 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthorship Attribution in Bangla Literature (AABL) via Transfer Learning using ULMFiT
Mar 08, 2024Authorship Attribution is the task of creating an appropriate characterization of text that captures the authors' writing style to identify the original author of a given piece of text. With increased anonymity on the internet, this task has become increasingly crucial in various security and plagiarism detection fields. Despite significant advancements in other languages such as English, Spanish, and Chinese, Bangla lacks comprehensive research in this field due to its complex linguistic feature and sentence structure. Moreover, existing systems are not scalable when the number of author increases, and the performance drops for small number of samples per author. In this paper, we propose the use of Average-Stochastic Gradient Descent Weight-Dropped Long Short-Term Memory (AWD-LSTM) architecture and an effective transfer learning approach that addresses the problem of complex linguistic features extraction and scalability for authorship attribution in Bangla Literature (AABL). We analyze the effect of different tokenization, such as word, sub-word, and character level tokenization, and demonstrate the effectiveness of these tokenizations in the proposed model. Moreover, we introduce the publicly available Bangla Authorship Attribution Dataset of 16 authors (BAAD16) containing 17,966 sample texts and 13.4+ million words to solve the standard dataset scarcity problem and release six variations of pre-trained language models for use in any Bangla NLP downstream task. For evaluation, we used our developed BAAD16 dataset as well as other publicly available datasets. Empirically, our proposed model outperformed state-of-the-art models and achieved 99.8% accuracy in the BAAD16 dataset. Furthermore, we showed that the proposed system scales much better even with an increasing number of authors, and performance remains steady despite few training samples.
A Continuous Space Neural Language Model for Bengali Language
Jan 11, 2020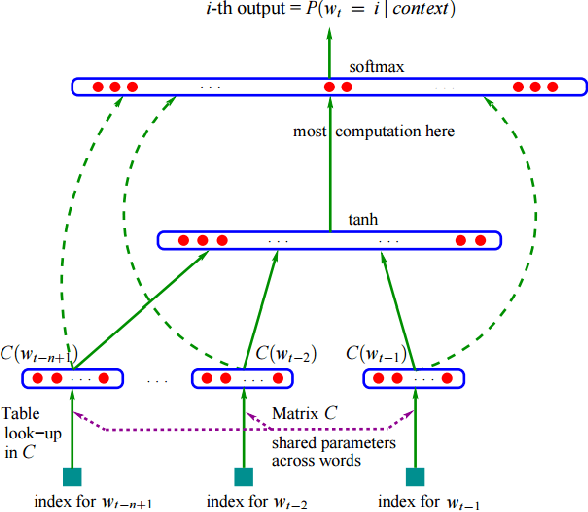
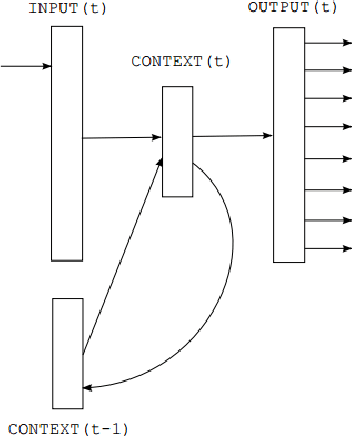
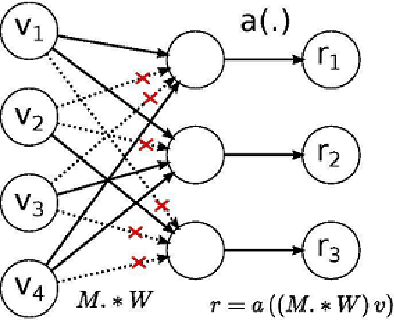
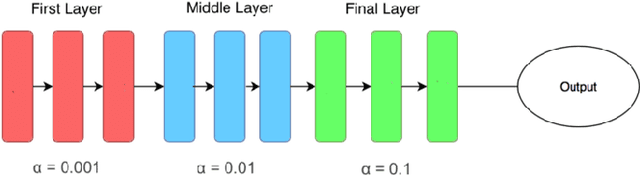
Language models are generally employed to estimate the probability distribution of various linguistic units, making them one of the fundamental parts of natural language processing. Applications of language models include a wide spectrum of tasks such as text summarization, translation and classification. For a low resource language like Bengali, the research in this area so far can be considered to be narrow at the very least, with some traditional count based models being proposed. This paper attempts to address the issue and proposes a continuous-space neural language model, or more specifically an ASGD weight dropped LSTM language model, along with techniques to efficiently train it for Bengali Language. The performance analysis with some currently existing count based models illustrated in this paper also shows that the proposed architecture outperforms its counterparts by achieving an inference perplexity as low as 51.2 on the held out data set for Bengali.
