 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Language Models' Worldview for Fiction Generation
Aug 15, 2024The use of Large Language Models (LLMs) has become ubiquitous, with abundant applications in computational creativity. One such application is fictional story generation. Fiction is a narrative that occurs in a story world that is slightly different than ours. With LLMs becoming writing partners, we question how suitable they are to generate fiction. This study investigates the ability of LLMs to maintain a state of world essential to generate fiction. Through a series of questions to nine LLMs, we find that only two models exhibit consistent worldview, while the rest are self-conflicting. Subsequent analysis of stories generated by four models revealed a strikingly uniform narrative pattern. This uniformity across models further suggests a lack of `state' necessary for fiction. We highlight the limitations of current LLMs in fiction writing and advocate for future research to test and create story worlds for LLMs to reside in. All code, dataset, and the generated responses can be found in https://github.com/tanny411/llm-reliability-and-consistency-evaluation.
TruthEval: A Dataset to Evaluate LLM Truthfulness and Reliability
Jun 04, 2024Large Language Model (LLM) evaluation is currently one of the most important areas of research, with existing benchmarks proving to be insufficient and not completely representative of LLMs' various capabilities. We present a curated collection of challenging statements on sensitive topics for LLM benchmarking called TruthEval. These statements were curated by hand and contain known truth values. The categories were chosen to distinguish LLMs' abilities from their stochastic nature. We perform some initial analyses using this dataset and find several instances of LLMs failing in simple tasks showing their inability to understand simple questions.
Authorship Attribution in Bangla Literature (AABL) via Transfer Learning using ULMFiT
Mar 08, 2024Authorship Attribution is the task of creating an appropriate characterization of text that captures the authors' writing style to identify the original author of a given piece of text. With increased anonymity on the internet, this task has become increasingly crucial in various security and plagiarism detection fields. Despite significant advancements in other languages such as English, Spanish, and Chinese, Bangla lacks comprehensive research in this field due to its complex linguistic feature and sentence structure. Moreover, existing systems are not scalable when the number of author increases, and the performance drops for small number of samples per author. In this paper, we propose the use of Average-Stochastic Gradient Descent Weight-Dropped Long Short-Term Memory (AWD-LSTM) architecture and an effective transfer learning approach that addresses the problem of complex linguistic features extraction and scalability for authorship attribution in Bangla Literature (AABL). We analyze the effect of different tokenization, such as word, sub-word, and character level tokenization, and demonstrate the effectiveness of these tokenizations in the proposed model. Moreover, we introduce the publicly available Bangla Authorship Attribution Dataset of 16 authors (BAAD16) containing 17,966 sample texts and 13.4+ million words to solve the standard dataset scarcity problem and release six variations of pre-trained language models for use in any Bangla NLP downstream task. For evaluation, we used our developed BAAD16 dataset as well as other publicly available datasets. Empirically, our proposed model outperformed state-of-the-art models and achieved 99.8% accuracy in the BAAD16 dataset. Furthermore, we showed that the proposed system scales much better even with an increasing number of authors, and performance remains steady despite few training samples.
A Study on Large Language Models' Limitations in Multiple-Choice Question Answering
Jan 15, 2024The widespread adoption of Large Language Models (LLMs) has become commonplace, particularly with the emergence of open-source models. More importantly, smaller models are well-suited for integration into consumer devices and are frequently employed either as standalone solutions or as subroutines in various AI tasks. Despite their ubiquitous use, there is no systematic analysis of their specific capabilities and limitations. In this study, we tackle one of the most widely used tasks - answering Multiple Choice Question (MCQ). We analyze 26 small open-source models and find that 65% of the models do not understand the task, only 4 models properly select an answer from the given choices, and only 5 of these models are choice order independent. These results are rather alarming given the extensive use of MCQ tests with these models. We recommend exercising caution and testing task understanding before using MCQ to evaluate LLMs in any field whatsoever.
