 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Adversarial Attacks and Training in Deep Hedging
Aug 20, 2025In this paper, we study the robustness of classical deep hedging strategies under distributional shifts by leveraging the concept of adversarial attacks. We first demonstrate that standard deep hedging models are highly vulnerable to small perturbations in the input distribution, resulting in significant performance degradation. Motivated by this, we propose an adversarial training framework tailored to increase the robustness of deep hedging strategies. Our approach extends pointwise adversarial attacks to the distributional setting and introduces a computationally tractable reformulation of the adversarial optimization problem over a Wasserstein ball. This enables the efficient training of hedging strategies that are resilient to distributional perturbations. Through extensive numerical experiments, we show that adversarially trained deep hedging strategies consistently outperform their classical counterparts in terms of out-of-sample performance and resilience to model misspecification. Our findings establish a practical and effective framework for robust deep hedging under realistic market uncertainties.
A Two-Timescale Primal-Dual Framework for Reinforcement Learning via Online Dual Variable Guidance
May 07, 2025We study reinforcement learning by combining recent advances in regularized linear programming formulations with the classical theory of stochastic approximation. Motivated by the challenge of designing algorithms that leverage off-policy data while maintaining on-policy exploration, we propose PGDA-RL, a novel primal-dual Projected Gradient Descent-Ascent algorithm for solving regularized Markov Decision Processes (MDPs). PGDA-RL integrates experience replay-based gradient estimation with a two-timescale decomposition of the underlying nested optimization problem. The algorithm operates asynchronously, interacts with the environment through a single trajectory of correlated data, and updates its policy online in response to the dual variable associated with the occupation measure of the underlying MDP. We prove that PGDA-RL converges almost surely to the optimal value function and policy of the regularized MDP. Our convergence analysis relies on tools from stochastic approximation theory and holds under weaker assumptions than those required by existing primal-dual RL approaches, notably removing the need for a simulator or a fixed behavioral policy.
Towards Optimal Offline Reinforcement Learning
Mar 15, 2025We study offline reinforcement learning problems with a long-run average reward objective. The state-action pairs generated by any fixed behavioral policy thus follow a Markov chain, and the {\em empirical} state-action-next-state distribution satisfies a large deviations principle. We use the rate function of this large deviations principle to construct an uncertainty set for the unknown {\em true} state-action-next-state distribution. We also construct a distribution shift transformation that maps any distribution in this uncertainty set to a state-action-next-state distribution of the Markov chain generated by a fixed evaluation policy, which may differ from the unknown behavioral policy. We prove that the worst-case average reward of the evaluation policy with respect to all distributions in the shifted uncertainty set provides, in a rigorous statistical sense, the least conservative estimator for the average reward under the unknown true distribution. This guarantee is available even if one has only access to one single trajectory of serially correlated state-action pairs. The emerging robust optimization problem can be viewed as a robust Markov decision process with a non-rectangular uncertainty set. We adapt an efficient policy gradient algorithm to solve this problem. Numerical experiments show that our methods compare favorably against state-of-the-art methods.
Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms
Oct 24, 2024
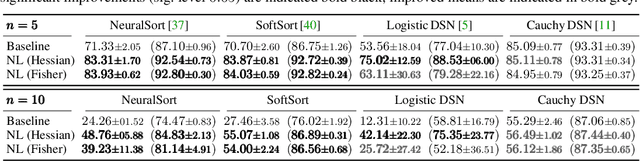


When training neural networks with custom objectives, such as ranking losses and shortest-path losses, a common problem is that they are, per se, non-differentiable. A popular approach is to continuously relax the objectives to provide gradients, enabling learning. However, such differentiable relaxations are often non-convex and can exhibit vanishing and exploding gradients, making them (already in isolation) hard to optimize. Here, the loss function poses the bottleneck when training a deep neural network. We present Newton Losses, a method for improving the performance of existing hard to optimize losses by exploiting their second-order information via their empirical Fisher and Hessian matrices. Instead of training the neural network with second-order techniques, we only utilize the loss function's second-order information to replace it by a Newton Loss, while training the network with gradient descent. This makes our method computationally efficient. We apply Newton Losses to eight differentiable algorithms for sorting and shortest-paths, achieving significant improvements for less-optimized differentiable algorithms, and consistent improvements, even for well-optimized differentiable algorithms.
