 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPIOT: Autonomous Vulnerability Management Across Bare-Metal Industrial OT Networks
May 04, 2026Bare-metal operational technology (OT) devices -- especially the microcontrollers running Modbus/TCP and CoAP at the base of industrial control systems -- have remained outside the reach of autonomous security attacks. Prior autonomous pentesting studies target Linux and web systems, whose shells and filesystems are familiar to LLM agents. Bare-metal OT has neither, so agents must reason directly over protocol fields and parser semantics. This requires new action-space designs and runtime controls, and opens new research questions about protocol-level exploit reasoning and its deployment envelope. We present APIOT (Autonomous Purple-teaming for Industrial OT), the first large language model (LLM) framework demonstrating an autonomous attack and remediation of bare-metal OT devices, achieving the full discovery -> exploitation -> patching -> verification cycle without step-by-step human intervention. We implemented and evaluated this framework on Zephyr RTOS firmware across heterogeneous industrial IoT (IIoT) topologies. Through 290 experiment runs spanning five frontier LLMs, three network topologies, two impairment levels, and guided versus unguided conditions, APIOT achieved a mission success rate of 90.0% on the full attack-remediation cycle. We found that the runtime governance layer (which we call an overseer) is a critical engineering variable: without it, agents exhibit systematic degenerate patterns, including repetition loops, missing crash verification, and reconnaissance deadlocks. Together, these findings carry two implications beyond our testbed. Attacker expertise is no longer the binding constraint on bare-metal OT exploitation, and defender threat models must now assume LLM-augmented adversaries capable of executing autonomous discovery-through-remediation cycles against industrial firmware.
LADFA: A Framework of Using Large Language Models and Retrieval-Augmented Generation for Personal Data Flow Analysis in Privacy Policies
Jan 15, 2026Privacy policies help inform people about organisations' personal data processing practices, covering different aspects such as data collection, data storage, and sharing of personal data with third parties. Privacy policies are often difficult for people to fully comprehend due to the lengthy and complex legal language used and inconsistent practices across different sectors and organisations. To help conduct automated and large-scale analyses of privacy policies, many researchers have studied applications of machine learning and natural language processing techniques, including large language models (LLMs). While a limited number of prior studies utilised LLMs for extracting personal data flows from privacy policies, our approach builds on this line of work by combining LLMs with retrieval-augmented generation (RAG) and a customised knowledge base derived from existing studies. This paper presents the development of LADFA, an end-to-end computational framework, which can process unstructured text in a given privacy policy, extract personal data flows and construct a personal data flow graph, and conduct analysis of the data flow graph to facilitate insight discovery. The framework consists of a pre-processor, an LLM-based processor, and a data flow post-processor. We demonstrated and validated the effectiveness and accuracy of the proposed approach by conducting a case study that involved examining ten selected privacy policies from the automotive industry. Moreover, it is worth noting that LADFA is designed to be flexible and customisable, making it suitable for a range of text-based analysis tasks beyond privacy policy analysis.
Analysing Safety Risks in LLMs Fine-Tuned with Pseudo-Malicious Cyber Security Data
May 15, 2025The integration of large language models (LLMs) into cyber security applications presents significant opportunities, such as enhancing threat analysis and malware detection, but can also introduce critical risks and safety concerns, including personal data leakage and automated generation of new malware. We present a systematic evaluation of safety risks in fine-tuned LLMs for cyber security applications. Using the OWASP Top 10 for LLM Applications framework, we assessed seven open-source LLMs: Phi 3 Mini 3.8B, Mistral 7B, Qwen 2.5 7B, Llama 3 8B, Llama 3.1 8B, Gemma 2 9B, and Llama 2 70B. Our evaluation shows that fine-tuning reduces safety resilience across all tested LLMs (e.g., the safety score of Llama 3.1 8B against prompt injection drops from 0.95 to 0.15). We propose and evaluate a safety alignment approach that carefully rewords instruction-response pairs to include explicit safety precautions and ethical considerations. This approach demonstrates that it is possible to maintain or even improve model safety while preserving technical utility, offering a practical path forward for developing safer fine-tuning methodologies. This work offers a systematic evaluation for safety risks in LLMs, enabling safer adoption of generative AI in sensitive domains, and contributing towards the development of secure, trustworthy, and ethically aligned LLMs.
