 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Visual Question Answering Datasets and Algorithms
Nov 17, 2024



Visual question answering (VQA) refers to the problem where, given an image and a natural language question about the image, a correct natural language answer has to be generated. A VQA model has to demonstrate both the visual understanding of the image and the semantic understanding of the question, demonstrating reasoning capability. Since the inception of this field, a plethora of VQA datasets and models have been published. In this article, we meticulously analyze the current state of VQA datasets and models, while cleanly dividing them into distinct categories and then summarizing the methodologies and characteristics of each category. We divide VQA datasets into four categories: (1) available datasets that contain a rich collection of authentic images, (2) synthetic datasets that contain only synthetic images produced through artificial means, (3) diagnostic datasets that are specially designed to test model performance in a particular area, e.g., understanding the scene text, and (4) KB (Knowledge-Based) datasets that are designed to measure a model's ability to utilize outside knowledge. Concurrently, we explore six main paradigms of VQA models: fusion, where we discuss different methods of fusing information between visual and textual modalities; attention, the technique of using information from one modality to filter information from another; external knowledge base, where we discuss different models utilizing outside information; composition or reasoning, where we analyze techniques to answer advanced questions that require complex reasoning steps; explanation, which is the process of generating visual and textual descriptions to verify sound reasoning; and graph models, which encode and manipulate relationships through nodes in a graph. We also discuss some miscellaneous topics, such as scene text understanding, counting, and bias reduction.
Deep Learning Approach Combining Lightweight CNN Architecture with Transfer Learning: An Automatic Approach for the Detection and Recognition of Bangladeshi Banknotes
Dec 10, 2020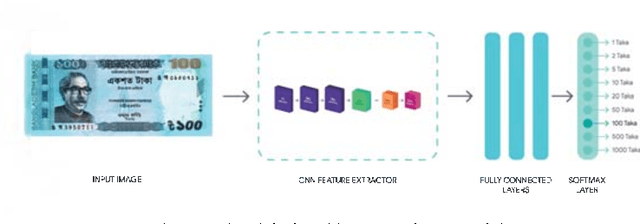
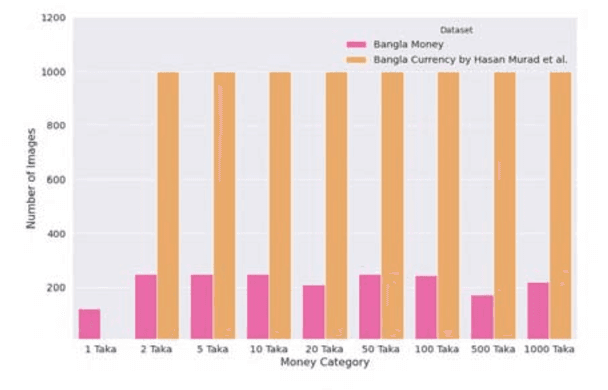
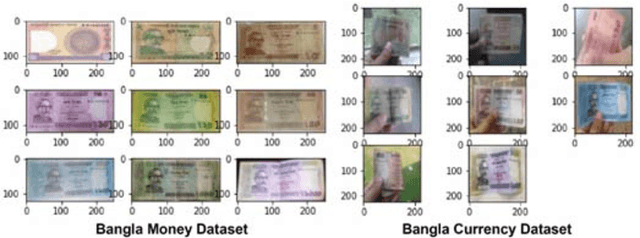
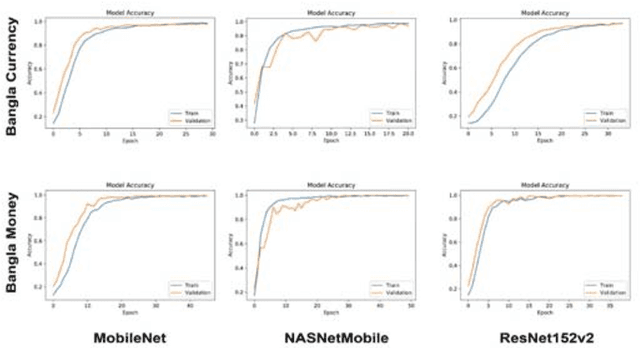
Automatic detection and recognition of banknotes can be a very useful technology for people with visual difficulties and also for the banks itself by providing efficient management for handling different paper currencies. Lightweight models can easily be integrated into any handy IoT based gadgets/devices. This article presents our experiments on several state-of-the-art deep learning methods based on Lightweight Convolutional Neural Network architectures combining with transfer learning. ResNet152v2, MobileNet, and NASNetMobile were used as the base models with two different datasets containing Bangladeshi banknote images. The Bangla Currency dataset has 8000 Bangladeshi banknote images where the Bangla Money dataset consists of 1970 images. The performances of the models were measured using both the datasets and the combination of the two datasets. In order to achieve maximum efficiency, we used various augmentations, hyperparameter tuning, and optimizations techniques. We have achieved maximum test accuracy of 98.88\% on 8000 images dataset using MobileNet, 100\% on the 1970 images dataset using NASNetMobile, and 97.77\% on the combined dataset (9970 images) using MobileNet.
