 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeaedFaCT: Scientific Fact-Checking Made Easier via Semi-Automatic Discovery of Relevant Expert Opinions
May 12, 2023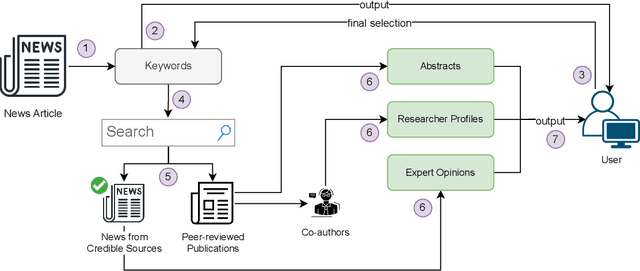

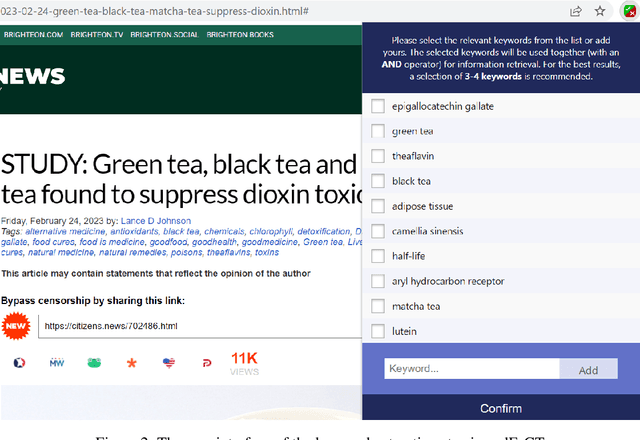

In this highly digitised world, fake news is a challenging problem that can cause serious harm to society. Considering how fast fake news can spread, automated methods, tools and services for assisting users to do fact-checking (i.e., fake news detection) become necessary and helpful, for both professionals, such as journalists and researchers, and the general public such as news readers. Experts, especially researchers, play an essential role in informing people about truth and facts, which makes them a good proxy for non-experts to detect fake news by checking relevant expert opinions and comments. Therefore, in this paper, we present aedFaCT, a web browser extension that can help professionals and news readers perform fact-checking via the automatic discovery of expert opinions relevant to the news of concern via shared keywords. Our initial evaluation with three independent testers (who did not participate in the development of the extension) indicated that aedFaCT can provide a faster experience to its users compared with traditional fact-checking practices based on manual online searches, without degrading the quality of retrieved evidence for fact-checking. The source code of aedFaCT is publicly available at https://github.com/altuncu/aedFaCT.
How good are variational autoencoders at transfer learning?
Apr 21, 2023Variational autoencoders (VAEs) are used for transfer learning across various research domains such as music generation or medical image analysis. However, there is no principled way to assess before transfer which components to retrain or whether transfer learning is likely to help on a target task. We propose to explore this question through the lens of representational similarity. Specifically, using Centred Kernel Alignment (CKA) to evaluate the similarity of VAEs trained on different datasets, we show that encoders' representations are generic but decoders' specific. Based on these insights, we discuss the implications for selecting which components of a VAE to retrain and propose a method to visually assess whether transfer learning is likely to help on classification tasks.
Deconstructing deep active inference
Mar 02, 2023Active inference is a theory of perception, learning and decision making, which can be applied to neuroscience, robotics, and machine learning. Recently, reasearch has been taking place to scale up this framework using Monte-Carlo tree search and deep learning. The goal of this activity is to solve more complicated tasks using deep active inference. First, we review the existing literature, then, we progresively build a deep active inference agent. For two agents, we have experimented with five definitions of the expected free energy and three different action selection strategies. According to our experiments, the models able to solve the dSprites environment are the ones that maximise rewards. Finally, we compare the similarity of the representation learned by the layers of various agents using centered kernel alignment. Importantly, the agent maximising reward and the agent minimising expected free energy learn very similar representations except for the last layer of the critic network (reflecting the difference in learning objective), and the variance layers of the transition and encoder networks. We found that the reward maximising agent is a lot more certain than the agent minimising expected free energy. This is because the agent minimising expected free energy always picks the action down, and does not gather enough data for the other actions. In contrast, the agent maximising reward, keeps on selecting the actions left and right, enabling it to successfully solve the task. The only difference between those two agents is the epistemic value, which aims to make the outputs of the transition and encoder networks as close as possible. Thus, the agent minimising expected free energy picks a single action (down), and becomes an expert at predicting the future when selecting this action. This makes the KL divergence between the output of the transition and encoder networks small.
FONDUE: an algorithm to find the optimal dimensionality of the latent representations of variational autoencoders
Sep 26, 2022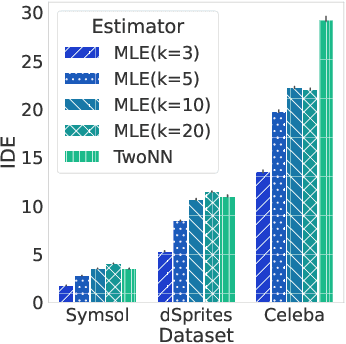

