 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Patch or Not to Patch: Motivations, Challenges, and Implications for Cybersecurity
Feb 24, 2025As technology has become more embedded into our society, the security of modern-day systems is paramount. One topic which is constantly under discussion is that of patching, or more specifically, the installation of updates that remediate security vulnerabilities in software or hardware systems. This continued deliberation is motivated by complexities involved with patching; in particular, the various incentives and disincentives for organizations and their cybersecurity teams when deciding whether to patch. In this paper, we take a fresh look at the question of patching and critically explore why organizations and IT/security teams choose to patch or decide against it (either explicitly or due to inaction). We tackle this question by aggregating and synthesizing prominent research and industry literature on the incentives and disincentives for patching, specifically considering the human aspects in the context of these motives. Through this research, this study identifies key motivators such as organizational needs, the IT/security team's relationship with vendors, and legal and regulatory requirements placed on the business and its staff. There are also numerous significant reasons discovered for why the decision is taken not to patch, including limited resources (e.g., person-power), challenges with manual patch management tasks, human error, bad patches, unreliable patch management tools, and the perception that related vulnerabilities would not be exploited. These disincentives, in combination with the motivators above, highlight the difficult balance that organizations and their security teams need to maintain on a daily basis. Finally, we conclude by discussing implications of these findings and important future considerations.
AI security and cyber risk in IoT systems
Oct 11, 2024



We present a dependency model tailored to the context of current challenges in data strategies and make recommendations for the cybersecurity community. The model can be used for cyber risk estimation and assessment and generic risk impact assessment.
Embedding Privacy in Computational Social Science and Artificial Intelligence Research
Apr 17, 2024Privacy is a human right. It ensures that individuals are free to engage in discussions, participate in groups, and form relationships online or offline without fear of their data being inappropriately harvested, analyzed, or otherwise used to harm them. Preserving privacy has emerged as a critical factor in research, particularly in the computational social science (CSS), artificial intelligence (AI) and data science domains, given their reliance on individuals' data for novel insights. The increasing use of advanced computational models stands to exacerbate privacy concerns because, if inappropriately used, they can quickly infringe privacy rights and lead to adverse effects for individuals - especially vulnerable groups - and society. We have already witnessed a host of privacy issues emerge with the advent of large language models (LLMs), such as ChatGPT, which further demonstrate the importance of embedding privacy from the start. This article contributes to the field by discussing the role of privacy and the primary issues that researchers working in CSS, AI, data science and related domains are likely to face. It then presents several key considerations for researchers to ensure participant privacy is best preserved in their research design, data collection and use, analysis, and dissemination of research results.
aedFaCT: Scientific Fact-Checking Made Easier via Semi-Automatic Discovery of Relevant Expert Opinions
May 12, 2023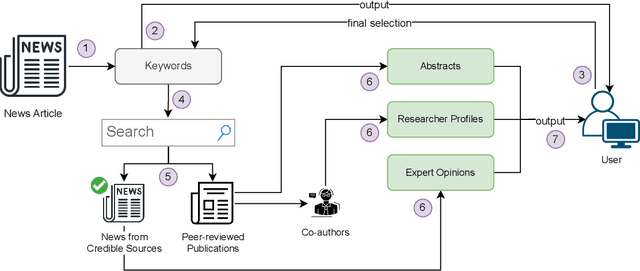

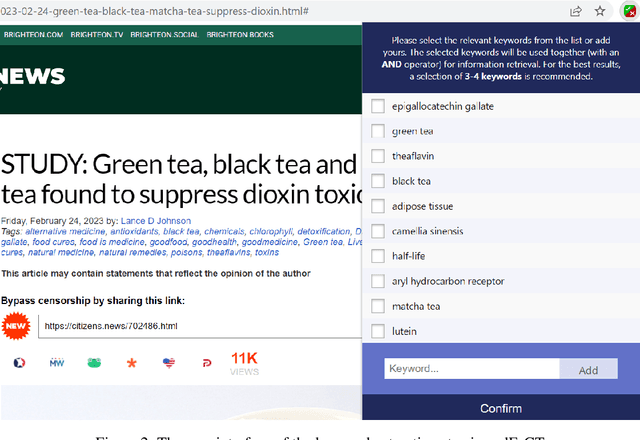

In this highly digitised world, fake news is a challenging problem that can cause serious harm to society. Considering how fast fake news can spread, automated methods, tools and services for assisting users to do fact-checking (i.e., fake news detection) become necessary and helpful, for both professionals, such as journalists and researchers, and the general public such as news readers. Experts, especially researchers, play an essential role in informing people about truth and facts, which makes them a good proxy for non-experts to detect fake news by checking relevant expert opinions and comments. Therefore, in this paper, we present aedFaCT, a web browser extension that can help professionals and news readers perform fact-checking via the automatic discovery of expert opinions relevant to the news of concern via shared keywords. Our initial evaluation with three independent testers (who did not participate in the development of the extension) indicated that aedFaCT can provide a faster experience to its users compared with traditional fact-checking practices based on manual online searches, without degrading the quality of retrieved evidence for fact-checking. The source code of aedFaCT is publicly available at https://github.com/altuncu/aedFaCT.