* 4 pages
Restyling Images with the Bangladeshi Paintings Using Neural Style Transfer: A Comprehensive Experiment, Evaluation, and Human Perspective
Dec 10, 2020

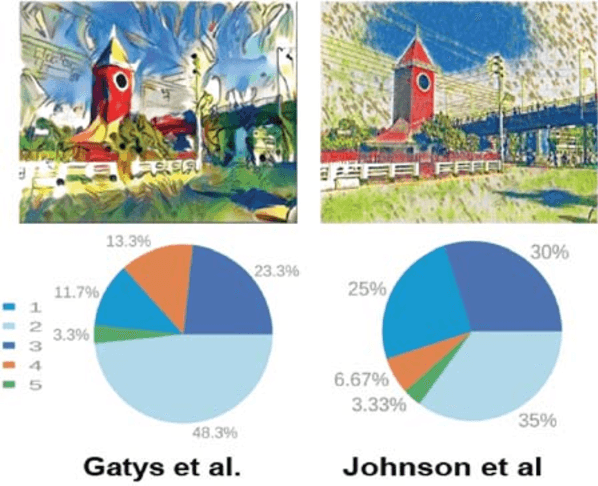
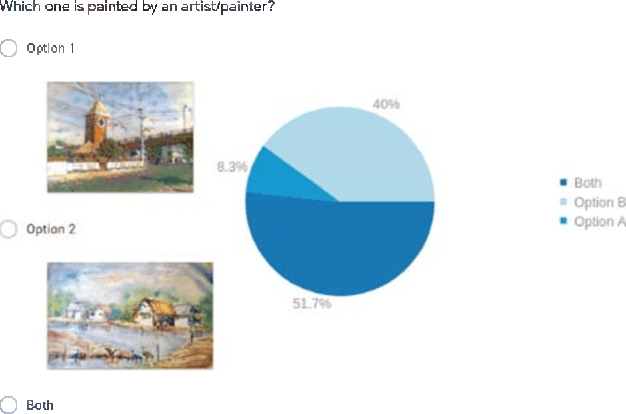
In today's world, Neural Style Transfer (NST) has become a trendsetting term. NST combines two pictures, a content picture and a reference image in style (such as the work of a renowned painter) in a way that makes the output image look like an image of the material, but rendered with the form of a reference picture. However, there is no study using the artwork or painting of Bangladeshi painters. Bangladeshi painting has a long history of more than two thousand years and is still being practiced by Bangladeshi painters. This study generates NST stylized image on Bangladeshi paintings and analyzes the human point of view regarding the aesthetic preference of NST on Bangladeshi paintings. To assure our study's acceptance, we performed qualitative human evaluations on generated stylized images by 60 individual humans of different age and gender groups. We have explained how NST works for Bangladeshi paintings and assess NST algorithms, both qualitatively \& quantitatively. Our study acts as a pre-requisite for the impact of NST stylized image using Bangladeshi paintings on mobile UI/GUI and material translation from the human perspective. We hope that this study will encourage new collaborations to create more NST related studies and expand the use of Bangladeshi artworks.
