 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACTors: A New Dataset for Studying the Fact-checking Ecosystem
May 14, 2025Our fight against false information is spearheaded by fact-checkers. They investigate the veracity of claims and document their findings as fact-checking reports. With the rapid increase in the amount of false information circulating online, the use of automation in fact-checking processes aims to strengthen this ecosystem by enhancing scalability. Datasets containing fact-checked claims play a key role in developing such automated solutions. However, to the best of our knowledge, there is no fact-checking dataset at the ecosystem level, covering claims from a sufficiently long period of time and sourced from a wide range of actors reflecting the entire ecosystem that admittedly follows widely-accepted codes and principles of fact-checking. We present a new dataset FACTors, the first to fill this gap by presenting ecosystem-level data on fact-checking. It contains 118,112 claims from 117,993 fact-checking reports in English (co-)authored by 1,953 individuals and published during the period of 1995-2025 by 39 fact-checking organisations that are active signatories of the IFCN (International Fact-Checking Network) and/or EFCSN (European Fact-Checking Standards Network). It contains 7,327 overlapping claims investigated by multiple fact-checking organisations, corresponding to 2,977 unique claims. It allows to conduct new ecosystem-level studies of the fact-checkers (organisations and individuals). To demonstrate the usefulness of FACTors, we present three example applications, including a first-of-its-kind statistical analysis of the fact-checking ecosystem, examining the political inclinations of the fact-checking organisations, and attempting to assign a credibility score to each organisation based on the findings of the statistical analysis and political leanings. Our methods for constructing FACTors are generic and can be used to maintain a live dataset that can be updated dynamically.
aedFaCT: Scientific Fact-Checking Made Easier via Semi-Automatic Discovery of Relevant Expert Opinions
May 12, 2023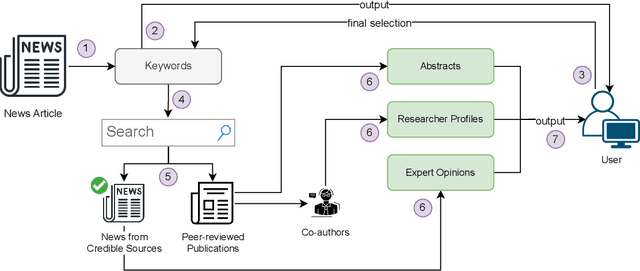

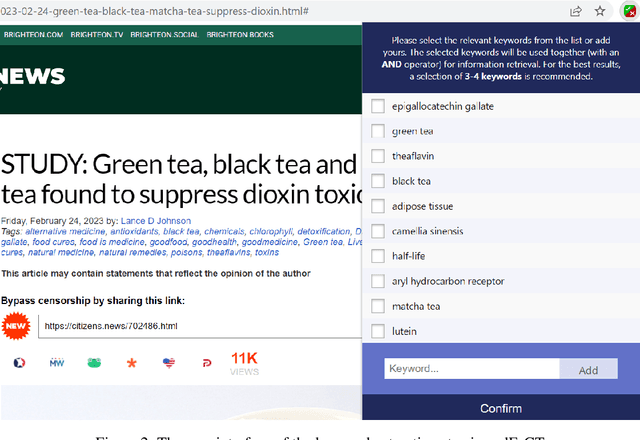

In this highly digitised world, fake news is a challenging problem that can cause serious harm to society. Considering how fast fake news can spread, automated methods, tools and services for assisting users to do fact-checking (i.e., fake news detection) become necessary and helpful, for both professionals, such as journalists and researchers, and the general public such as news readers. Experts, especially researchers, play an essential role in informing people about truth and facts, which makes them a good proxy for non-experts to detect fake news by checking relevant expert opinions and comments. Therefore, in this paper, we present aedFaCT, a web browser extension that can help professionals and news readers perform fact-checking via the automatic discovery of expert opinions relevant to the news of concern via shared keywords. Our initial evaluation with three independent testers (who did not participate in the development of the extension) indicated that aedFaCT can provide a faster experience to its users compared with traditional fact-checking practices based on manual online searches, without degrading the quality of retrieved evidence for fact-checking. The source code of aedFaCT is publicly available at https://github.com/altuncu/aedFaCT.
