 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBits of Grass: Does GPT already know how to write like Whitman?
May 10, 2023This study examines the ability of GPT-3.5, GPT-3.5-turbo (ChatGPT) and GPT-4 models to generate poems in the style of specific authors using zero-shot and many-shot prompts (which use the maximum context length of 8192 tokens). We assess the performance of models that are not fine-tuned for generating poetry in the style of specific authors, via automated evaluation. Our findings indicate that without fine-tuning, even when provided with the maximum number of 17 poem examples (8192 tokens) in the prompt, these models do not generate poetry in the desired style.
How good are variational autoencoders at transfer learning?
Apr 21, 2023



Variational autoencoders (VAEs) are used for transfer learning across various research domains such as music generation or medical image analysis. However, there is no principled way to assess before transfer which components to retrain or whether transfer learning is likely to help on a target task. We propose to explore this question through the lens of representational similarity. Specifically, using Centred Kernel Alignment (CKA) to evaluate the similarity of VAEs trained on different datasets, we show that encoders' representations are generic but decoders' specific. Based on these insights, we discuss the implications for selecting which components of a VAE to retrain and propose a method to visually assess whether transfer learning is likely to help on classification tasks.
Crowd Score: A Method for the Evaluation of Jokes using Large Language Model AI Voters as Judges
Dec 21, 2022



This paper presents the Crowd Score, a novel method to assess the funniness of jokes using large language models (LLMs) as AI judges. Our method relies on inducing different personalities into the LLM and aggregating the votes of the AI judges into a single score to rate jokes. We validate the votes using an auditing technique that checks if the explanation for a particular vote is reasonable using the LLM. We tested our methodology on 52 jokes in a crowd of four AI voters with different humour types: affiliative, self-enhancing, aggressive and self-defeating. Our results show that few-shot prompting leads to better results than zero-shot for the voting question. Personality induction showed that aggressive and self-defeating voters are significantly more inclined to find more jokes funny of a set of aggressive/self-defeating jokes than the affiliative and self-enhancing voters. The Crowd Score follows the same trend as human judges by assigning higher scores to jokes that are also considered funnier by human judges. We believe that our methodology could be applied to other creative domains such as story, poetry, slogans, etc. It could both help the adoption of a flexible and accurate standard approach to compare different work in the CC community under a common metric and by minimizing human participation in assessing creative artefacts, it could accelerate the prototyping of creative artefacts and reduce the cost of hiring human participants to rate creative artefacts.
FONDUE: an algorithm to find the optimal dimensionality of the latent representations of variational autoencoders
Sep 26, 2022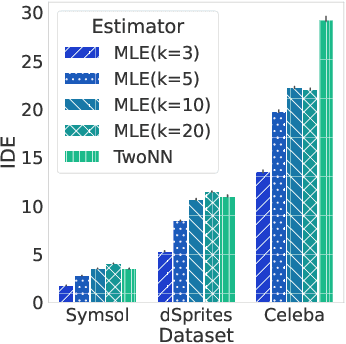