Finding the DeepDream for Time Series: Activation Maximization for Univariate Time Series
Aug 20, 2024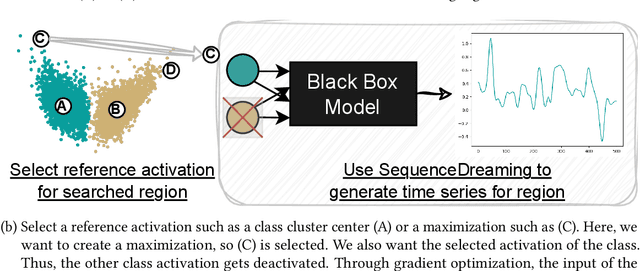

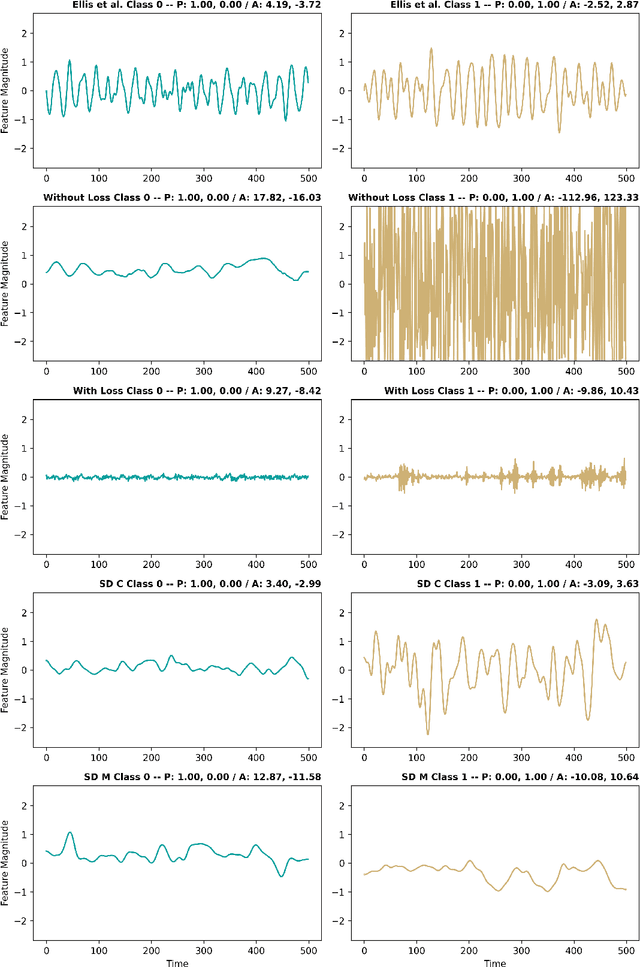
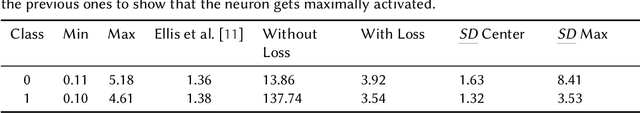
Understanding how models process and interpret time series data remains a significant challenge in deep learning to enable applicability in safety-critical areas such as healthcare. In this paper, we introduce Sequence Dreaming, a technique that adapts Activation Maximization to analyze sequential information, aiming to enhance the interpretability of neural networks operating on univariate time series. By leveraging this method, we visualize the temporal dynamics and patterns most influential in model decision-making processes. To counteract the generation of unrealistic or excessively noisy sequences, we enhance Sequence Dreaming with a range of regularization techniques, including exponential smoothing. This approach ensures the production of sequences that more accurately reflect the critical features identified by the neural network. Our approach is tested on a time series classification dataset encompassing applications in predictive maintenance. The results show that our proposed Sequence Dreaming approach demonstrates targeted activation maximization for different use cases so that either centered class or border activation maximization can be generated. The results underscore the versatility of Sequence Dreaming in uncovering salient temporal features learned by neural networks, thereby advancing model transparency and trustworthiness in decision-critical domains.