* 6 pages
Bengali Abstractive News Summarization(BANS): A Neural Attention Approach
Dec 03, 2020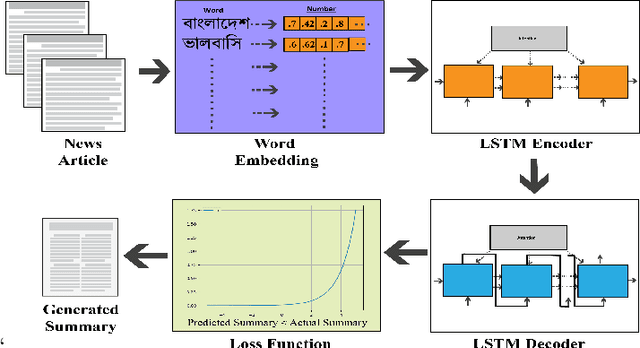


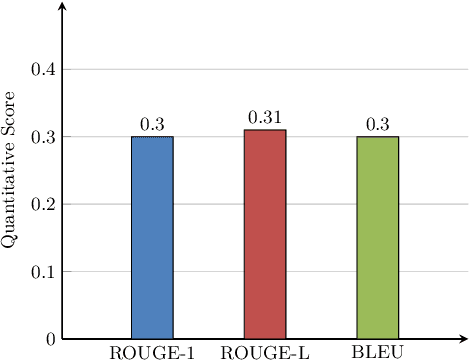
Abstractive summarization is the process of generating novel sentences based on the information extracted from the original text document while retaining the context. Due to abstractive summarization's underlying complexities, most of the past research work has been done on the extractive summarization approach. Nevertheless, with the triumph of the sequence-to-sequence (seq2seq) model, abstractive summarization becomes more viable. Although a significant number of notable research has been done in the English language based on abstractive summarization, only a couple of works have been done on Bengali abstractive news summarization (BANS). In this article, we presented a seq2seq based Long Short-Term Memory (LSTM) network model with attention at encoder-decoder. Our proposed system deploys a local attention-based model that produces a long sequence of words with lucid and human-like generated sentences with noteworthy information of the original document. We also prepared a dataset of more than 19k articles and corresponding human-written summaries collected from bangla.bdnews24.com1 which is till now the most extensive dataset for Bengali news document summarization and publicly published in Kaggle2. We evaluated our model qualitatively and quantitatively and compared it with other published results. It showed significant improvement in terms of human evaluation scores with state-of-the-art approaches for BANS.
Authorship Attribution in Bangla literature using Character-level CNN
Jan 11, 2020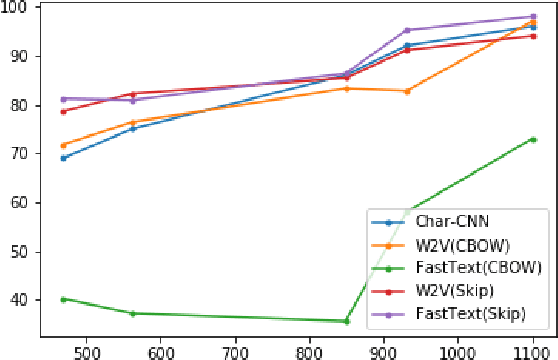
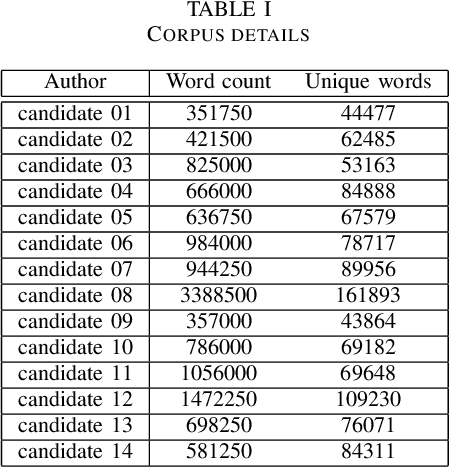
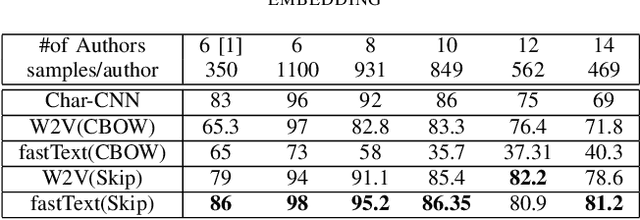
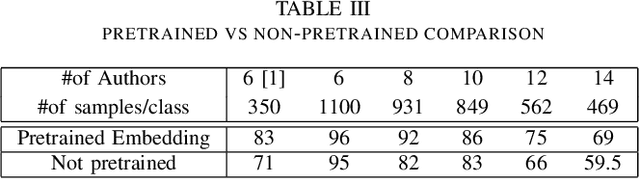
Characters are the smallest unit of text that can extract stylometric signals to determine the author of a text. In this paper, we investigate the effectiveness of character-level signals in Authorship Attribution of Bangla Literature and show that the results are promising but improvable. The time and memory efficiency of the proposed model is much higher than the word level counterparts but accuracy is 2-5% less than the best performing word-level models. Comparison of various word-based models is performed and shown that the proposed model performs increasingly better with larger datasets. We also analyze the effect of pre-training character embedding of diverse Bangla character set in authorship attribution. It is seen that the performance is improved by up to 10% on pre-training. We used 2 datasets from 6 to 14 authors, balancing them before training and compare the results.