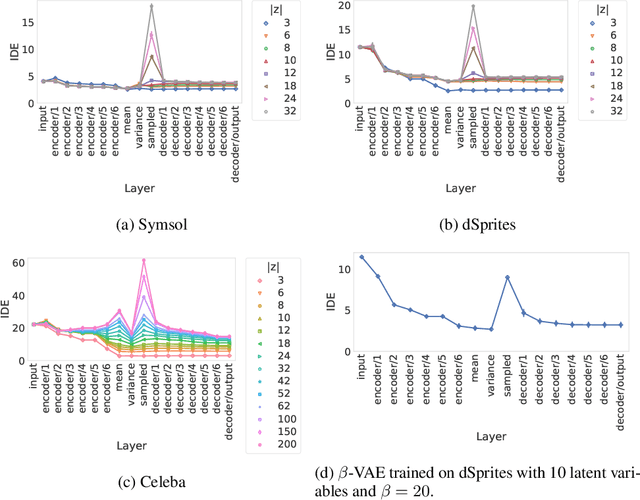

When training a variational autoencoder (VAE) on a given dataset, determining the optimal number of latent variables is mostly done by grid search: a costly process in terms of computational time and carbon footprint. In this paper, we explore the intrinsic dimension estimation (IDE) of the data and latent representations learned by VAEs. We show that the discrepancies between the IDE of the mean and sampled representations of a VAE after only a few steps of training reveal the presence of passive variables in the latent space, which, in well-behaved VAEs, indicates a superfluous number of dimensions. Using this property, we propose FONDUE: an algorithm which quickly finds the number of latent dimensions after which the mean and sampled representations start to diverge (i.e., when passive variables are introduced), providing a principled method for selecting the number of latent dimensions for VAEs and autoencoders.
How do Variational Autoencoders Learn? Insights from Representational Similarity
May 17, 2022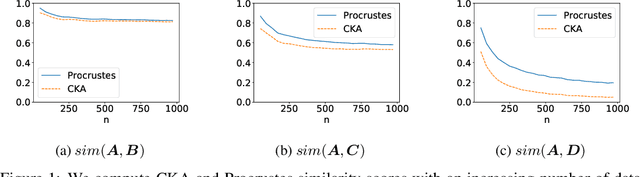


The ability of Variational Autoencoders (VAEs) to learn disentangled representations has made them popular for practical applications. However, their behaviour is not yet fully understood. For example, the questions of when they can provide disentangled representations, or suffer from posterior collapse are still areas of active research. Despite this, there are no layerwise comparisons of the representations learned by VAEs, which would further our understanding of these models. In this paper, we thus look into the internal behaviour of VAEs using representational similarity techniques. Specifically, using the CKA and Procrustes similarities, we found that the encoders' representations are learned long before the decoders', and this behaviour is independent of hyperparameters, learning objectives, and datasets. Moreover, the encoders' representations up to the mean and variance layers are similar across hyperparameters and learning objectives.
Be More Active! Understanding the Differences between Mean and Sampled Representations of Variational Autoencoders
Sep 29, 2021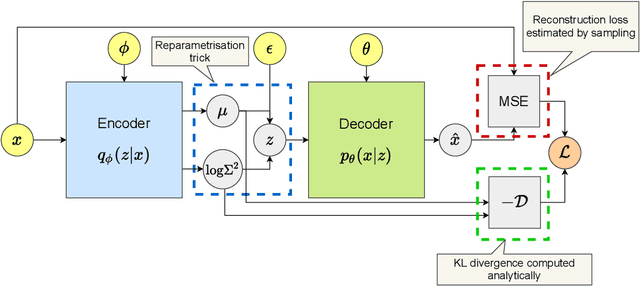
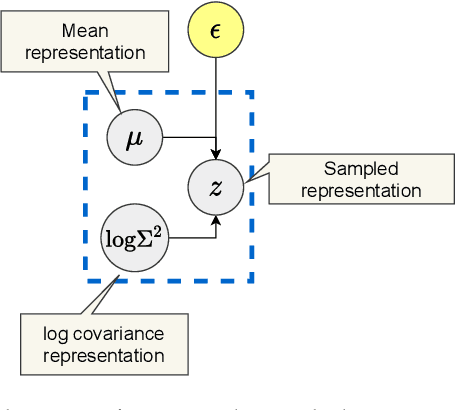
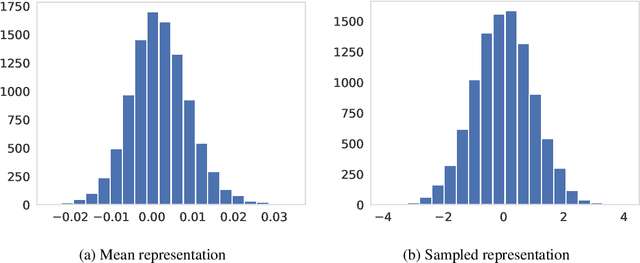
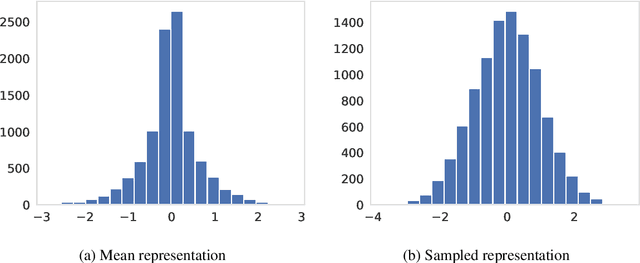
The ability of Variational Autoencoders to learn disentangled representations has made them appealing for practical applications. However, their mean representations, which are generally used for downstream tasks, have recently been shown to be more correlated than their sampled counterpart, on which disentanglement is usually measured. In this paper, we refine this observation through the lens of selective posterior collapse, which states that only a subset of the learned representations, the active variables, is encoding useful information while the rest (the passive variables) is discarded. We first extend the existing definition, originally proposed for sampled representations, to mean representations and show that active variables are equally disentangled in both representations. Based on this new definition and the pre-trained models from disentanglement lib, we then isolate the passive variables and show that they are responsible for the discrepancies between mean and sampled representations. Specifically, passive variables exhibit high correlation scores with other variables in mean representations while being fully uncorrelated in sampled ones. We thus conclude that despite what their higher correlation might suggest, mean representations are still good candidates for downstream tasks applications. However, it may be beneficial to remove their passive variables, especially when used with models sensitive to correlated features.
Reinforcement Learning using Augmented Neural Networks
Jun 20, 2018