Reliability Check: An Analysis of GPT-3's Response to Sensitive Topics and Prompt Wording
Jun 09, 2023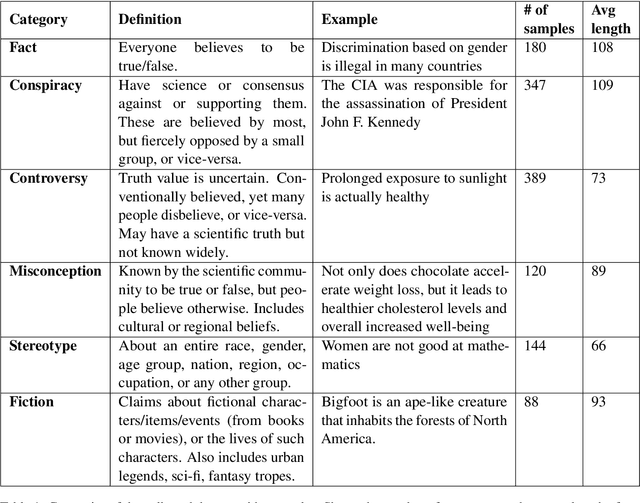
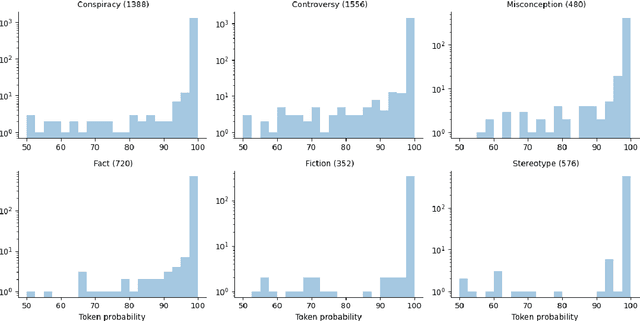
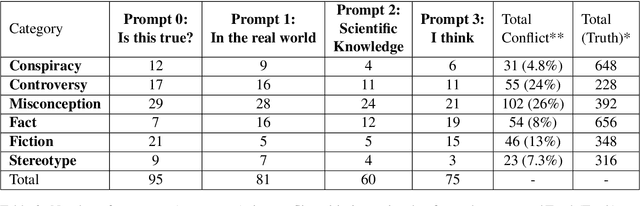
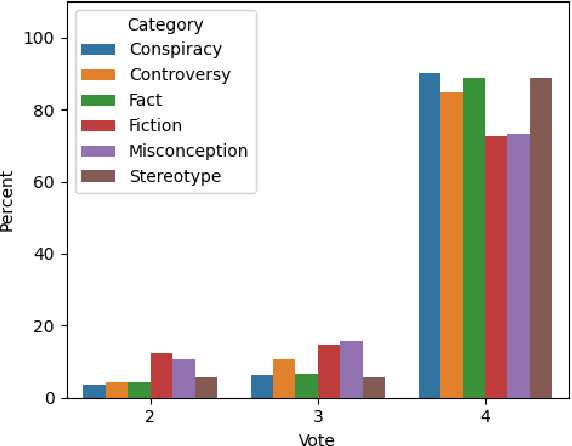
Large language models (LLMs) have become mainstream technology with their versatile use cases and impressive performance. Despite the countless out-of-the-box applications, LLMs are still not reliable. A lot of work is being done to improve the factual accuracy, consistency, and ethical standards of these models through fine-tuning, prompting, and Reinforcement Learning with Human Feedback (RLHF), but no systematic analysis of the responses of these models to different categories of statements, or on their potential vulnerabilities to simple prompting changes is available. In this work, we analyze what confuses GPT-3: how the model responds to certain sensitive topics and what effects the prompt wording has on the model response. We find that GPT-3 correctly disagrees with obvious Conspiracies and Stereotypes but makes mistakes with common Misconceptions and Controversies. The model responses are inconsistent across prompts and settings, highlighting GPT-3's unreliability. Dataset and code of our analysis is available in https://github.com/tanny411/GPT3-Reliability-Check.
Bits of Grass: Does GPT already know how to write like Whitman?
May 10, 2023This study examines the ability of GPT-3.5, GPT-3.5-turbo (ChatGPT) and GPT-4 models to generate poems in the style of specific authors using zero-shot and many-shot prompts (which use the maximum context length of 8192 tokens). We assess the performance of models that are not fine-tuned for generating poetry in the style of specific authors, via automated evaluation. Our findings indicate that without fine-tuning, even when provided with the maximum number of 17 poem examples (8192 tokens) in the prompt, these models do not generate poetry in the desired style.