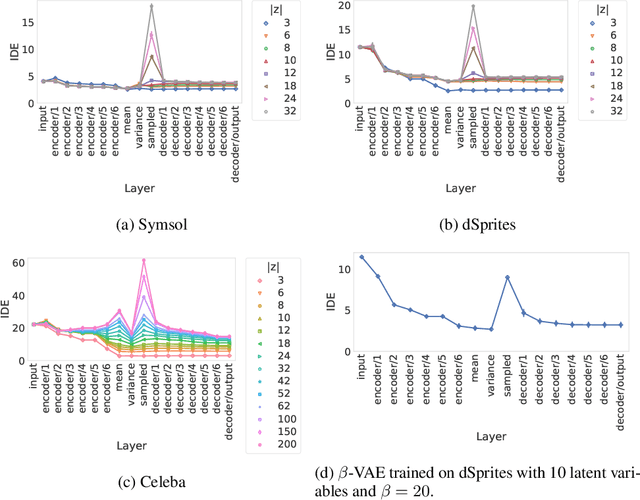

When training a variational autoencoder (VAE) on a given dataset, determining the optimal number of latent variables is mostly done by grid search: a costly process in terms of computational time and carbon footprint. In this paper, we explore the intrinsic dimension estimation (IDE) of the data and latent representations learned by VAEs. We show that the discrepancies between the IDE of the mean and sampled representations of a VAE after only a few steps of training reveal the presence of passive variables in the latent space, which, in well-behaved VAEs, indicates a superfluous number of dimensions. Using this property, we propose FONDUE: an algorithm which quickly finds the number of latent dimensions after which the mean and sampled representations start to diverge (i.e., when passive variables are introduced), providing a principled method for selecting the number of latent dimensions for VAEs and autoencoders.
How do Variational Autoencoders Learn? Insights from Representational Similarity
May 17, 2022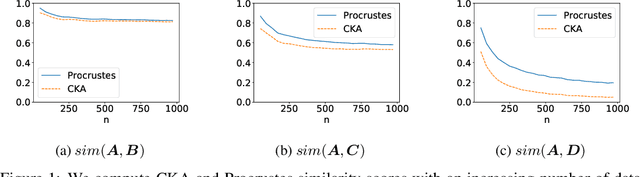