FACTors: A New Dataset for Studying the Fact-checking Ecosystem
May 14, 2025Our fight against false information is spearheaded by fact-checkers. They investigate the veracity of claims and document their findings as fact-checking reports. With the rapid increase in the amount of false information circulating online, the use of automation in fact-checking processes aims to strengthen this ecosystem by enhancing scalability. Datasets containing fact-checked claims play a key role in developing such automated solutions. However, to the best of our knowledge, there is no fact-checking dataset at the ecosystem level, covering claims from a sufficiently long period of time and sourced from a wide range of actors reflecting the entire ecosystem that admittedly follows widely-accepted codes and principles of fact-checking. We present a new dataset FACTors, the first to fill this gap by presenting ecosystem-level data on fact-checking. It contains 118,112 claims from 117,993 fact-checking reports in English (co-)authored by 1,953 individuals and published during the period of 1995-2025 by 39 fact-checking organisations that are active signatories of the IFCN (International Fact-Checking Network) and/or EFCSN (European Fact-Checking Standards Network). It contains 7,327 overlapping claims investigated by multiple fact-checking organisations, corresponding to 2,977 unique claims. It allows to conduct new ecosystem-level studies of the fact-checkers (organisations and individuals). To demonstrate the usefulness of FACTors, we present three example applications, including a first-of-its-kind statistical analysis of the fact-checking ecosystem, examining the political inclinations of the fact-checking organisations, and attempting to assign a credibility score to each organisation based on the findings of the statistical analysis and political leanings. Our methods for constructing FACTors are generic and can be used to maintain a live dataset that can be updated dynamically.
Using LLMs for Automated Privacy Policy Analysis: Prompt Engineering, Fine-Tuning and Explainability
Mar 16, 2025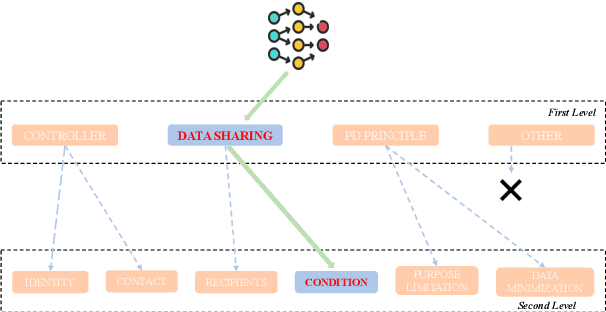
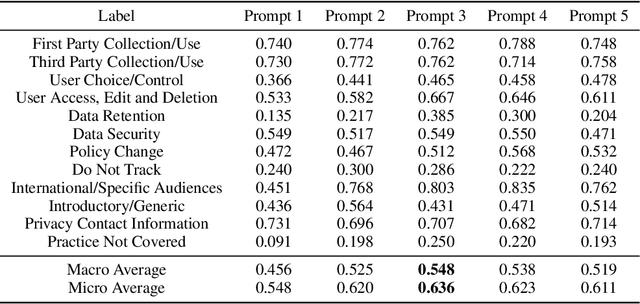
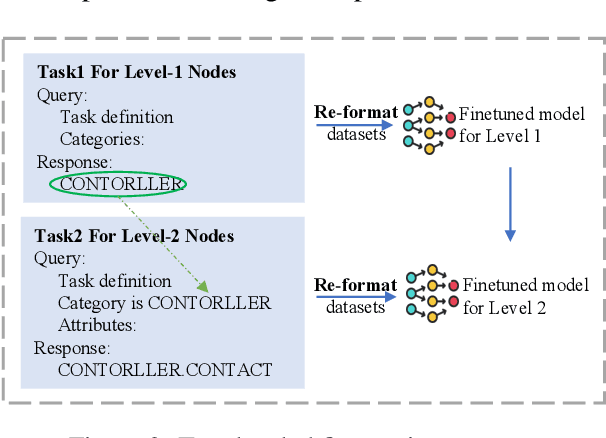
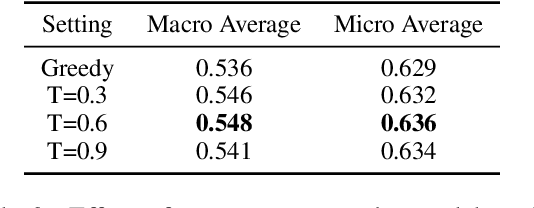
Privacy policies are widely used by digital services and often required for legal purposes. Many machine learning based classifiers have been developed to automate detection of different concepts in a given privacy policy, which can help facilitate other automated tasks such as producing a more reader-friendly summary and detecting legal compliance issues. Despite the successful applications of large language models (LLMs) to many NLP tasks in various domains, there is very little work studying the use of LLMs for automated privacy policy analysis, therefore, if and how LLMs can help automate