Authorship Attribution in Bangla literature using Character-level CNN
Jan 11, 2020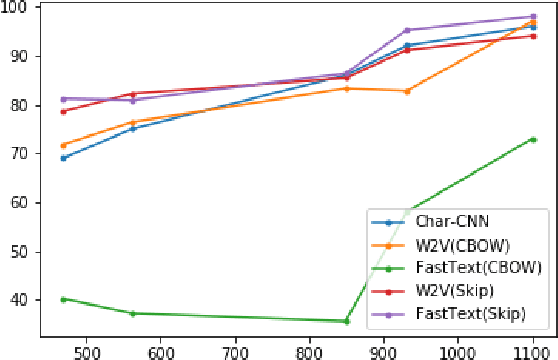
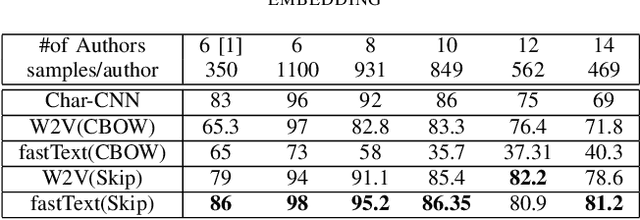
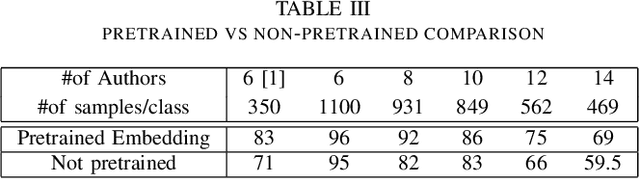
Characters are the smallest unit of text that can extract stylometric signals to determine the author of a text. In this paper, we investigate the effectiveness of character-level signals in Authorship Attribution of Bangla Literature and show that the results are promising but improvable. The time and memory efficiency of the proposed model is much higher than the word level counterparts but accuracy is 2-5% less than the best performing word-level models. Comparison of various word-based models is performed and shown that the proposed model performs increasingly better with larger datasets. We also analyze the effect of pre-training character embedding of diverse Bangla character set in authorship attribution. It is seen that the performance is improved by up to 10% on pre-training. We used 2 datasets from 6 to 14 authors, balancing them before training and compare the results.
A Continuous Space Neural Language Model for Bengali Language
Jan 11, 2020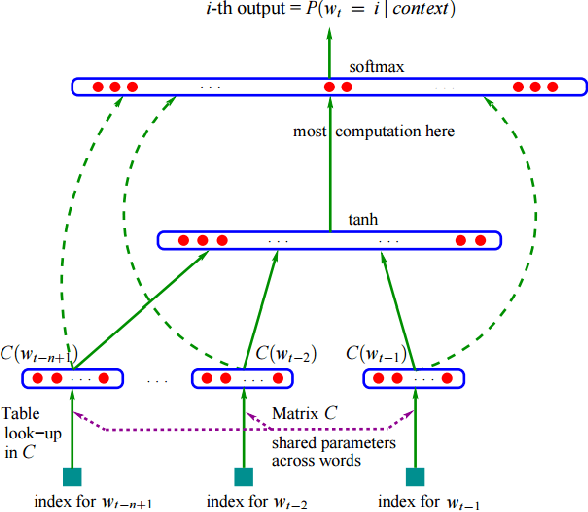
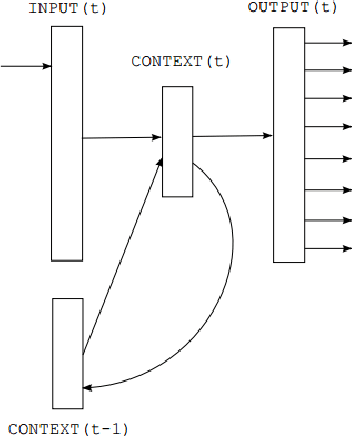
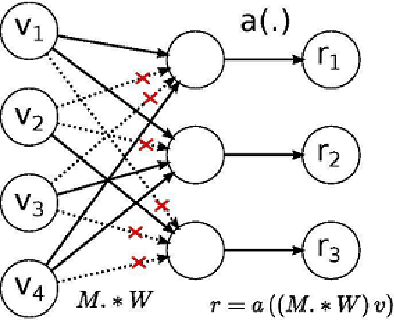
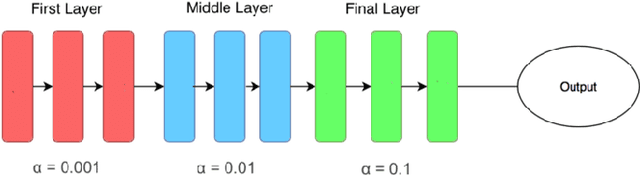
Language models are generally employed to estimate the probability distribution of various linguistic units, making them one of the fundamental parts of natural language processing. Applications of language models include a wide spectrum of tasks such as text summarization, translation and classification. For a low resource language like Bengali, the research in this area so far can be considered to be narrow at the very least, with some traditional count based models being proposed. This paper attempts to address the issue and proposes a continuous-space neural language model, or more specifically an ASGD weight dropped LSTM language model, along with techniques to efficiently train it for Bengali Language. The performance analysis with some currently existing count based models illustrated in this paper also shows that the proposed architecture outperforms its counterparts by achieving an inference perplexity as low as 51.2 on the held out data set for Bengali.