The ability of Variational Autoencoders (VAEs) to learn disentangled representations has made them popular for practical applications. However, their behaviour is not yet fully understood. For example, the questions of when they can provide disentangled representations, or suffer from posterior collapse are still areas of active research. Despite this, there are no layerwise comparisons of the representations learned by VAEs, which would further our understanding of these models. In this paper, we thus look into the internal behaviour of VAEs using representational similarity techniques. Specifically, using the CKA and Procrustes similarities, we found that the encoders' representations are learned long before the decoders', and this behaviour is independent of hyperparameters, learning objectives, and datasets. Moreover, the encoders' representations up to the mean and variance layers are similar across hyperparameters and learning objectives.
Be More Active! Understanding the Differences between Mean and Sampled Representations of Variational Autoencoders
Sep 29, 2021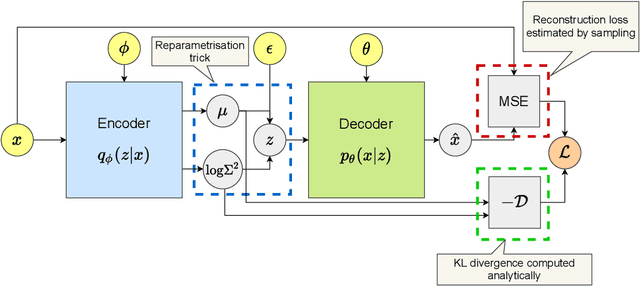
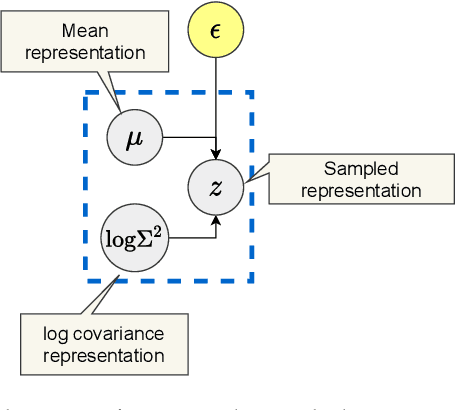
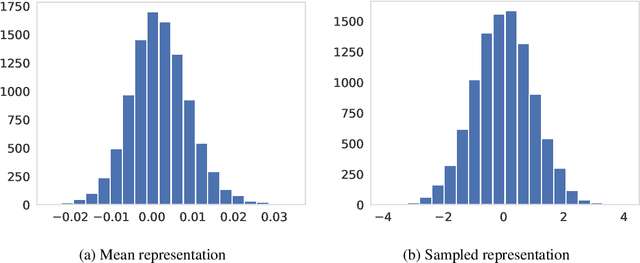
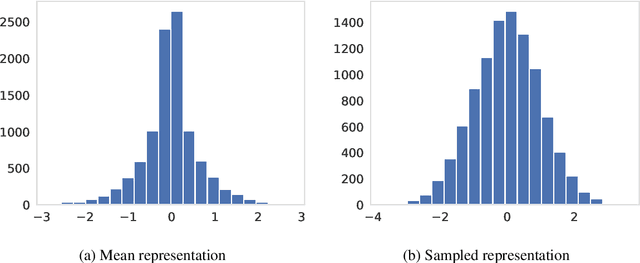
The ability of Variational Autoencoders to learn disentangled representations has made them appealing for practical applications. However, their mean representations, which are generally used for downstream tasks, have recently been shown to be more correlated than their sampled counterpart, on which disentanglement is usually measured. In this paper, we refine this observation through the lens of selective posterior collapse, which states that only a subset of the learned representations, the active variables, is encoding useful information while the rest (the passive variables) is discarded. We first extend the existing definition, originally proposed for sampled representations, to mean representations and show that active variables are equally disentangled in both representations. Based on this new definition and the pre-trained models from disentanglement lib, we then isolate the passive variables and show that they are responsible for the discrepancies between mean and sampled representations. Specifically, passive variables exhibit high correlation scores with other variables in mean representations while being fully uncorrelated in sampled ones. We thus conclude that despite what their higher correlation might suggest, mean representations are still good candidates for downstream tasks applications. However, it may be beneficial to remove their passive variables, especially when used with models sensitive to correlated features.