privacy policy analysis remains under-explored. To fill this research gap, we conducted a comprehensive evaluation of LLM-based privacy policy concept classifiers, employing both prompt engineering and LoRA (low-rank adaptation) fine-tuning, on four state-of-the-art (SOTA) privacy policy corpora and taxonomies. Our experimental results demonstrated that combining prompt engineering and fine-tuning can make LLM-based classifiers outperform other SOTA methods, \emph{significantly} and \emph{consistently} across privacy policy corpora/taxonomies and concepts. Furthermore, we evaluated the explainability of the LLM-based classifiers using three metrics: completeness, logicality, and comprehensibility. For all three metrics, a score exceeding 91.1\% was observed in our evaluation, indicating that LLMs are not only useful to improve the classification performance, but also to enhance the explainability of detection results.
CyberLLMInstruct: A New Dataset for Analysing Safety of Fine-Tuned LLMs Using Cyber Security Data
Mar 12, 2025The integration of large language models (LLMs) into cyber security applications presents significant opportunities, such as enhancing threat analysis and malware detection, but can also introduce critical risks and safety concerns, including personal data leakage and automated generation of new malware. To address these challenges, we developed CyberLLMInstruct, a dataset of 54,928 instruction-response pairs spanning cyber security tasks such as malware analysis, phishing simulations, and zero-day vulnerabilities. The dataset was constructed through a multi-stage process. This involved sourcing data from multiple resources, filtering and structuring it into instruction-response pairs, and aligning it with real-world scenarios to enhance its applicability. Seven open-source LLMs were chosen to test the usefulness of CyberLLMInstruct: Phi 3 Mini 3.8B, Mistral 7B, Qwen 2.5 7B, Llama 3 8B, Llama 3.1 8B, Gemma 2 9B, and Llama 2 70B. In our primary example, we rigorously assess the safety of fine-tuned models using the OWASP top 10 framework, finding that fine-tuning reduces safety resilience across all tested LLMs and every adversarial attack (e.g., the security score of Llama 3.1 8B against prompt injection drops from 0.95 to 0.15). In our second example, we show that these same fine-tuned models can also achieve up to 92.50 percent accuracy on the CyberMetric benchmark. These findings highlight a trade-off between performance and safety, showing the importance of adversarial testing and further research into fine-tuning methodologies that can mitigate safety risks while still improving performance across diverse datasets and domains. All scripts required to reproduce the dataset, along with examples and relevant resources for replicating our results, will be made available upon the paper's acceptance.
