 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBand Prompting Aided SAR and Multi-Spectral Data Fusion Framework for Local Climate Zone Classification
Dec 24, 2024



Local climate zone (LCZ) classification is of great value for understanding the complex interactions between urban development and local climate. Recent studies have increasingly focused on the fusion of synthetic aperture radar (SAR) and multi-spectral data to improve LCZ classification performance. However, it remains challenging due to the distinct physical properties of these two types of data and the absence of effective fusion guidance. In this paper, a novel band prompting aided data fusion framework is proposed for LCZ classification, namely BP-LCZ, which utilizes textual prompts associated with band groups to guide the model in learning the physical attributes of different bands and semantics of various categories inherent in SAR and multi-spectral data to augment the fused feature, thus enhancing LCZ classification performance. Specifically, a band group prompting (BGP) strategy is introduced to align the visual representation effectively at the level of band groups, which also facilitates a more adequate extraction of semantic information of different bands with textual information. In addition, a multivariate supervised matrix (MSM) based training strategy is proposed to alleviate the problem of positive and negative sample confusion by completing the supervised information. The experimental results demonstrate the effectiveness and superiority of the proposed data fusion framework.
LHRS-Bot-Nova: Improved Multimodal Large Language Model for Remote Sensing Vision-Language Interpretation
Nov 14, 2024