Randomized algorithms and PAC bounds for inverse reinforcement learning in continuous spaces
May 24, 2024This work studies discrete-time discounted Markov decision processes with continuous state and action spaces and addresses the inverse problem of inferring a cost function from observed optimal behavior. We first consider the case in which we have access to the entire expert policy and characterize the set of solutions to the inverse problem by using occupation measures, linear duality, and complementary slackness conditions. To avoid trivial solutions and ill-posedness, we introduce a natural linear normalization constraint. This results in an infinite-dimensional linear feasibility problem, prompting a thorough analysis of its properties. Next, we use linear function approximators and adopt a randomized approach, namely the scenario approach and related probabilistic feasibility guarantees, to derive epsilon-optimal solutions for the inverse problem. We further discuss the sample complexity for a desired approximation accuracy. Finally, we deal with the more realistic case where we only have access to a finite set of expert demonstrations and a generative model and provide bounds on the error made when working with samples.
Regularized Q-learning through Robust Averaging
May 03, 2024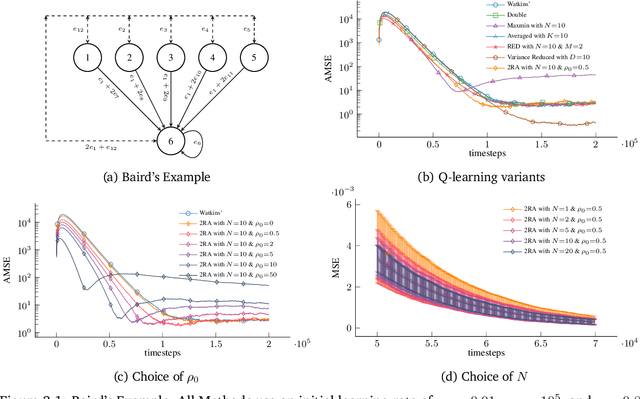
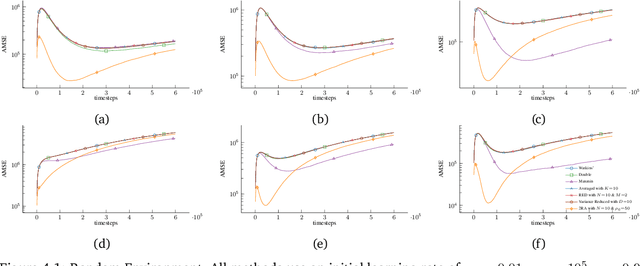
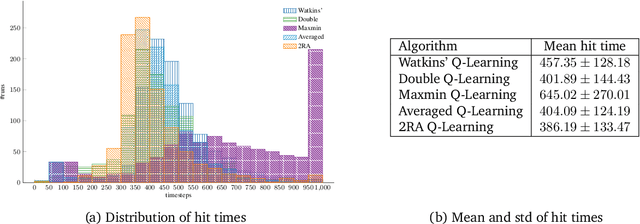
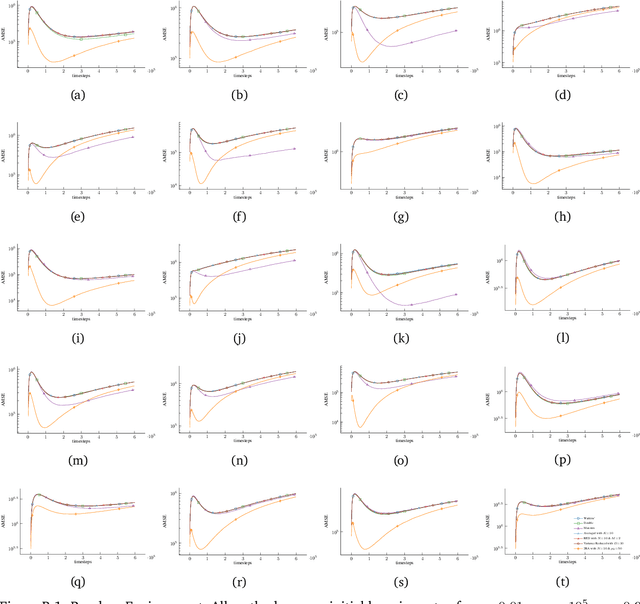
We propose a new Q-learning variant, called 2RA Q-learning, that addresses some weaknesses of existing Q-learning methods in a principled manner. One such weakness is an underlying estimation bias which cannot be controlled and often results in poor performance. We propose a distributionally robust estimator for the maximum expected value term, which allows us to precisely control the level of estimation bias introduced. The distributionally robust estimator admits a closed-form solution such that the proposed algorithm has a computational cost per iteration comparable to Watkins' Q-learning. For the tabular case, we show that 2RA Q-learning converges to the optimal policy and analyze its asymptotic mean-squared error. Lastly, we conduct numerical experiments for various settings, which corroborate our theoretical findings and indicate that 2RA Q-learning often performs better than existing methods.
