 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-guided Fusion of Multimodal Features for Change Detection from Optical-SAR Images
Apr 07, 2026Multimodal change detection (MMCD) identifies changed areas in multimodal remote sensing (RS) data, demonstrating significant application value in land use monitoring, disaster assessment, and urban sustainable development. However, literature MMCD approaches exhibit limitations in cross-modal interaction and exploiting modality-specific characteristics. This leads to insufficient modeling of fine-grained change information, thus hindering the precise detection of semantic changes in multimodal data. To address the above problems, we propose STSF-Net, a framework designed for MMCD between optical and SAR images. STSF-Net jointly models modality-specific and spatio-temporal common features to enhance change representations. Specifically, modality-specific features are exploited to capture genuine semantic change signals, while spatio-temporal common features are embedded to suppress pseudo-changes caused by differences in imaging mechanisms. Furthermore, we introduce an optical and SAR feature fusion strategy that adaptively adjusts feature importance based on semantic priors obtained from pre-trained foundational models, enabling semantic-guided adaptive fusion of multi-modal information. In addition, we introduce the Delta-SN6 dataset, the first openly-accessible multiclass MMCD benchmark consisting of very-high-resolution (VHR) fully polarimetric SAR and optical images. Experimental results on Delta-SN6, BRIGHT, and Wuhan-Het datasets demonstrate that our method outperforms the state-of-the-art (SOTA) by 3.21%, 1.08%, and 1.32% in mIoU, respectively. The associated code and Delta-SN6 dataset will be released at: https://github.com/liuxuanguang/STSF-Net.
Efficient Best-of-Both-Worlds Algorithms for Contextual Combinatorial Semi-Bandits
Aug 26, 2025
We introduce the first best-of-both-worlds algorithm for contextual combinatorial semi-bandits that simultaneously guarantees $\widetilde{\mathcal{O}}(\sqrt{T})$ regret in the adversarial regime and $\widetilde{\mathcal{O}}(\ln T)$ regret in the corrupted stochastic regime. Our approach builds on the Follow-the-Regularized-Leader (FTRL) framework equipped with a Shannon entropy regularizer, yielding a flexible method that admits efficient implementations. Beyond regret bounds, we tackle the practical bottleneck in FTRL (or, equivalently, Online Stochastic Mirror Descent) arising from the high-dimensional projection step encountered in each round of interaction. By leveraging the Karush-Kuhn-Tucker conditions, we transform the $K$-dimensional convex projection problem into a single-variable root-finding problem, dramatically accelerating each round. Empirical evaluations demonstrate that this combined strategy not only attains the attractive regret bounds of best-of-both-worlds algorithms but also delivers substantial per-round speed-ups, making it well-suited for large-scale, real-time applications.
Towards Optimal Offline Reinforcement Learning
Mar 15, 2025We study offline reinforcement learning problems with a long-run average reward objective. The state-action pairs generated by any fixed behavioral policy thus follow a Markov chain, and the {\em empirical} state-action-next-state distribution satisfies a large deviations principle. We use the rate function of this large deviations principle to construct an uncertainty set for the unknown {\em true} state-action-next-state distribution. We also construct a distribution shift transformation that maps any distribution in this uncertainty set to a state-action-next-state distribution of the Markov chain generated by a fixed evaluation policy, which may differ from the unknown behavioral policy. We prove that the worst-case average reward of the evaluation policy with respect to all distributions in the shifted uncertainty set provides, in a rigorous statistical sense, the least conservative estimator for the average reward under the unknown true distribution. This guarantee is available even if one has only access to one single trajectory of serially correlated state-action pairs. The emerging robust optimization problem can be viewed as a robust Markov decision process with a non-rectangular uncertainty set. We adapt an efficient policy gradient algorithm to solve this problem. Numerical experiments show that our methods compare favorably against state-of-the-art methods.