A Subword Level Language Model for Bangla Language
Nov 15, 2019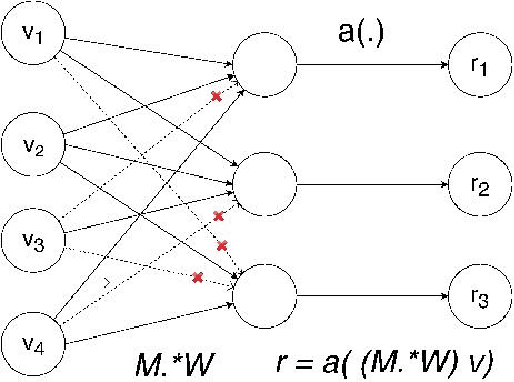
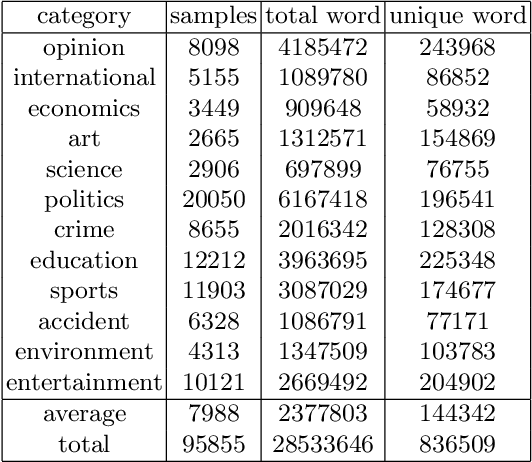
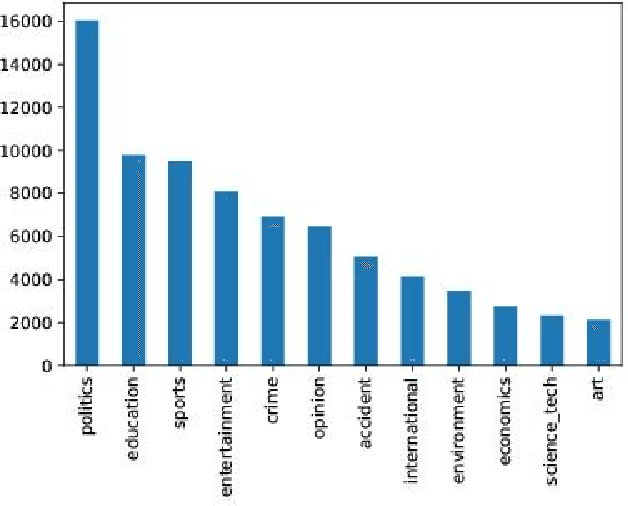
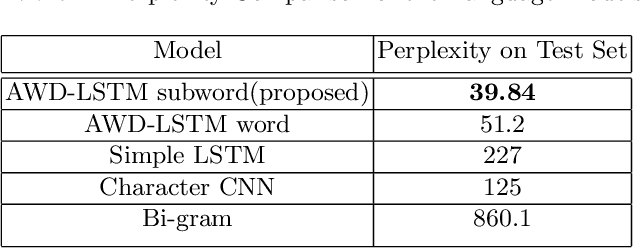
Language models are at the core of natural language processing. The ability to represent natural language gives rise to its applications in numerous NLP tasks including text classification, summarization, and translation. Research in this area is very limited in Bangla due to the scarcity of resources, except for some count-based models and very recent neural language models being proposed, which are all based on words and limited in practical tasks due to their high perplexity. This paper attempts to approach this issue of perplexity and proposes a subword level neural language model with the AWD-LSTM architecture and various other techniques suitable for training in Bangla language. The model is trained on a corpus of Bangla newspaper articles of an appreciable size consisting of more than 28.5 million word tokens. The performance comparison with various other models depicts the significant reduction in perplexity the proposed model provides, reaching as low as 39.84, in just 20 epochs.
Sentiment Analysis of Comments on Rohingya Movement with Support Vector Machine
Mar 22, 2018The Rohingya Movement and Crisis caused a huge uproar in the political and economic state of Bangladesh. Refugee movement is a recurring event and a large amount of data in the form of opinions remains on social media such as Facebook, with very little analysis done on them.To analyse the comments based on all Rohingya related posts, we had to create and modify a classifier based on the Support Vector Machine algorithm. The code is implemented in python and uses scikit-learn library. A dataset on Rohingya analysis is not currently available so we had to use our own data set of 2500 positive and 2500 negative comments. We specifically used a support vector machine with linear kernel. A previous experiment was performed by us on the same dataset using the naive bayes algorithm, but that did not yield impressive results.