 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimedia Analytics Model for the Foundation Model Era
Apr 10, 2025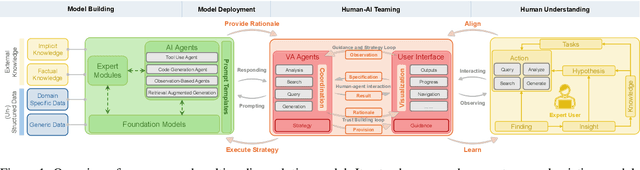
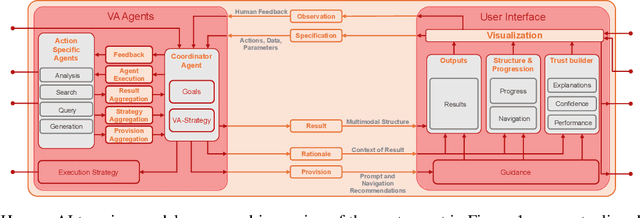
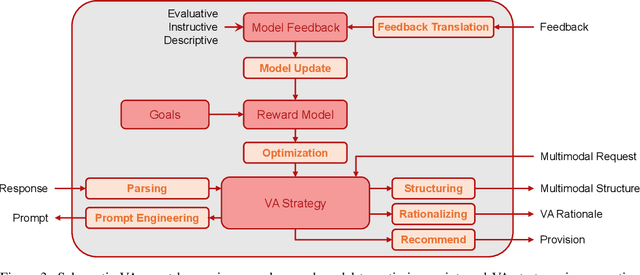
The rapid advances in Foundation Models and agentic Artificial Intelligence are transforming multimedia analytics by enabling richer, more sophisticated interactions between humans and analytical systems. Existing conceptual models for visual and multimedia analytics, however, do not adequately capture the complexity introduced by these powerful AI paradigms. To bridge this gap, we propose a comprehensive multimedia analytics model specifically designed for the foundation model era. Building upon established frameworks from visual analytics, multimedia analytics, knowledge generation, analytic task definition, mixed-initiative guidance, and human-in-the-loop reinforcement learning, our model emphasizes integrated human-AI teaming based on visual analytics agents from both technical and conceptual perspectives. Central to the model is a seamless, yet explicitly separable, interaction channel between expert users and semi-autonomous analytical processes, ensuring continuous alignment between user intent and AI behavior. The model addresses practical challenges in sensitive domains such as intelligence analysis, investigative journalism, and other fields handling complex, high-stakes data. We illustrate through detailed case studies how our model facilitates deeper understanding and targeted improvement of multimedia analytics solutions. By explicitly capturing how expert users can optimally interact with and guide AI-powered multimedia analytics systems, our conceptual framework sets a clear direction for system design, comparison, and future research.
Adversarial Attacks on Hyperbolic Networks
Dec 02, 2024



