novel feature fusion approach that uses small data samples to allows users not only to effortless control the combination of different feature sets but also to interpret the attained results. The effectiveness of our approach is confirmed by a comprehensive set of qualitative and quantitative tests, opening up different possibilities of user-guided analytical scenarios not covered yet. The ability of our approach to providing real-time feedback for the feature fusion is exploited on the context of unsupervised clustering techniques, where the composed groups reflect the semantics of the feature combination.