Improving Performance of Automatic Keyword Extraction (AKE) Methods Using PoS-Tagging and Enhanced Semantic-Awareness
Nov 09, 2022



Automatic keyword extraction (AKE) has gained more importance with the increasing amount of digital textual data that modern computing systems process. It has various applications in information retrieval (IR) and natural language processing (NLP), including text summarisation, topic analysis and document indexing. This paper proposes a simple but effective post-processing-based universal approach to improve the performance of any AKE methods, via an enhanced level of semantic-awareness supported by PoS-tagging. To demonstrate the performance of the proposed approach, we considered word types retrieved from a PoS-tagging step and two representative sources of semantic information -- specialised terms defined in one or more context-dependent thesauri, and named entities in Wikipedia. The above three steps can be simply added to the end of any AKE methods as part of a post-processor, which simply re-evaluate all candidate keywords following some context-specific and semantic-aware criteria. For five state-of-the-art (SOTA) AKE methods, our experimental results with 17 selected datasets showed that the proposed approach improved their performances both consistently (up to 100\% in terms of improved cases) and significantly (between 10.2\% and 53.8\%, with an average of 25.8\%, in terms of F1-score and across all five methods), especially when all the three enhancement steps are used. Our results have profound implications considering the ease to apply our proposed approach to any AKE methods and to further extend it.
Graphical Models of False Information and Fact Checking Ecosystems
Aug 24, 2022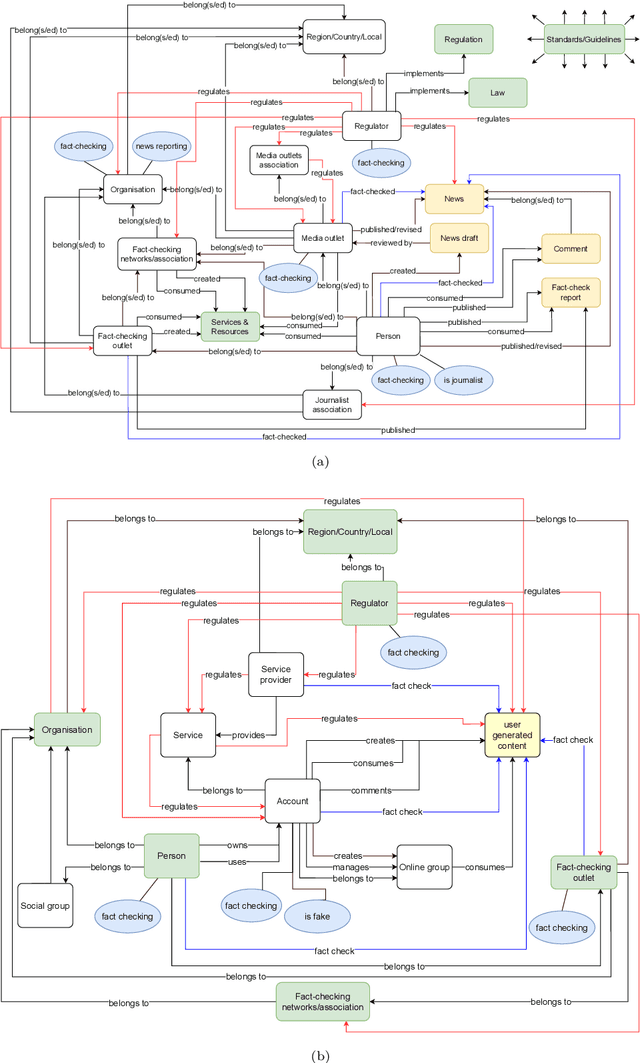
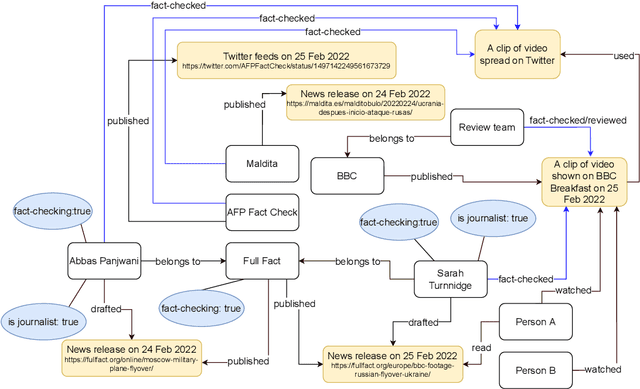
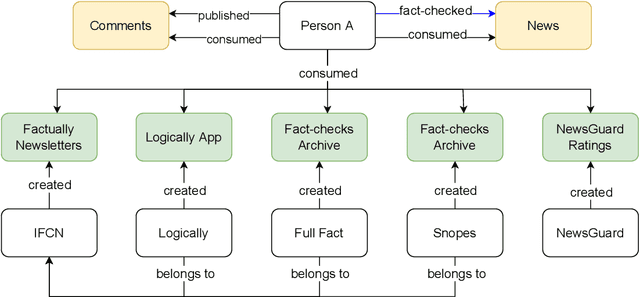
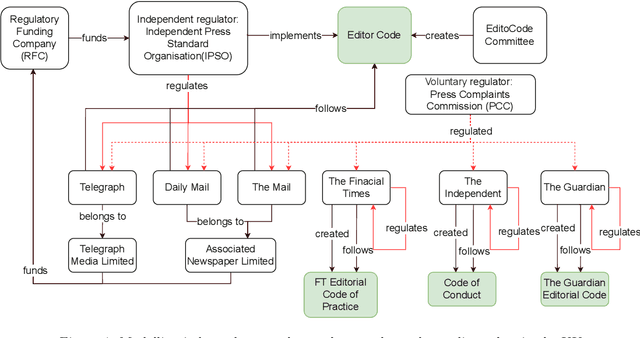