Optimism in the Face of Ambiguity Principle for Multi-Armed Bandits
Sep 30, 2024
Follow-The-Regularized-Leader (FTRL) algorithms often enjoy optimal regret for adversarial as well as stochastic bandit problems and allow for a streamlined analysis. Nonetheless, FTRL algorithms require the solution of an optimization problem in every iteration and are thus computationally challenging. In contrast, Follow-The-Perturbed-Leader (FTPL) algorithms achieve computational efficiency by perturbing the estimates of the rewards of the arms, but their regret analysis is cumbersome. We propose a new FTPL algorithm that generates optimal policies for both adversarial and stochastic multi-armed bandits. Like FTRL, our algorithm admits a unified regret analysis, and similar to FTPL, it offers low computational costs. Unlike existing FTPL algorithms that rely on independent additive disturbances governed by a \textit{known} distribution, we allow for disturbances governed by an \textit{ambiguous} distribution that is only known to belong to a given set and propose a principle of optimism in the face of ambiguity. Consequently, our framework generalizes existing FTPL algorithms. It also encapsulates a broad range of FTRL methods as special cases, including several optimal ones, which appears to be impossible with current FTPL methods. Finally, we use techniques from discrete choice theory to devise an efficient bisection algorithm for computing the optimistic arm sampling probabilities. This algorithm is up to $10^4$ times faster than standard FTRL algorithms that solve an optimization problem in every iteration. Our results not only settle existing conjectures but also provide new insights into the impact of perturbations by mapping FTRL to FTPL.
Deep Learning Meets OBIA: Tasks, Challenges, Strategies, and Perspectives
Aug 02, 2024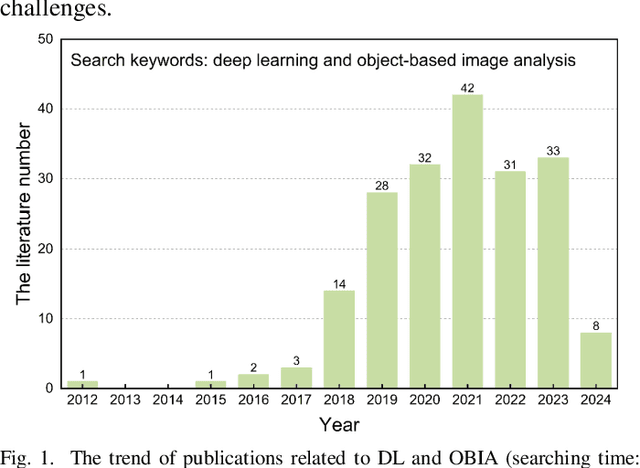
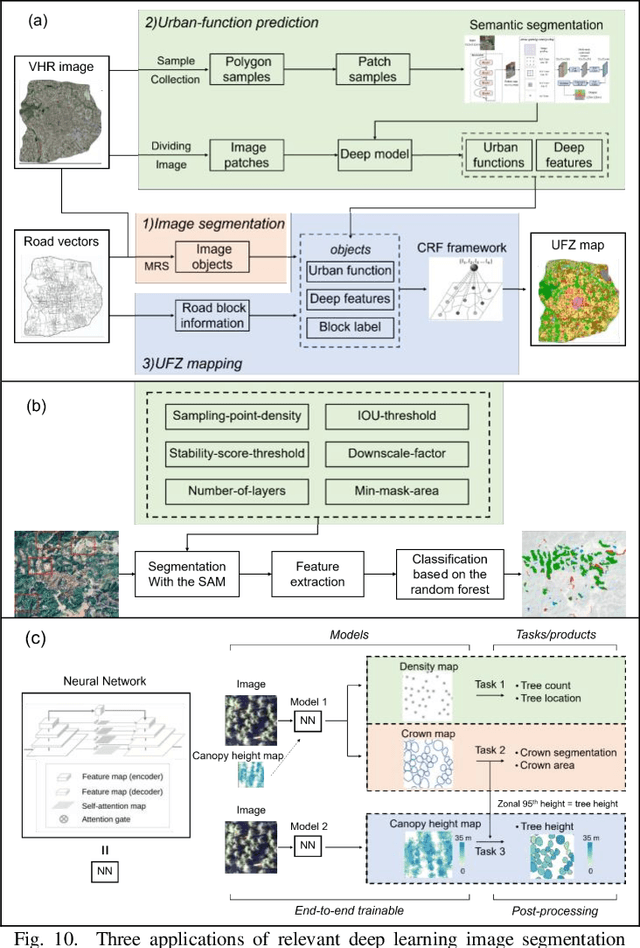
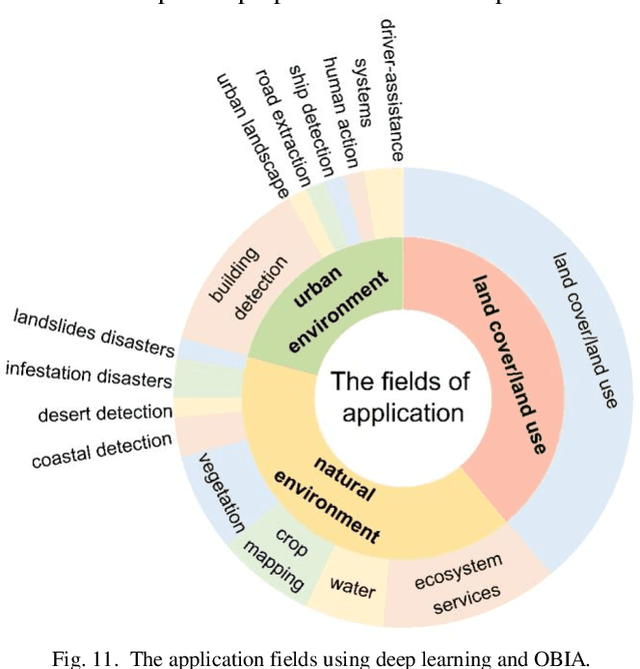