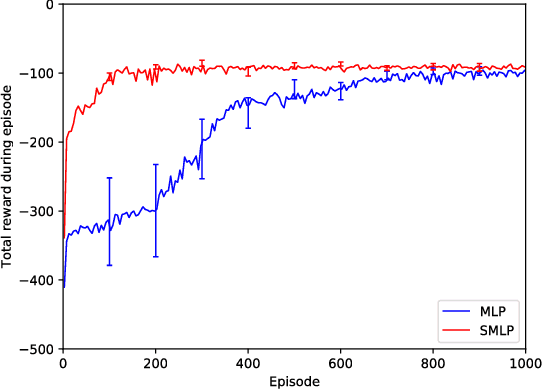
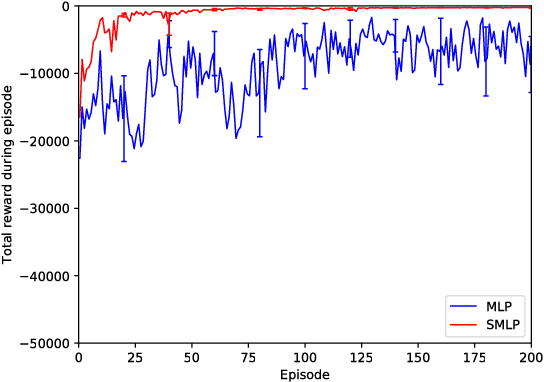
Neural networks allow Q-learning reinforcement learning agents such as deep Q-networks (DQN) to approximate complex mappings from state spaces to value functions. However, this also brings drawbacks when compared to other function approximators such as tile coding or their generalisations, radial basis functions (RBF) because they introduce instability due to the side effect of globalised updates present in neural networks. This instability does not even vanish in neural networks that do not have any hidden layers. In this paper, we show that simple modifications to the structure of the neural network can improve stability of DQN learning when a multi-layer perceptron is used for function approximation.
Improving Language Modelling with Noise-contrastive estimation
Sep 22, 2017
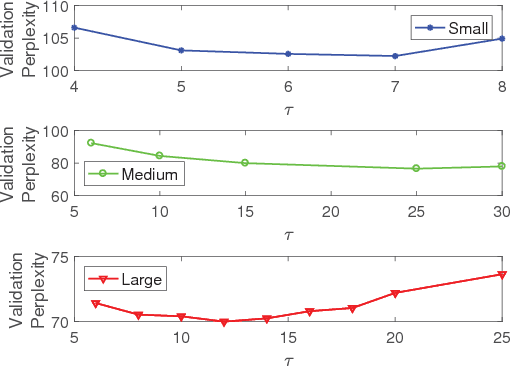