Improving Performance of Automatic Keyword Extraction (AKE) Methods Using PoS-Tagging and Enhanced Semantic-Awareness
Nov 09, 2022



Automatic keyword extraction (AKE) has gained more importance with the increasing amount of digital textual data that modern computing systems process. It has various applications in information retrieval (IR) and natural language processing (NLP), including text summarisation, topic analysis and document indexing. This paper proposes a simple but effective post-processing-based universal approach to improve the performance of any AKE methods, via an enhanced level of semantic-awareness supported by PoS-tagging. To demonstrate the performance of the proposed approach, we considered word types retrieved from a PoS-tagging step and two representative sources of semantic information -- specialised terms defined in one or more context-dependent thesauri, and named entities in Wikipedia. The above three steps can be simply added to the end of any AKE methods as part of a post-processor, which simply re-evaluate all candidate keywords following some context-specific and semantic-aware criteria. For five state-of-the-art (SOTA) AKE methods, our experimental results with 17 selected datasets showed that the proposed approach improved their performances both consistently (up to 100\% in terms of improved cases) and significantly (between 10.2\% and 53.8\%, with an average of 25.8\%, in terms of F1-score and across all five methods), especially when all the three enhancement steps are used. Our results have profound implications considering the ease to apply our proposed approach to any AKE methods and to further extend it.
Perspectives of Non-Expert Users on Cyber Security and Privacy: An Analysis of Online Discussions on Twitter
Jun 05, 2022
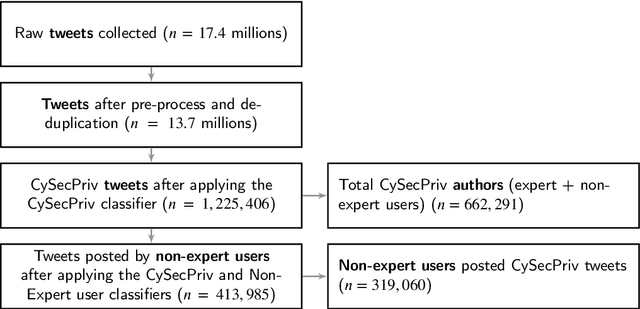
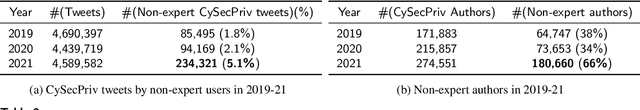
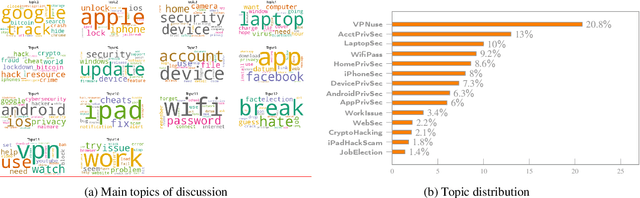
Current research on users` perspectives of cyber security and privacy related to traditional and smart devices at home is very active, but the focus is often more on specific modern devices such as mobile and smart IoT devices in a home context. In addition, most were based on smaller-scale empirical studies such as online surveys and interviews. We endeavour to fill these research gaps by conducting a larger-scale study based on a real-world dataset of 413,985 tweets posted by non-expert users on Twitter in six months of three consecutive years (January and February in 2019, 2020 and 2021). Two machine learning-based classifiers were developed to identify the 413,985 tweets. We analysed this dataset to understand non-expert users` cyber security and privacy perspectives, including the yearly trend and the impact of the COVID-19 pandemic. We applied topic modelling, sentiment analysis and qualitative analysis of selected tweets in the dataset, leading to various interesting findings. For instance, we observed a 54% increase in non-expert users` tweets on cyber security and/or privacy related topics in 2021, compared to before the start of global COVID-19 lockdowns (January 2019 to February 2020). We also observed an increased level of help-seeking tweets during the COVID-19 pandemic. Our analysis revealed a diverse range of topics discussed by non-expert users across the three years, including VPNs, Wi-Fi, smartphones, laptops, smart home devices, financial security, and security and privacy issues involving different stakeholders. Overall negative sentiment was observed across almost all topics non-expert users discussed on Twitter in all the three years. Our results confirm the multi-faceted nature of non-expert users` perspectives on cyber security and privacy and call for more holistic, comprehensive and nuanced research on different facets of such perspectives.