Adaptive Backdoor Attacks with Reasonable Constraints on Graph Neural Networks
Mar 12, 2025
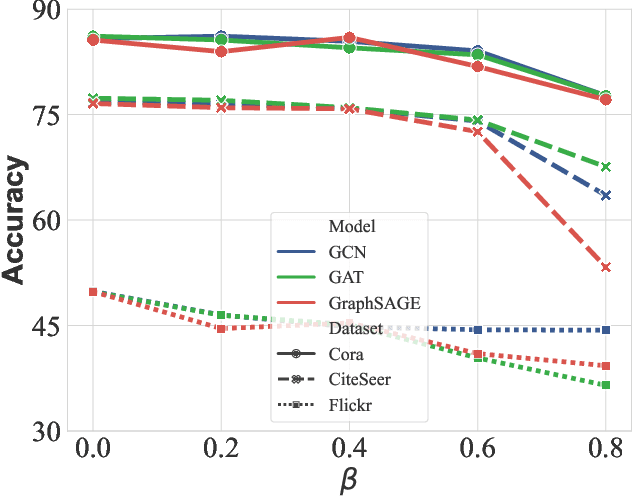
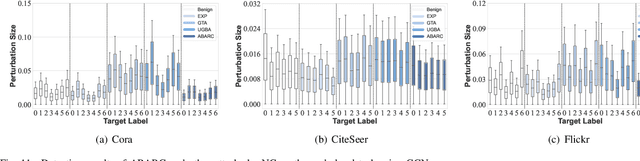
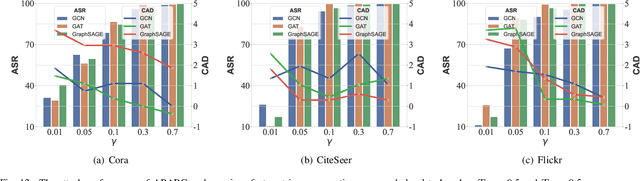
Recent studies show that graph neural networks (GNNs) are vulnerable to backdoor attacks. Existing backdoor attacks against GNNs use fixed-pattern triggers and lack reasonable trigger constraints, overlooking individual graph characteristics and rendering insufficient evasiveness. To tackle the above issues, we propose ABARC, the first Adaptive Backdoor Attack with Reasonable Constraints, applying to both graph-level and node-level tasks in GNNs. For graph-level tasks, we propose a subgraph backdoor attack independent of the graph's topology. It dynamically selects trigger nodes for each target graph and modifies node features with constraints based on graph similarity, feature range, and feature type. For node-level tasks, our attack begins with an analysis of node features, followed by selecting and modifying trigger features, which are then constrained by node similarity, feature range, and feature type. Furthermore, an adaptive edge-pruning mechanism is designed to reduce the impact of neighbors on target nodes, ensuring a high attack success rate (ASR). Experimental results show that even with reasonable constraints for attack evasiveness, our attack achieves a high ASR while incurring a marginal clean accuracy drop (CAD). When combined with the state-of-the-art defense randomized smoothing (RS) method, our attack maintains an ASR over 94%, surpassing existing attacks by more than 7%.
"I know myself better, but not really greatly": Using LLMs to Detect and Explain LLM-Generated Texts
Feb 18, 2025Large language models (LLMs) have demonstrated impressive capabilities in generating human-like texts, but the potential misuse of such LLM-generated texts raises the need to distinguish between human-generated and LLM-generated content. This paper explores the detection and explanation capabilities of LLM-based detectors of LLM-generated texts, in the context of a binary classification task (human-generated texts vs LLM-generated texts) and a ternary classification task (human-generated texts, LLM-generated texts, and undecided). By evaluating on six close/open-source LLMs with different sizes, our findings reveal that while self-detection consistently outperforms cross-detection, i.e., LLMs can detect texts generated by themselves more accurately than those generated by other LLMs, the performance of self-detection is still far from ideal, indicating that further improvements are needed. We also show that extending the binary to the ternary classification task with a new class "Undecided" can enhance both detection accuracy and explanation quality, with improvements being statistically significant and consistent across all LLMs. We finally conducted comprehensive qualitative and quantitative analyses on the explanation errors, which are categorized into three types: reliance on inaccurate features (the most frequent error), hallucinations, and incorrect reasoning. These findings with our human-annotated dataset emphasize the need for further research into improving both self-detection and self-explanation, particularly to address overfitting issues that may hinder generalization.
