 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Subword Level Language Model for Bangla Language
Paper and Code
Nov 15, 2019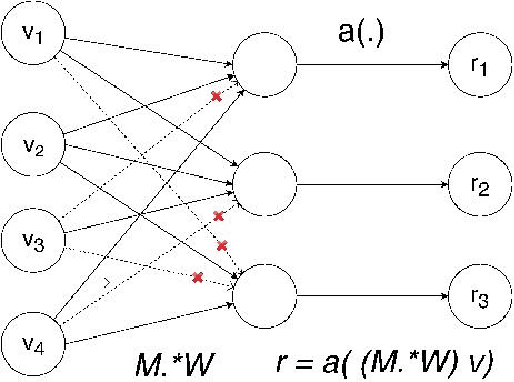
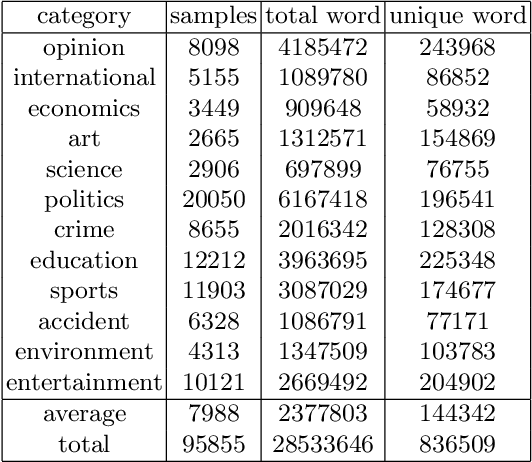
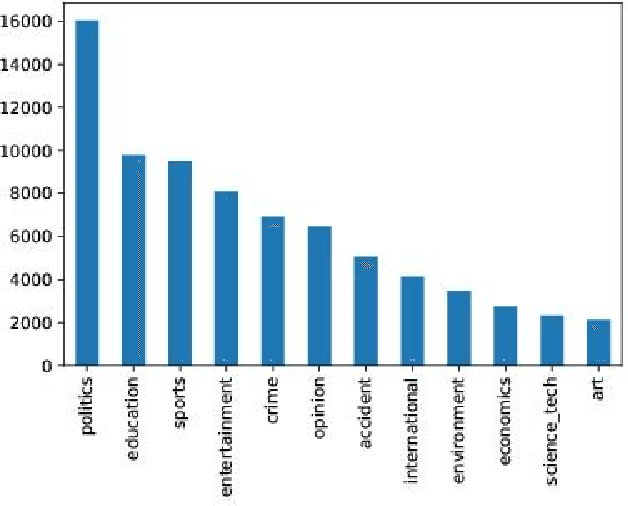
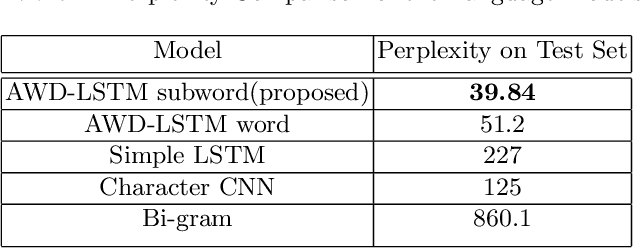
Language models are at the core of natural language processing. The ability to represent natural language gives rise to its applications in numerous NLP tasks including text classification, summarization, and translation. Research in this area is very limited in Bangla due to the scarcity of resources, except for some count-based models and very recent neural language models being proposed, which are all based on words and limited in practical tasks due to their high perplexity. This paper attempts to approach this issue of perplexity and proposes a subword level neural language model with the AWD-LSTM architecture and various other techniques suitable for training in Bangla language. The model is trained on a corpus of Bangla newspaper articles of an appreciable size consisting of more than 28.5 million word tokens. The performance comparison with various other models depicts the significant reduction in perplexity the proposed model provides, reaching as low as 39.84, in just 20 epochs.