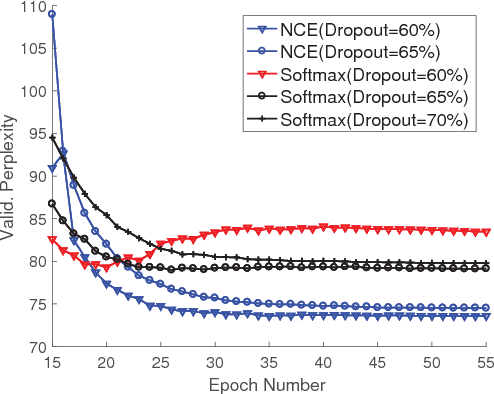
Neural language models do not scale well when the vocabulary is large. Noise-contrastive estimation (NCE) is a sampling-based method that allows for fast learning with large vocabularies. Although NCE has shown promising performance in neural machine translation, it was considered to be an unsuccessful approach for language modelling. A sufficient investigation of the hyperparameters in the NCE-based neural language models was also missing. In this paper, we showed that NCE can be a successful approach in neural language modelling when the hyperparameters of a neural network are tuned appropriately. We introduced the 'search-then-converge' learning rate schedule for NCE and designed a heuristic that specifies how to use this schedule. The impact of the other important hyperparameters, such as the dropout rate and the weight initialisation range, was also demonstrated. We showed that appropriate tuning of NCE-based neural language models outperforms the state-of-the-art single-model methods on a popular benchmark.
Relational Approach to Knowledge Engineering for POMDP-based Assistance Systems as a Translation of a Psychological Model
Jun 25, 2012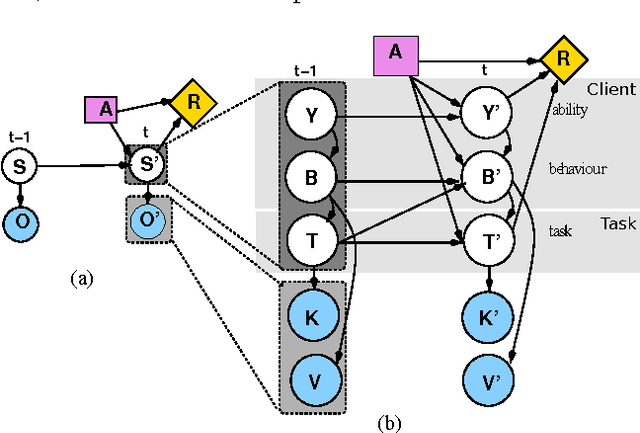
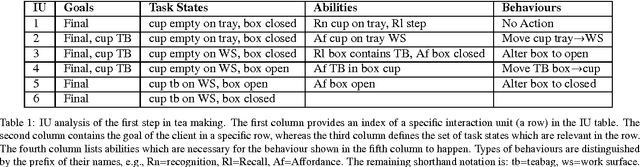
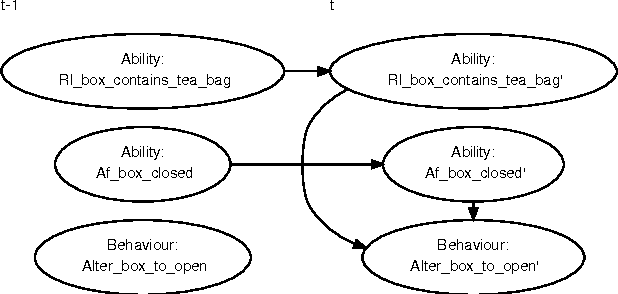
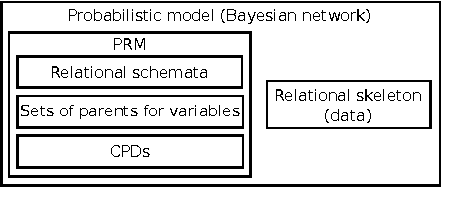
Assistive systems for persons with cognitive disabilities (e.g. dementia) are difficult to build due to the wide range of different approaches people can take to accomplishing the same task, and the significant uncertainties that arise from both the unpredictability of client's behaviours and from noise in sensor readings. Partially observable Markov decision process (POMDP) models have been used successfully as the reasoning engine behind such assistive systems for small multi-step tasks such as hand washing. POMDP models are a powerful, yet flexible framework for modelling assistance that can deal with uncertainty and utility. Unfortunately, POMDPs usually require a very labour intensive, manual procedure for their definition and construction. Our previous work has described a knowledge driven method for automatically generating POMDP activity recognition and context sensitive prompting systems for complex tasks. We call the resulting POMDP a SNAP (SyNdetic Assistance Process). The spreadsheet-like result of the analysis does not correspond to the POMDP model directly and the translation to a formal POMDP representation is required. To date, this translation had to be performed manually by a trained POMDP expert. In this paper, we formalise and automate this translation process using a probabilistic relational model (PRM) encoded in a relational database. We demonstrate the method by eliciting three assistance tasks from non-experts. We validate the resulting POMDP models using case-based simulations to show that they are reasonable for the domains. We also show a complete case study of a designer specifying one database, including an evaluation in a real-life experiment with a human actor.