Deep learning has gained significant attention in remote sensing, especially in pixel- or patch-level applications. Despite initial attempts to integrate deep learning into object-based image analysis (OBIA), its full potential remains largely unexplored. In this article, as OBIA usage becomes more widespread, we conducted a comprehensive review and expansion of its task subdomains, with or without the integration of deep learning. Furthermore, we have identified and summarized five prevailing strategies to address the challenge of deep learning's limitations in directly processing unstructured object data within OBIA, and this review also recommends some important future research directions. Our goal with these endeavors is to inspire more exploration in this fascinating yet overlooked area and facilitate the integration of deep learning into OBIA processing workflows.
TSOM: Small Object Motion Detection Neural Network Inspired by Avian Visual Circuit
Apr 01, 2024



Detecting small moving objects in complex backgrounds from an overhead perspective is a highly challenging task for machine vision systems. As an inspiration from nature, the avian visual system is capable of processing motion information in various complex aerial scenes, and its Retina-OT-Rt visual circuit is highly sensitive to capturing the motion information of small objects from high altitudes. However, more needs to be done on small object motion detection algorithms based on the avian visual system. In this paper, we conducted mathematical modeling based on extensive studies of the biological mechanisms of the Retina-OT-Rt visual circuit. Based on this, we proposed a novel tectum small object motion detection neural network (TSOM). The neural network includes the retina, SGC dendritic, SGC Soma, and Rt layers, each layer corresponding to neurons in the visual pathway. The Retina layer is responsible for accurately projecting input content, the SGC dendritic layer perceives and encodes spatial-temporal information, the SGC Soma layer computes complex motion information and extracts small objects, and the Rt layer integrates and decodes motion information from multiple directions to determine the position of small objects. Extensive experiments on pigeon neurophysiological experiments and image sequence data showed that the TSOM is biologically interpretable and effective in extracting reliable small object motion features from complex high-altitude backgrounds.