Are You Robert or RoBERTa? Deceiving Online Authorship Attribution Models Using Neural Text Generators
Mar 18, 2022
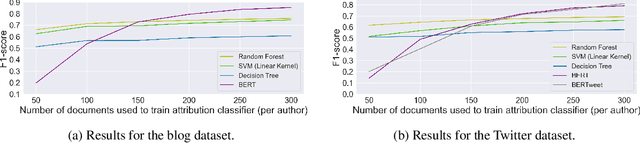

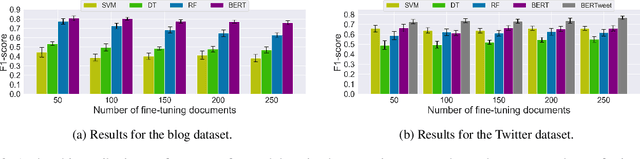
Recently, there has been a rise in the development of powerful pre-trained natural language models, including GPT-2, Grover, and XLM. These models have shown state-of-the-art capabilities towards a variety of different NLP tasks, including question answering, content summarisation, and text generation. Alongside this, there have been many studies focused on online authorship attribution (AA). That is, the use of models to identify the authors of online texts. Given the power of natural language models in generating convincing texts, this paper examines the degree to which these language models can generate texts capable of deceiving online AA models. Experimenting with both blog and Twitter data, we utilise GPT-2 language models to generate texts using the existing posts of online users. We then examine whether these AI-based text generators are capable of mimicking authorial style to such a degree that they can deceive typical AA models. From this, we find that current AI-based text generators are able to successfully mimic authorship, showing capabilities towards this on both datasets. Our findings, in turn, highlight the current capacity of powerful natural language models to generate original online posts capable of mimicking authorial style sufficiently to deceive popular AA methods; a key finding given the proposed role of AA in real world applications such as spam-detection and forensic investigation.
A Comparison of Online Hate on Reddit and 4chan: A Case Study of the 2020 US Election
Feb 02, 2022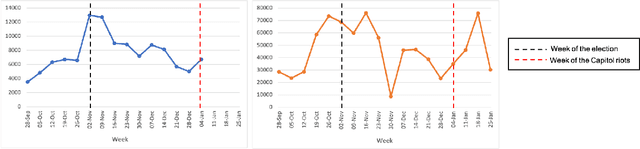
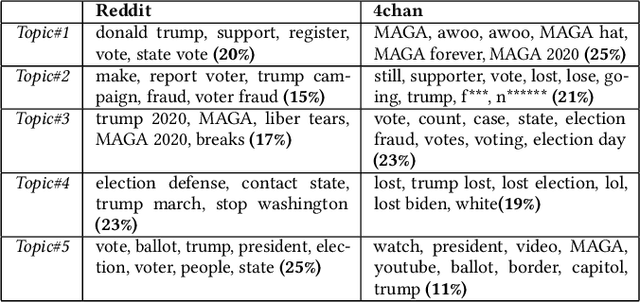
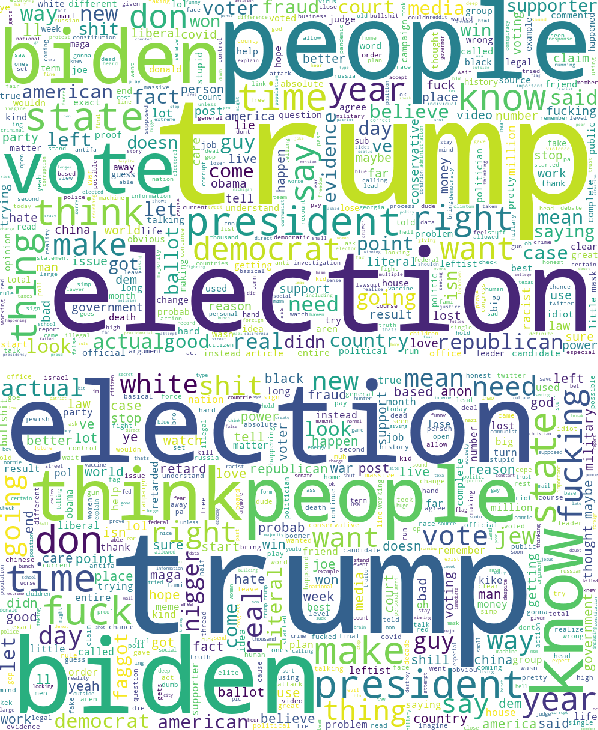

The rapid integration of the Internet into our daily lives has led to many benefits but also to a number of new, wide-spread threats such as online hate, trolling, bullying, and generally aggressive behaviours. While research has traditionally explored online hate, in particular, on one platform, the reality is that such hate is a phenomenon that often makes use of multiple online networks. In this article, we seek to advance