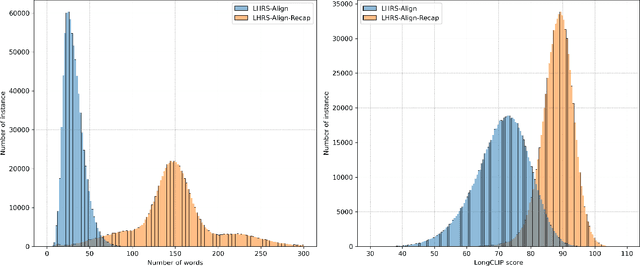

Automatically and rapidly understanding Earth's surface is fundamental to our grasp of the living environment and informed decision-making. This underscores the need for a unified system with comprehensive capabilities in analyzing Earth's surface to address a wide range of human needs. The emergence of multimodal large language models (MLLMs) has great potential in boosting the efficiency and convenience of intelligent Earth observation. These models can engage in human-like conversations, serve as unified platforms for understanding images, follow diverse instructions, and provide insightful feedbacks. In this study, we introduce LHRS-Bot-Nova, an MLLM specialized in understanding remote sensing (RS) images, designed to expertly perform a wide range of RS understanding tasks aligned with human instructions. LHRS-Bot-Nova features an enhanced vision encoder and a novel bridge layer, enabling efficient visual compression and better language-vision alignment. To further enhance RS-oriented vision-language alignment, we propose a large-scale RS image-caption dataset, generated through feature-guided image recaptioning. Additionally, we introduce an instruction dataset specifically designed to improve spatial recognition abilities. Extensive experiments demonstrate superior performance of LHRS-Bot-Nova across various RS image understanding tasks. We also evaluate different MLLM performances in complex RS perception and instruction following using a complicated multi-choice question evaluation benchmark, providing a reliable guide for future model selection and improvement. Data, code, and models will be available at https://github.com/NJU-LHRS/LHRS-Bot.
Deep Learning Meets OBIA: Tasks, Challenges, Strategies, and Perspectives
Aug 02, 2024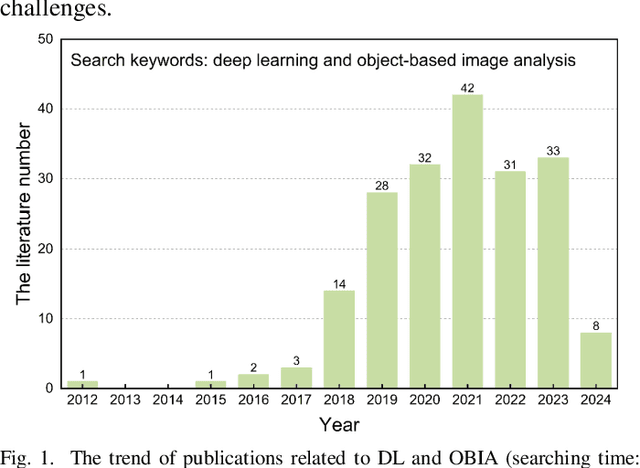
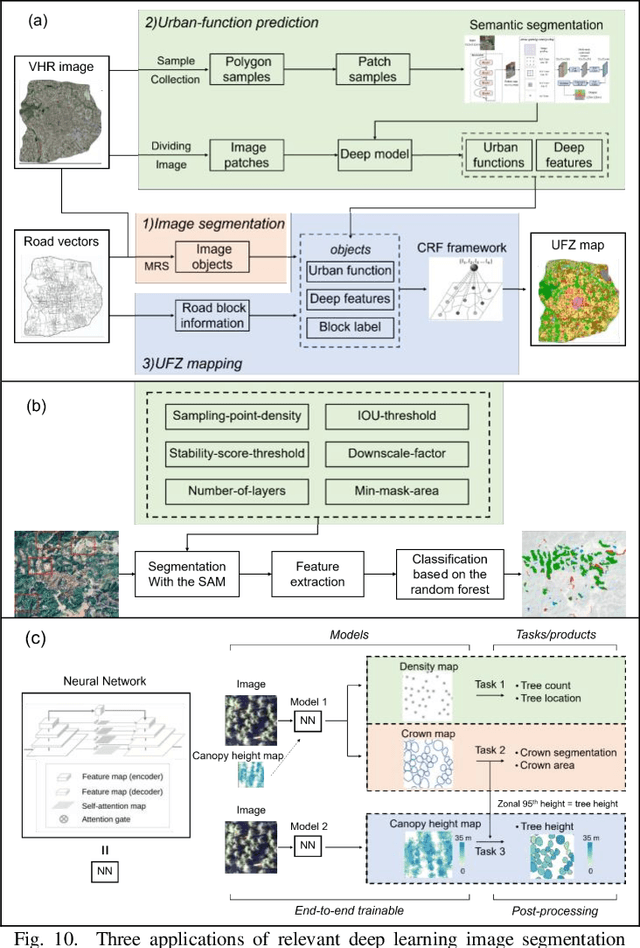
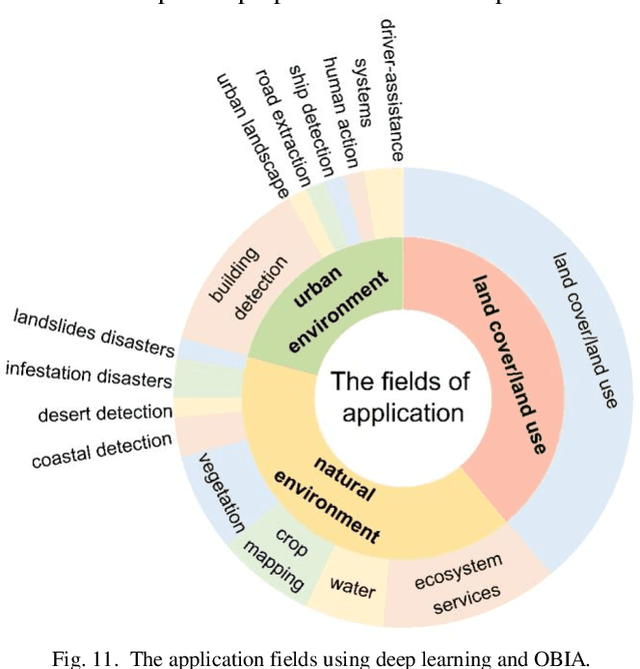

Deep learning has gained significant attention in remote sensing, especially in pixel- or patch-level applications. Despite initial attempts to integrate deep learning into object-based image analysis (OBIA), its full potential remains largely unexplored. In this article, as OBIA usage becomes more widespread, we conducted a comprehensive review and expansion of its task subdomains, with or without the integration of deep learning. Furthermore, we have identified and summarized five prevailing strategies to address the challenge of deep learning's limitations in directly processing unstructured object data within OBIA, and this review also recommends some important future research directions. Our goal with these endeavors is to inspire more exploration in this fascinating yet overlooked area and facilitate the integration of deep learning into OBIA processing workflows.
SISP: A Benchmark Dataset for Fine-grained Ship Instance Segmentation in Panchromatic Satellite Images
Feb 06, 2024Fine-grained ship instance segmentation in satellite images holds considerable significance for monitoring maritime activities at sea. However, existing datasets often suffer from the scarcity of fine-grained information or pixel-wise localization annotations, as well as the insufficient image diversity and variations, thus limiting the research of this task. To this end, we propose a benchmark dataset for fine-grained Ship Instance Segmentation in Panchromatic satellite images, namely SISP, which contains 56,693 well-annotated ship instances with four fine-grained categories across 10,000 sliced images, and all the images are collected from SuperView-1 satellite with the resolution of 0.5m. Targets in the proposed SISP dataset have characteristics that are consistent with real satellite scenes, such as high class imbalance, various scenes, large variations in target densities and scales, and high inter-class similarity and intra-class diversity, all of which make the SISP dataset more suitable for real-world applications. In addition, we introduce a Dynamic Feature Refinement-assist Instance segmentation network, namely DFRInst, as the benchmark method for ship instance segmentation in satellite images, which can fortify the explicit representation of crucial features, thus improving the performance of ship instance segmentation. Experiments and analysis are performed on the proposed SISP dataset to evaluate the benchmark method and several state-of-the-art methods to establish baselines for facilitating future research. The proposed dataset and source codes will be available at: https://github.com/Justlovesmile/SISP.
Exchanging Dual Encoder-Decoder: A New Strategy for Change Detection with Semantic Guidance and Spatial Localization
Nov 19, 2023