The wide spread of false information online including misinformation and disinformation has become a major problem for our highly digitised and globalised society. A lot of research has been done to better understand different aspects of false information online such as behaviours of different actors and patterns of spreading, and also on better detection and prevention of such information using technical and socio-technical means. One major approach to detect and debunk false information online is to use human fact-checkers, who can be helped by automated tools. Despite a lot of research done, we noticed a significant gap on the lack of conceptual models describing the complicated ecosystems of false information and fact checking. In this paper, we report the first graphical models of such ecosystems, focusing on false information online in multiple contexts, including traditional media outlets and user-generated content. The proposed models cover a wide range of entity types and relationships, and can be a new useful tool for researchers and practitioners to study false information online and the effects of fact checking.
Deepfake: Definitions, Performance Metrics and Standards, Datasets and Benchmarks, and a Meta-Review
Aug 21, 2022
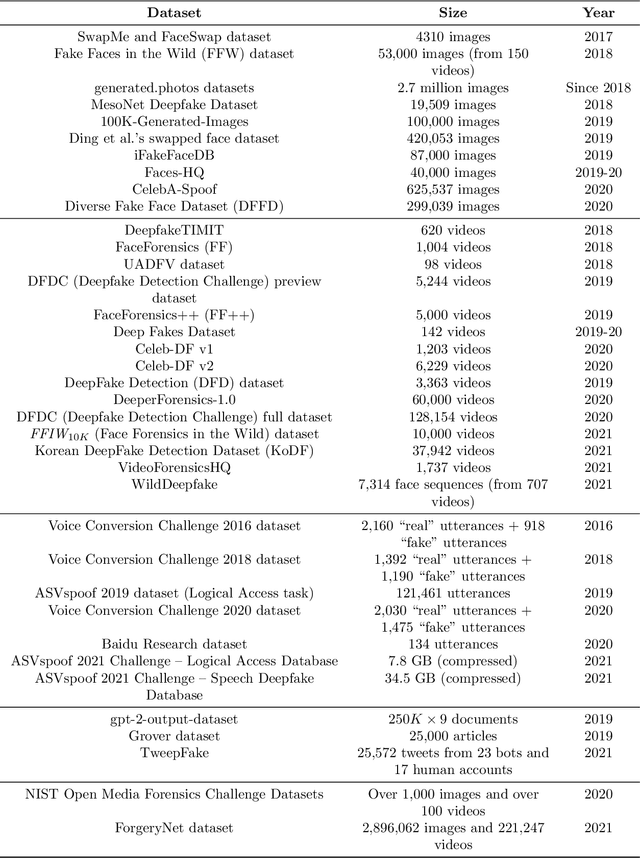
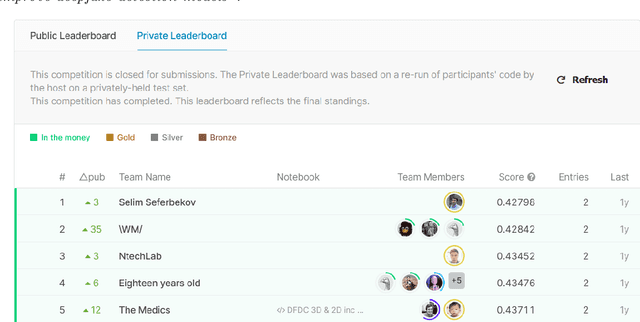
Recent advancements in AI, especially deep learning, have contributed to a significant increase in the creation of new realistic-looking synthetic media (video, image, and audio) and manipulation of existing media, which has led to the creation of the new term ``deepfake''. Based on both the research literature and resources in English and in Chinese, this paper gives a comprehensive overview of deepfake, covering multiple important aspects of this emerging concept, including 1) different definitions, 2) commonly used performance metrics and standards, and 3) deepfake-related datasets, challenges, competitions and benchmarks. In addition, the paper also reports a meta-review of 12 selected deepfake-related survey papers published in 2020 and 2021, focusing not only on the mentioned aspects, but also on the analysis of key challenges and recommendations. We believe that this paper is the most comprehensive review of deepfake in terms of aspects covered, and the first one covering both the English and Chinese literature and sources.