the discussion into online hate by harnessing a comparative approach, where we make use of various Natural Language Processing (NLP) techniques to computationally analyse hateful content from Reddit and 4chan relating to the 2020 US Presidential Elections. Our findings show how content and posting activity can differ depending on the platform being used. Through this, we provide initial comparison into the platform-specific behaviours of online hate, and how different platforms can serve specific purposes. We further provide several avenues for future research utilising a cross-platform approach so as to gain a more comprehensive understanding of the global hate ecosystem.
Out of the Shadows: Analyzing Anonymous' Twitter Resurgence during the 2020 Black Lives Matter Protests
Jul 22, 2021
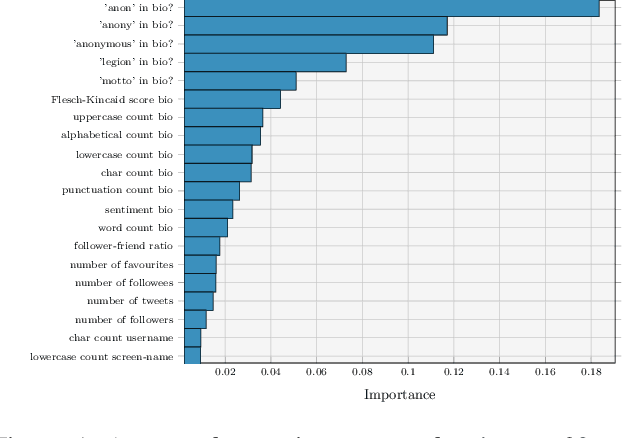
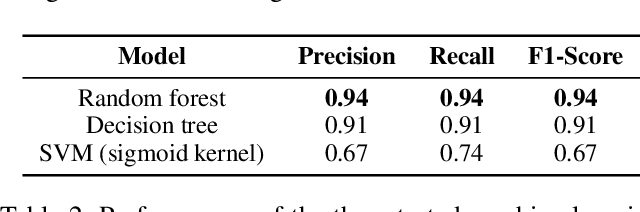
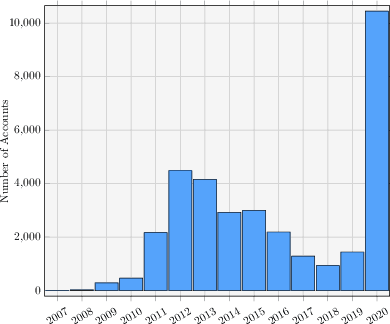
Recently, there had been little notable activity from the once prominent hacktivist group, Anonymous. The group, responsible for activist-based cyber attacks on major businesses and governments, appeared to have fragmented after key members were arrested in 2013. In response to the major Black Lives Matter (BLM) protests that occurred after the killing of George Floyd, however, reports indicated that the group was back. To examine this apparent resurgence, we conduct a large-scale study of Anonymous affiliates on Twitter. To this end, we first use machine learning to identify a significant network of more than 33,000 Anonymous accounts. Through topic modelling of tweets collected from these accounts, we find evidence of sustained interest in topics related to BLM. We then use sentiment analysis on tweets focused on these topics, finding evidence of a united approach amongst the group, with positive tweets typically being used to express support towards BLM, and negative tweets typically being used to criticize police actions. Finally, we examine the presence of automation in the network, identifying indications of bot-like behavior across the majority of Anonymous accounts. These findings show that whilst the group has seen a resurgence during the protests, bot activity may be responsible for exaggerating the extent of this resurgence.