Change detection is a critical task in earth observation applications. Recently, deep learning-based methods have shown promising performance and are quickly adopted in change detection. However, the widely used multiple encoder and single decoder (MESD) as well as dual encoder-decoder (DED) architectures still struggle to effectively handle change detection well. The former has problems of bitemporal feature interference in the feature-level fusion, while the latter is inapplicable to intraclass change detection and multiview building change detection. To solve these problems, we propose a new strategy with an exchanging dual encoder-decoder structure for binary change detection with semantic guidance and spatial localization. The proposed strategy solves the problems of bitemporal feature inference in MESD by fusing bitemporal features in the decision level and the inapplicability in DED by determining changed areas using bitemporal semantic features. We build a binary change detection model based on this strategy, and then validate and compare it with 18 state-of-the-art change detection methods on six datasets in three scenarios, including intraclass change detection datasets (CDD, SYSU), single-view building change detection datasets (WHU, LEVIR-CD, LEVIR-CD+) and a multiview building change detection dataset (NJDS). The experimental results demonstrate that our model achieves superior performance with high efficiency and outperforms all benchmark methods with F1-scores of 97.77%, 83.07%, 94.86%, 92.33%, 91.39%, 74.35% on CDD, SYSU, WHU, LEVIR-CD, LEVIR- CD+, and NJDS datasets, respectively. The code of this work will be available at https://github.com/NJU-LHRS/official-SGSLN.
Rethinking Scale Imbalance in Semi-supervised Object Detection for Aerial Images
Oct 23, 2023



This paper focuses on the scale imbalance problem of semi-supervised object detection(SSOD) in aerial images. Compared to natural images, objects in aerial images show smaller sizes and larger quantities per image, increasing the difficulty of manual annotation. Meanwhile, the advanced SSOD technique can train superior detectors by leveraging limited labeled data and massive unlabeled data, saving annotation costs. However, as an understudied task in aerial images, SSOD suffers from a drastic performance drop when facing a large proportion of small objects. By analyzing the predictions between small and large objects, we identify three imbalance issues caused by the scale bias, i.e., pseudo-label imbalance, label assignment imbalance, and negative learning imbalance. To tackle these issues, we propose a novel Scale-discriminative Semi-Supervised Object Detection (S^3OD) learning pipeline for aerial images. In our S^3OD, three key components, Size-aware Adaptive Thresholding (SAT), Size-rebalanced Label Assignment (SLA), and Teacher-guided Negative Learning (TNL), are proposed to warrant scale unbiased learning. Specifically, SAT adaptively selects appropriate thresholds to filter pseudo-labels for objects at different scales. SLA balances positive samples of objects at different scales through resampling and reweighting. TNL alleviates the imbalance in negative samples by leveraging information generated by a teacher model. Extensive experiments conducted on the DOTA-v1.5 benchmark demonstrate the superiority of our proposed methods over state-of-the-art competitors. Codes will be released soon.
EARL: An Elliptical Distribution aided Adaptive Rotation Label Assignment for Oriented Object Detection in Remote Sensing Images
Jan 14, 2023



Label assignment is often employed in recent convolutional neural network (CNN) based detectors to determine positive or negative samples during training process. However, we note that current label assignment strategies barely consider the characteristics of targets in remote sensing images thoroughly, such as large variations in orientations, aspect ratios and scales, which lead to insufficient sampling. In this paper, an Elliptical Distribution aided Adaptive Rotation Label Assignment (EARL) is proposed to select positive samples with higher quality in orientation detectors, and yields better performance. Concretely, to avoid inadequate sampling of targets with extreme scales, an adaptive scale sampling (ADS) strategy is proposed to dynamically select samples on different feature levels according to the scales of targets. To enhance ADS, positive samples are selected following a dynamic elliptical distribution (DED), which can further exploit the orientation and shape properties of targets. Moreover, a spatial distance weighting (SDW) module is introduced to mitigate the influence from low-quality samples on detection performance. Extensive experiments on popular remote sensing datasets, such as DOTA and HRSC2016, demonstrate the effectiveness and the superiority of our proposed EARL, where without bells and whistles, it achieves 72.87 of mAP on DOTA dataset by being integrated with simple structure, which outperforms current state-of-the-art anchor-free detectors and provides comparable performance as anchor-based methods. The source code will be available at https://github.com/Justlovesmile/EARL