A Subword Level Language Model for Bangla Language
Nov 15, 2019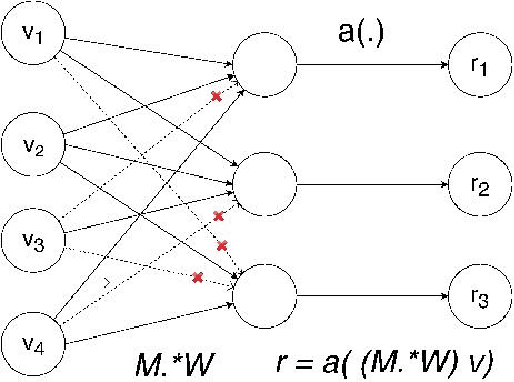
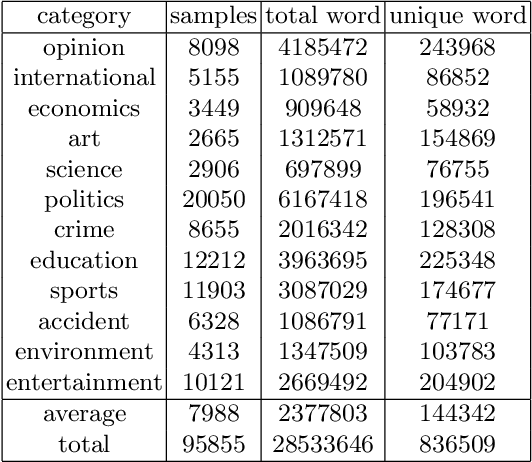
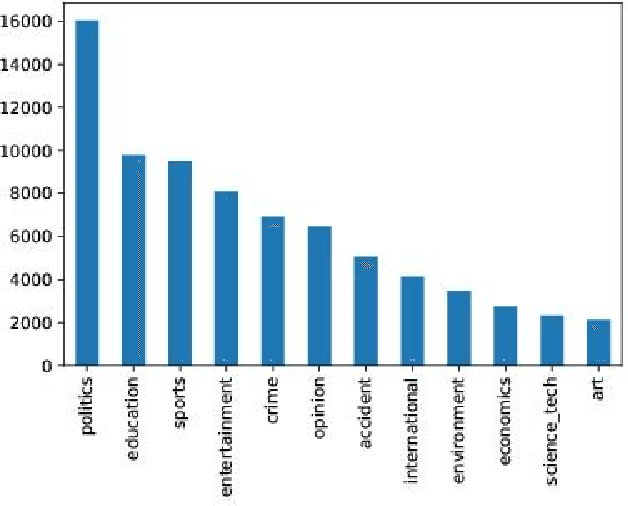
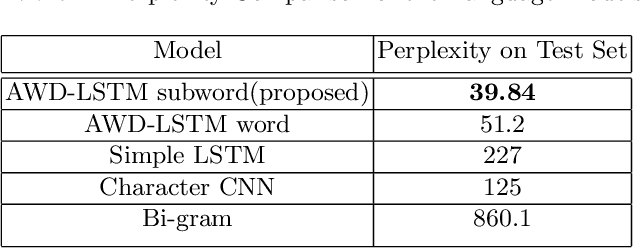
Language models are at the core of natural language processing. The ability to represent natural language gives rise to its applications in numerous NLP tasks including text classification, summarization, and translation. Research in this area is very limited in Bangla due to the scarcity of resources, except for some count-based models and very recent neural language models being proposed, which are all based on words and limited in practical tasks due to their high perplexity. This paper attempts to approach this issue of perplexity and proposes a subword level neural language model with the AWD-LSTM architecture and various other techniques suitable for training in Bangla language. The model is trained on a corpus of Bangla newspaper articles of an appreciable size consisting of more than 28.5 million word tokens. The performance comparison with various other models depicts the significant reduction in perplexity the proposed model provides, reaching as low as 39.84, in just 20 epochs.