End-to-End Learning for Stochastic Optimization: A Bayesian Perspective
Jun 11, 2023



We develop a principled approach to end-to-end learning in stochastic optimization. First, we show that the standard end-to-end learning algorithm admits a Bayesian interpretation and trains a posterior Bayes action map. Building on the insights of this analysis, we then propose new end-to-end learning algorithms for training decision maps that output solutions of empirical risk minimization and distributionally robust optimization problems, two dominant modeling paradigms in optimization under uncertainty. Numerical results for a synthetic newsvendor problem illustrate the key differences between alternative training schemes. We also investigate an economic dispatch problem based on real data to showcase the impact of the neural network architecture of the decision maps on their test performance.
Policy Gradient Algorithms for Robust MDPs with Non-Rectangular Uncertainty Sets
May 31, 2023

We propose a policy gradient algorithm for robust infinite-horizon Markov Decision Processes (MDPs) with non-rectangular uncertainty sets, thereby addressing an open challenge in the robust MDP literature. Indeed, uncertainty sets that display statistical optimality properties and make optimal use of limited data often fail to be rectangular. Unfortunately, the corresponding robust MDPs cannot be solved with dynamic programming techniques and are in fact provably intractable. This prompts us to develop a projected Langevin dynamics algorithm tailored to the robust policy evaluation problem, which offers global optimality guarantees. We also propose a deterministic policy gradient method that solves the robust policy evaluation problem approximately, and we prove that the approximation error scales with a new measure of non-rectangularity of the uncertainty set. Numerical experiments showcase that our projected Langevin dynamics algorithm can escape local optima, while algorithms tailored to rectangular uncertainty fail to do so.
Optimal Learning via Moderate Deviations Theory
May 23, 2023
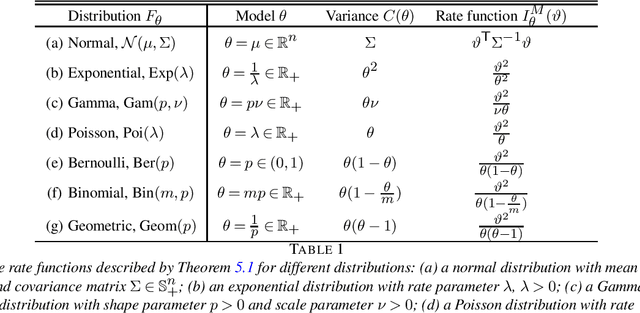


This paper proposes a statistically optimal approach for learning a function value using a confidence interval in a wide range of models, including general non-parametric estimation of an expected loss described as a stochastic programming problem or various SDE models. More precisely, we develop a systematic construction of highly accurate confidence intervals by using a moderate deviation principle-based approach. It is shown that the proposed confidence intervals are statistically optimal in the sense that they satisfy criteria regarding exponential accuracy, minimality, consistency, mischaracterization probability, and eventual uniformly most accurate (UMA) property. The confidence intervals suggested by this approach are expressed as solutions to robust optimization problems, where the uncertainty is expressed via the underlying moderate deviation rate function induced by the data-generating process. We demonstrate that for many models these optimization problems admit tractable reformulations as finite convex programs even when they are infinite-dimensional.