 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointer over Attention: An Improved Bangla Text Summarization Approach Using Hybrid Pointer Generator Network
Nov 19, 2021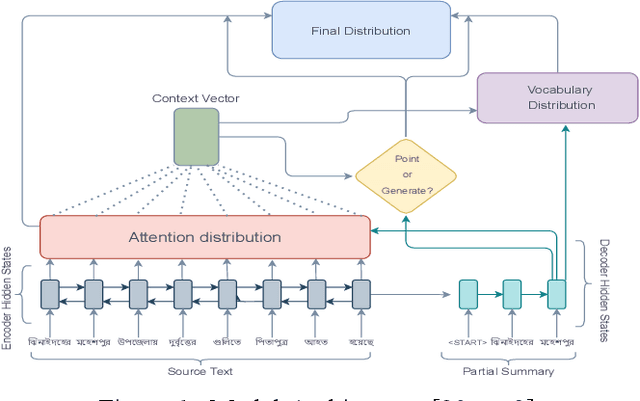
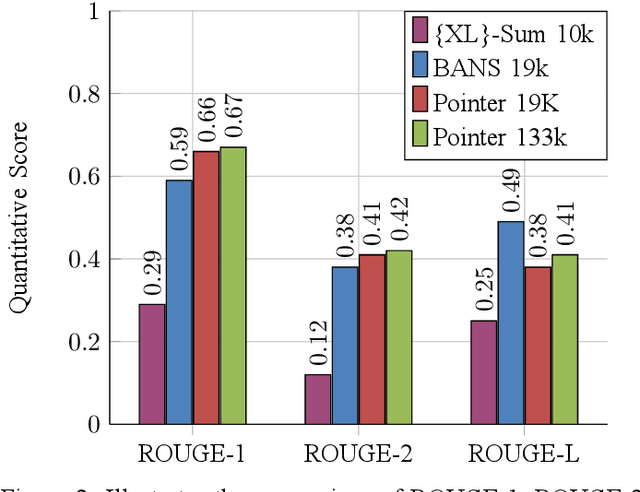
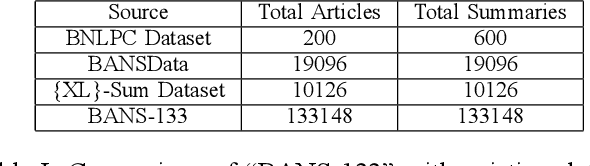
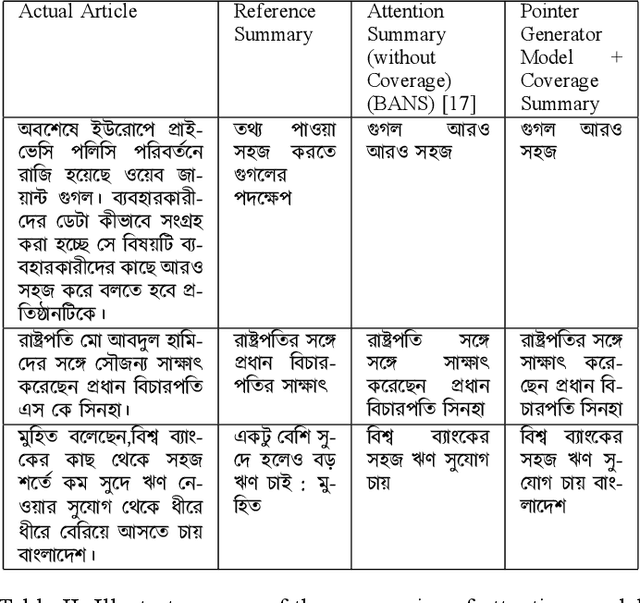
Despite the success of the neural sequence-to-sequence model for abstractive text summarization, it has a few shortcomings, such as repeating inaccurate factual details and tending to repeat themselves. We propose a hybrid pointer generator network to solve the shortcomings of reproducing factual details inadequately and phrase repetition. We augment the attention-based sequence-to-sequence using a hybrid pointer generator network that can generate Out-of-Vocabulary words and enhance accuracy in reproducing authentic details and a coverage mechanism that discourages repetition. It produces a reasonable-sized output text that preserves the conceptual integrity and factual information of the input article. For evaluation, we primarily employed "BANSData" - a highly adopted publicly available Bengali dataset. Additionally, we prepared a large-scale dataset called "BANS-133" which consists of 133k Bangla news articles associated with human-generated summaries. Experimenting with the proposed model, we achieved ROUGE-1 and ROUGE-2 scores of 0.66, 0.41 for the "BANSData" dataset and 0.67, 0.42 for the BANS-133k" dataset, respectively. We demonstrated that the proposed system surpasses previous state-of-the-art Bengali abstractive summarization techniques and its stability on a larger dataset. "BANS-133" datasets and code-base will be publicly available for research.
Bengali Abstractive News Summarization(BANS): A Neural Attention Approach
Dec 03, 2020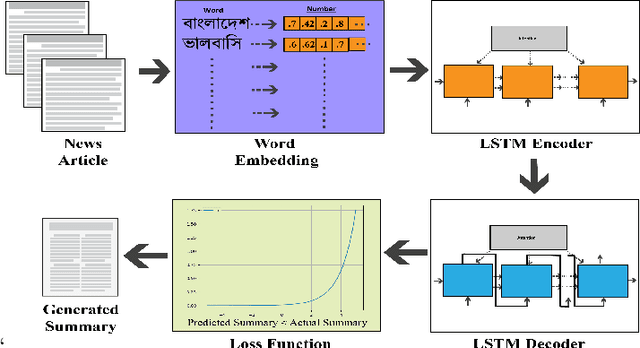


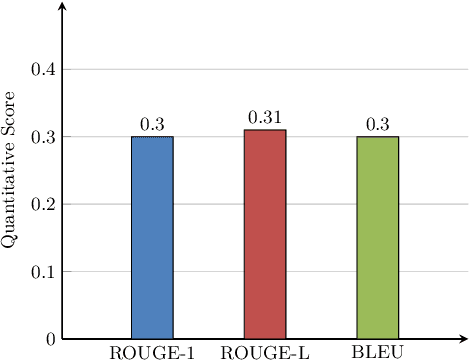
Abstractive summarization is the process of generating novel sentences based on the information extracted from the original text document while retaining the context. Due to abstractive summarization's underlying complexities, most of the past research work has been done on the extractive summarization approach. Nevertheless, with the triumph of the sequence-to-sequence (seq2seq) model, abstractive summarization becomes more viable. Although a significant number of notable research has been done in the English language based on abstractive summarization, only a couple of works have been done on Bengali abstractive news summarization (BANS). In this article, we presented a seq2seq based Long Short-Term Memory (LSTM) network model with attention at encoder-decoder. Our proposed system deploys a local attention-based model that produces a long sequence of words with lucid and human-like generated sentences with noteworthy information of the original document. We also prepared a dataset of more than 19k articles and corresponding human-written summaries collected from bangla.bdnews24.com1 which is till now the most extensive dataset for Bengali news document summarization and publicly published in Kaggle2. We evaluated our model qualitatively and quantitatively and compared it with other published results. It showed significant improvement in terms of human evaluation scores with state-of-the-art approaches for BANS.