A Comprehensive Survey of Natural Language Generation Advances from the Perspective of Digital Deception
Aug 11, 2022

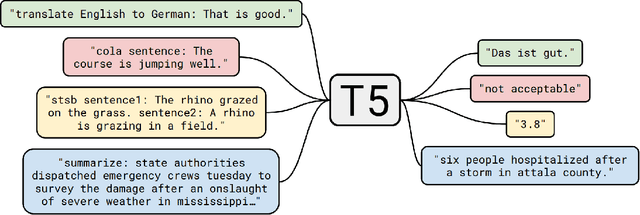

In recent years there has been substantial growth in the capabilities of systems designed to generate text that mimics the fluency and coherence of human language. From this, there has been considerable research aimed at examining the potential uses of these natural language generators (NLG) towards a wide number of tasks. The increasing capabilities of powerful text generators to mimic human writing convincingly raises the potential for deception and other forms of dangerous misuse. As these systems improve, and it becomes ever harder to distinguish between human-written and machine-generated text, malicious actors could leverage these powerful NLG systems to a wide variety of ends, including the creation of fake news and misinformation, the generation of fake online product reviews, or via chatbots as means of convincing users to divulge private information. In this paper, we provide an overview of the NLG field via the identification and examination of 119 survey-like papers focused on NLG research. From these identified papers, we outline a proposed high-level taxonomy of the central concepts that constitute NLG, including the methods used to develop generalised NLG systems, the means by which these systems are evaluated, and the popular NLG tasks and subtasks that exist. In turn, we provide an overview and discussion of each of these items with respect to current research and offer an examination of the potential roles of NLG in deception and detection systems to counteract these threats. Moreover, we discuss the broader challenges of NLG, including the risks of bias that are often exhibited by existing text generation systems. This work offers a broad overview of the field of NLG with respect to its potential for misuse, aiming to provide a high-level understanding of this rapidly developing area of research.