As hyperbolic deep learning grows in popularity, so does the need for adversarial robustness in the context of such a non-Euclidean geometry. To this end, this paper proposes hyperbolic alternatives to the commonly used FGM and PGD adversarial attacks. Through interpretable synthetic benchmarks and experiments on existing datasets, we show how the existing and newly proposed attacks differ. Moreover, we investigate the differences in adversarial robustness between Euclidean and fully hyperbolic networks. We find that these networks suffer from different types of vulnerabilities and that the newly proposed hyperbolic attacks cannot address these differences. Therefore, we conclude that the shifts in adversarial robustness are due to the models learning distinct patterns resulting from their different geometries.
Can ChatGPT Read Who You Are?
Dec 26, 2023
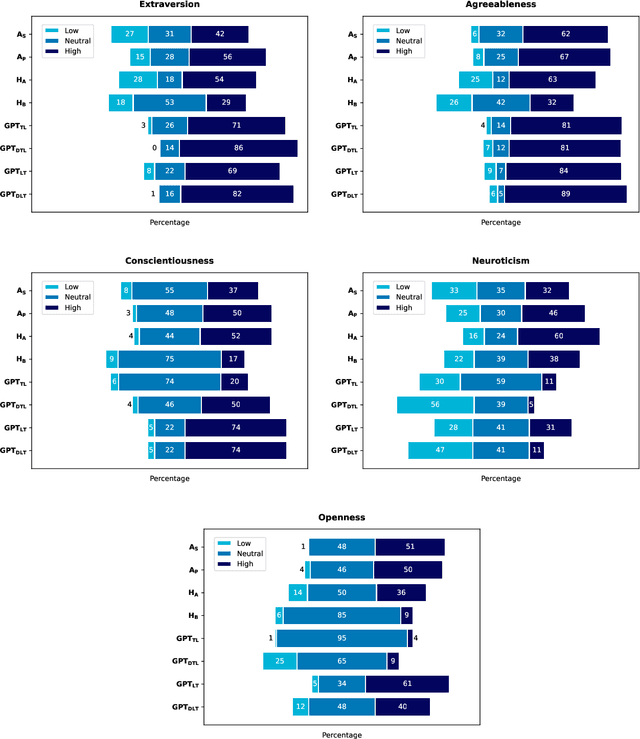
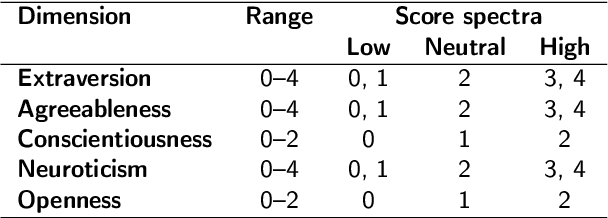
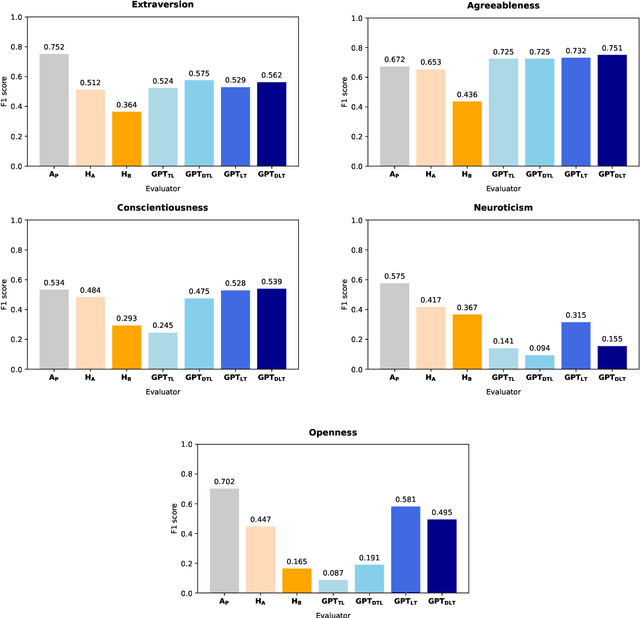
The interplay between artificial intelligence (AI) and psychology, particularly in personality assessment, represents an important emerging area of research. Accurate personality trait estimation is crucial not only for enhancing personalization in human-computer interaction but also for a wide variety of applications ranging from mental health to education. This paper analyzes the capability of a generic chatbot, ChatGPT, to effectively infer personality traits from short texts. We report the results of a comprehensive user study featuring texts written in Czech by a representative population sample of 155 participants. Their self-assessments based on the Big Five Inventory (BFI) questionnaire serve as the ground truth. We compare the personality trait estimations made by ChatGPT against those by human raters and report ChatGPT's competitive performance in inferring personality traits from text. We also uncover a 'positivity bias' in ChatGPT's assessments across all personality dimensions and explore the impact of prompt composition on accuracy. This work contributes to the understanding of AI capabilities in psychological assessment, highlighting both the potential and limitations of using large language models for personality inference. Our research underscores the importance of responsible AI development, considering ethical implications such as privacy, consent, autonomy, and bias in AI applications.
Trainwreck: A damaging adversarial attack on image classifiers
Nov 24, 2023



Adversarial attacks are an important security concern for computer vision (CV), as they enable malicious attackers to reliably manipulate CV models. Existing attacks aim to elicit an output desired by the attacker, but keep the model fully intact on clean data. With CV models becoming increasingly valuable assets in applied practice, a new attack vector is emerging: disrupting the models as a form of economic sabotage. This paper opens up the exploration of damaging adversarial attacks (DAAs) that seek to damage the target model and maximize the total cost incurred by the damage. As a pioneer DAA, this paper proposes Trainwreck, a train-time attack that poisons the training data of image classifiers to degrade their performance. Trainwreck conflates the data of similar classes using stealthy ($\epsilon \leq 8/255$) class-pair universal perturbations computed using a surrogate model. Trainwreck is a black-box, transferable attack: it requires no knowledge of the target model's architecture, and a single poisoned dataset degrades the performance of any model trained on it. The experimental evaluation on CIFAR-10 and CIFAR-100 demonstrates that Trainwreck is indeed an effective attack across various model architectures including EfficientNetV2, ResNeXt-101, and a finetuned ViT-L-16. The strength of the attack can be customized by the poison rate parameter. Finally, data redundancy with file hashing and/or pixel difference are identified as a reliable defense technique against Trainwreck or similar DAAs. The code is available at https://github.com/JanZahalka/trainwreck.
A Security Risk Taxonomy for Large Language Models
Nov 19, 2023



As large language models (LLMs) permeate more and more applications, an assessment of their associated security risks becomes increasingly necessary. The potential for exploitation by malicious actors, ranging from disinformation to data breaches and reputation damage, is substantial. This paper addresses a gap in current research by focusing on the security risks posed by LLMs, which extends beyond the widely covered ethical and societal implications. Our work proposes a taxonomy of security risks along the user-model communication pipeline, explicitly focusing on prompt-based attacks on LLMs. We categorize the attacks by target and attack type within a prompt-based interaction scheme. The taxonomy is reinforced with specific attack examples to showcase the real-world impact of these risks. Through this taxonomy, we aim to inform the development of robust and secure LLM applications, enhancing their safety and trustworthiness.