A Large Deviations Perspective on Policy Gradient Algorithms
Nov 13, 2023We derive the first large deviation rate function for the stochastic iterates generated by policy gradient methods with a softmax parametrization and an entropy regularized objective. Leveraging the contraction principle from large deviations theory, we also develop a general recipe for deriving exponential convergence rates for a wide spectrum of other policy parametrizations. This approach unifies several results from the literature and simplifies existing proof techniques.
Policy Gradient Algorithms for Robust MDPs with Non-Rectangular Uncertainty Sets
May 31, 2023

We propose a policy gradient algorithm for robust infinite-horizon Markov Decision Processes (MDPs) with non-rectangular uncertainty sets, thereby addressing an open challenge in the robust MDP literature. Indeed, uncertainty sets that display statistical optimality properties and make optimal use of limited data often fail to be rectangular. Unfortunately, the corresponding robust MDPs cannot be solved with dynamic programming techniques and are in fact provably intractable. This prompts us to develop a projected Langevin dynamics algorithm tailored to the robust policy evaluation problem, which offers global optimality guarantees. We also propose a deterministic policy gradient method that solves the robust policy evaluation problem approximately, and we prove that the approximation error scales with a new measure of non-rectangularity of the uncertainty set. Numerical experiments showcase that our projected Langevin dynamics algorithm can escape local optima, while algorithms tailored to rectangular uncertainty fail to do so.
Distributionally Robust Optimization with Markovian Data
Jun 12, 2021
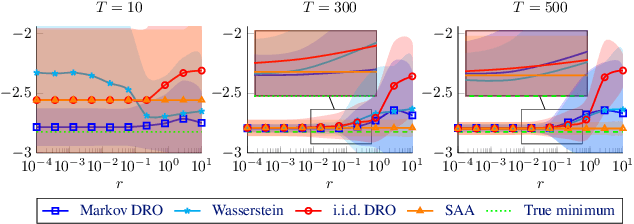
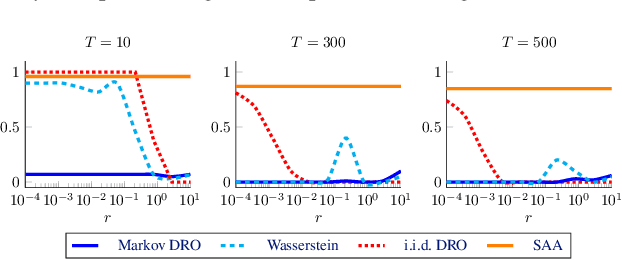
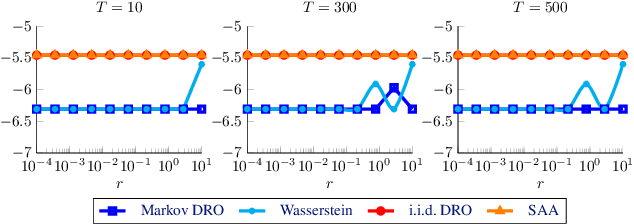
We study a stochastic program where the probability distribution of the uncertain problem parameters is unknown and only indirectly observed via finitely many correlated samples generated by an unknown Markov chain with $d$ states. We propose a data-driven distributionally robust optimization model to estimate the problem's objective function and optimal solution. By leveraging results from large deviations theory, we derive statistical guarantees on the quality of these estimators. The underlying worst-case expectation problem is nonconvex and involves $\mathcal O(d^2)$ decision variables. Thus, it cannot be solved efficiently for large $d$. By exploiting the structure of this problem, we devise a customized Frank-Wolfe algorithm with convex direction-finding subproblems of size $\mathcal O(d)$. We prove that this algorithm finds a stationary point efficiently under mild conditions. The efficiency of the method is predicated on a dimensionality reduction enabled by a dual reformulation. Numerical experiments indicate that our approach has better computational and statistical properties than the state-of-the-art methods.