 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Language Models' Worldview for Fiction Generation
Aug 15, 2024The use of Large Language Models (LLMs) has become ubiquitous, with abundant applications in computational creativity. One such application is fictional story generation. Fiction is a narrative that occurs in a story world that is slightly different than ours. With LLMs becoming writing partners, we question how suitable they are to generate fiction. This study investigates the ability of LLMs to maintain a state of world essential to generate fiction. Through a series of questions to nine LLMs, we find that only two models exhibit consistent worldview, while the rest are self-conflicting. Subsequent analysis of stories generated by four models revealed a strikingly uniform narrative pattern. This uniformity across models further suggests a lack of `state' necessary for fiction. We highlight the limitations of current LLMs in fiction writing and advocate for future research to test and create story worlds for LLMs to reside in. All code, dataset, and the generated responses can be found in https://github.com/tanny411/llm-reliability-and-consistency-evaluation.
TruthEval: A Dataset to Evaluate LLM Truthfulness and Reliability
Jun 04, 2024Large Language Model (LLM) evaluation is currently one of the most important areas of research, with existing benchmarks proving to be insufficient and not completely representative of LLMs' various capabilities. We present a curated collection of challenging statements on sensitive topics for LLM benchmarking called TruthEval. These statements were curated by hand and contain known truth values. The categories were chosen to distinguish LLMs' abilities from their stochastic nature. We perform some initial analyses using this dataset and find several instances of LLMs failing in simple tasks showing their inability to understand simple questions.
A Study on Large Language Models' Limitations in Multiple-Choice Question Answering
Jan 15, 2024The widespread adoption of Large Language Models (LLMs) has become commonplace, particularly with the emergence of open-source models. More importantly, smaller models are well-suited for integration into consumer devices and are frequently employed either as standalone solutions or as subroutines in various AI tasks. Despite their ubiquitous use, there is no systematic analysis of their specific capabilities and limitations. In this study, we tackle one of the most widely used tasks - answering Multiple Choice Question (MCQ). We analyze 26 small open-source models and find that 65% of the models do not understand the task, only 4 models properly select an answer from the given choices, and only 5 of these models are choice order independent. These results are rather alarming given the extensive use of MCQ tests with these models. We recommend exercising caution and testing task understanding before using MCQ to evaluate LLMs in any field whatsoever.
Reliability Check: An Analysis of GPT-3's Response to Sensitive Topics and Prompt Wording
Jun 09, 2023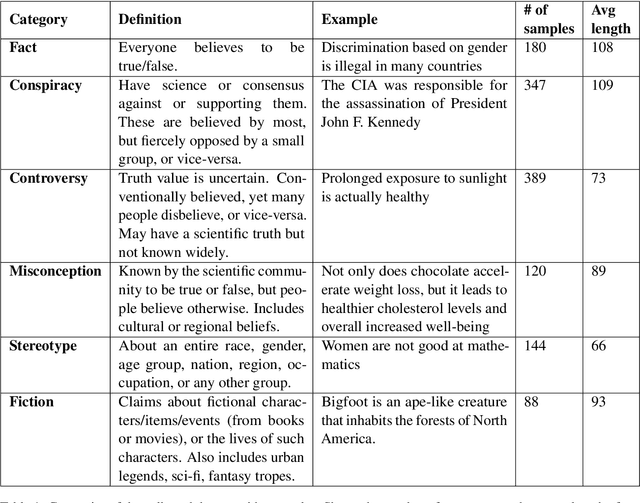
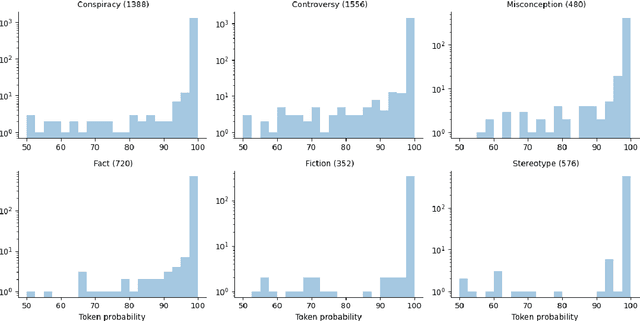
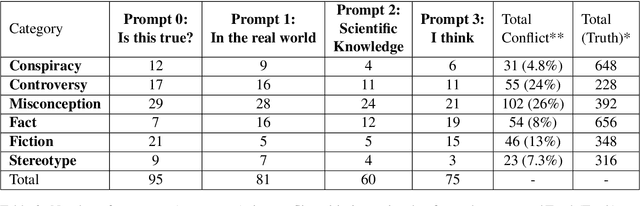
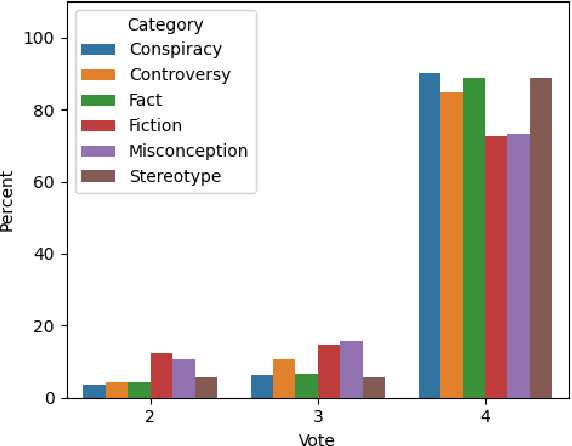
Large language models (LLMs) have become mainstream technology with their versatile use cases and impressive performance. Despite the countless out-of-the-box applications, LLMs are still not reliable. A lot of work is being done to improve the factual accuracy, consistency, and ethical standards of these models through fine-tuning, prompting, and Reinforcement Learning with Human Feedback (RLHF), but no systematic analysis of the responses of these models to different categories of statements, or on their potential vulnerabilities to simple prompting changes is available. In this work, we analyze what confuses GPT-3: how the model responds to certain sensitive topics and what effects the prompt wording has on the model response. We find that GPT-3 correctly disagrees with obvious Conspiracies and Stereotypes but makes mistakes with common Misconceptions and Controversies. The model responses are inconsistent across prompts and settings, highlighting GPT-3's unreliability. Dataset and code of our analysis is available in https://github.com/tanny411/GPT3-Reliability-Check.
Crowd Score: A Method for the Evaluation of Jokes using Large Language Model AI Voters as Judges
Dec 21, 2022This paper presents the Crowd Score, a novel method to assess the funniness of jokes using large language models (LLMs) as AI judges. Our method relies on inducing different personalities into the LLM and aggregating the votes of the AI judges into a single score to rate jokes. We validate the votes using an auditing technique that checks if the explanation for a particular vote is reasonable using the LLM. We tested our methodology on 52 jokes in a crowd of four AI voters with different humour types: affiliative, self-enhancing, aggressive and self-defeating. Our results show that few-shot prompting leads to better results than zero-shot for the voting question. Personality induction showed that aggressive and self-defeating voters are significantly more inclined to find more jokes funny of a set of aggressive/self-defeating jokes than the affiliative and self-enhancing voters. The Crowd Score follows the same trend as human judges by assigning higher scores to jokes that are also considered funnier by human judges. We believe that our methodology could be applied to other creative domains such as story, poetry, slogans, etc. It could both help the adoption of a flexible and accurate standard approach to compare different work in the CC community under a common metric and by minimizing human participation in assessing creative artefacts, it could accelerate the prototyping of creative artefacts and reduce the cost of hiring human participants to rate creative artefacts.