Privacy Concerns in Chatbot Interactions: When to Trust and When to Worry
Jul 08, 2021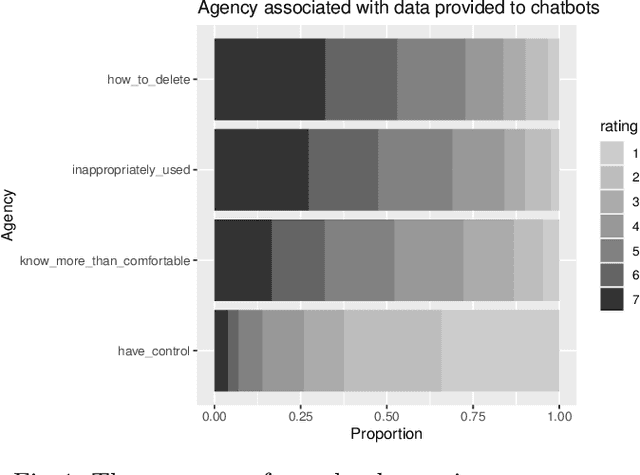
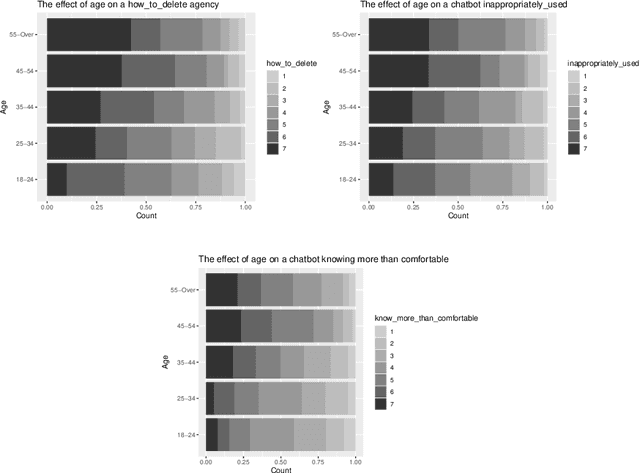
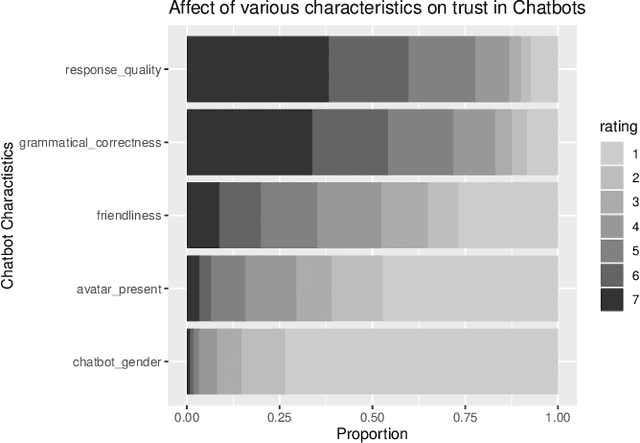
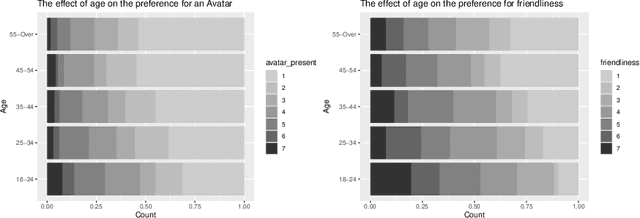
Through advances in their conversational abilities, chatbots have started to request and process an increasing variety of sensitive personal information. The accurate disclosure of sensitive information is essential where it is used to provide advice and support to users in the healthcare and finance sectors. In this study, we explore users' concerns regarding factors associated with the use of sensitive data by chatbot providers. We surveyed a representative sample of 491 British citizens. Our results show that the user concerns focus on deleting personal information and concerns about their data's inappropriate use. We also identified that individuals were concerned about losing control over their data after a conversation with conversational agents. We found no effect from a user's gender or education but did find an effect from the user's age, with those over 45 being more concerned than those under 45. We also considered the factors that engender trust in a chatbot. Our respondents' primary focus was on the chatbot's technical elements, with factors such as the response quality being identified as the most critical factor. We again found no effect from the user's gender or education level; however, when we considered some social factors (e.g. avatars or perceived 'friendliness'), we found those under 45 years old rated these as more important than those over 45. The paper concludes with a discussion of these results within the context of designing inclusive, digital systems that support a wide range of users.