Local Differential Privacy is Not Enough: A Sample Reconstruction Attack against Federated Learning with Local Differential Privacy
Feb 12, 2025
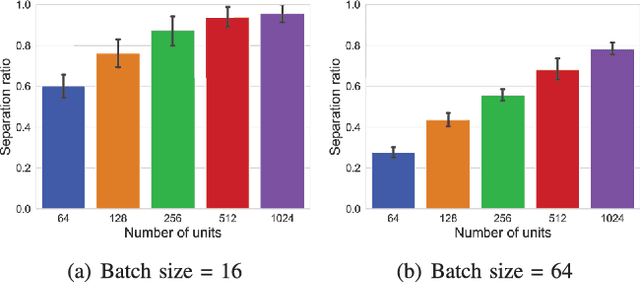
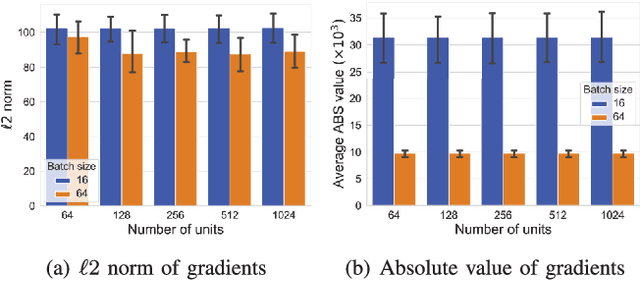
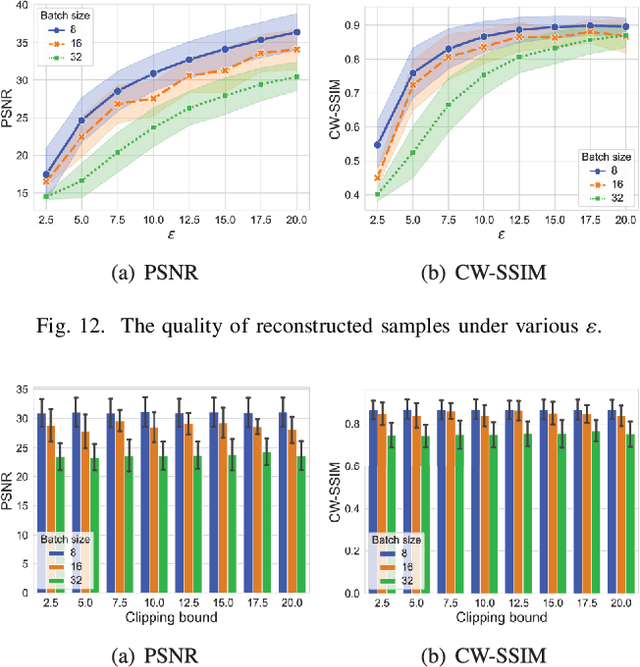
Reconstruction attacks against federated learning (FL) aim to reconstruct users' samples through users' uploaded gradients. Local differential privacy (LDP) is regarded as an effective defense against various attacks, including sample reconstruction in FL, where gradients are clipped and perturbed. Existing attacks are ineffective in FL with LDP since clipped and perturbed gradients obliterate most sample information for reconstruction. Besides, existing attacks embed additional sample information into gradients to improve the attack effect and cause gradient expansion, leading to a more severe gradient clipping in FL with LDP. In this paper, we propose a sample reconstruction attack against LDP-based FL with any target models to reconstruct victims' sensitive samples to illustrate that FL with LDP is not flawless. Considering gradient expansion in reconstruction attacks and noise in LDP, the core of the proposed attack is gradient compression and reconstructed sample denoising. For gradient compression, an inference structure based on sample characteristics is presented to reduce redundant gradients against LDP. For reconstructed sample denoising, we artificially introduce zero gradients to observe noise distribution and scale confidence interval to filter the noise. Theoretical proof guarantees the effectiveness of the proposed attack. Evaluations show that the proposed attack is the only attack that reconstructs victims' training samples in LDP-based FL and has little impact on the target model's accuracy. We conclude that LDP-based FL needs further improvements to defend against sample reconstruction attacks effectively.
Band Prompting Aided SAR and Multi-Spectral Data Fusion Framework for Local Climate Zone Classification
Dec 24, 2024



Local climate zone (LCZ) classification is of great value for understanding the complex interactions between urban development and local climate. Recent studies have increasingly focused on the fusion of synthetic aperture radar (SAR) and multi-spectral data to improve LCZ classification performance. However, it remains challenging due to the distinct physical properties of these two types of data and the absence of effective fusion guidance. In this paper, a novel band prompting aided data fusion framework is proposed for LCZ classification, namely BP-LCZ, which utilizes textual prompts associated with band groups to guide the model in learning the physical attributes of different bands and semantics of various categories inherent in SAR and multi-spectral data to augment the fused feature, thus enhancing LCZ classification performance. Specifically, a band group prompting (BGP) strategy is introduced to align the visual representation effectively at the level of band groups, which also facilitates a more adequate extraction of semantic information of different bands with textual information. In addition, a multivariate supervised matrix (MSM) based training strategy is proposed to alleviate the problem of positive and negative sample confusion by completing the supervised information. The experimental results demonstrate the effectiveness and superiority of the proposed data fusion framework.