 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Efficacy of Semantics-Preserving Transformations in Self-Supervised Learning for Medical Ultrasound
Apr 10, 2025Data augmentation is a central component of joint embedding self-supervised learning (SSL). Approaches that work for natural images may not always be effective in medical imaging tasks. This study systematically investigated the impact of data augmentation and preprocessing strategies in SSL for lung ultrasound. Three data augmentation pipelines were assessed: (1) a baseline pipeline commonly used across imaging domains, (2) a novel semantic-preserving pipeline designed for ultrasound, and (3) a distilled set of the most effective transformations from both pipelines. Pretrained models were evaluated on multiple classification tasks: B-line detection, pleural effusion detection, and COVID-19 classification. Experiments revealed that semantics-preserving data augmentation resulted in the greatest performance for COVID-19 classification - a diagnostic task requiring global image context. Cropping-based methods yielded the greatest performance on the B-line and pleural effusion object classification tasks, which require strong local pattern recognition. Lastly, semantics-preserving ultrasound image preprocessing resulted in increased downstream performance for multiple tasks. Guidance regarding data augmentation and preprocessing strategies was synthesized for practitioners working with SSL in ultrasound.
Intra-video Positive Pairs in Self-Supervised Learning for Ultrasound
Mar 12, 2024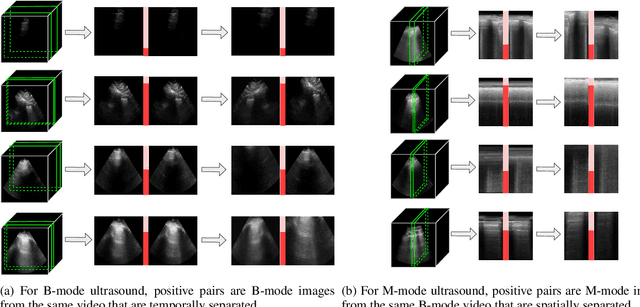
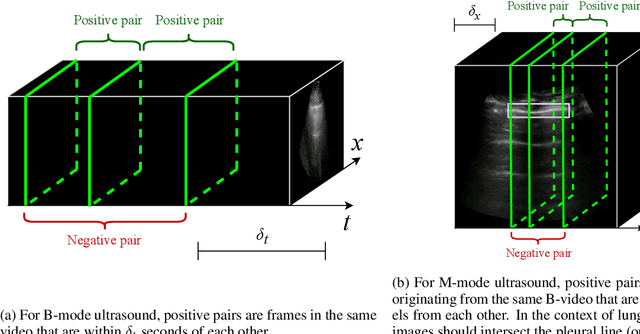
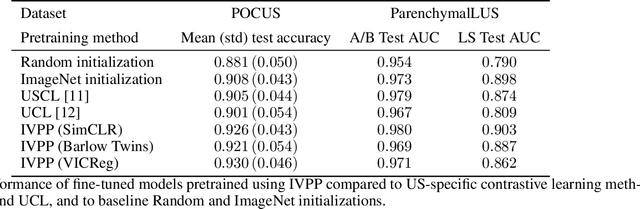
Self-supervised learning (SSL) is one strategy for addressing the paucity of labelled data in medical imaging by learning representations from unlabelled images. Contrastive and non-contrastive SSL methods produce learned representations that are similar for pairs of related images. Such pairs are commonly constructed by randomly distorting the same image twice. The videographic nature of ultrasound offers flexibility for defining the similarity relationship between pairs of images. In this study, we investigated the effect of utilizing proximal, distinct images from the same B-mode ultrasound video as pairs for SSL. Additionally, we introduced a sample weighting scheme that increases the weight of closer image pairs and demonstrated how it can be integrated into SSL objectives. Named Intra-Video Positive Pairs (IVPP), the method surpassed previous ultrasound-specific contrastive learning methods' average test accuracy on COVID-19 classification with the POCUS dataset by $\ge 1.3\%$. Detailed investigations of IVPP's hyperparameters revealed that some combinations of IVPP hyperparameters can lead to improved or worsened performance, depending on the downstream task. Guidelines for practitioners were synthesized based on the results, such as the merit of IVPP with task-specific hyperparameters, and the improved performance of contrastive methods for ultrasound compared to non-contrastive counterparts.
Self-Supervised Pretraining Improves Performance and Inference Efficiency in Multiple Lung Ultrasound Interpretation Tasks
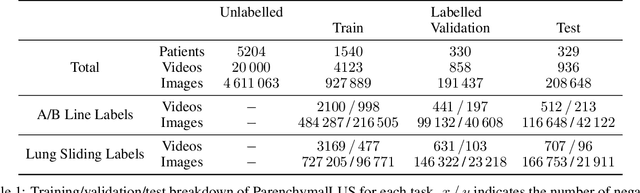
Sep 05, 2023In this study, we investigated whether self-supervised pretraining could produce a neural network feature extractor applicable to multiple classification tasks in B-mode lung ultrasound analysis. When fine-tuning on three lung ultrasound tasks, pretrained models resulted in an improvement of the average across-task area under the receiver operating curve (AUC) by 0.032 and 0.061 on local and external test sets respectively. Compact nonlinear classifiers trained on features outputted by a single pretrained model did not improve performance across all tasks; however, they did reduce inference time by 49% compared to serial execution of separate fine-tuned models. When training using 1% of the available labels, pretrained models consistently outperformed fully supervised models, with a maximum observed test AUC increase of 0.396 for the task of view classification. Overall, the results indicate that self-supervised pretraining is useful for producing initial weights for lung ultrasound classifiers.
A Survey of the Impact of Self-Supervised Pretraining for Diagnostic Tasks with Radiological Images
Sep 05, 2023



Self-supervised pretraining has been observed to be effective at improving feature representations for transfer learning, leveraging large amounts of unlabelled data. This review summarizes recent research into its usage in X-ray, computed tomography, magnetic resonance, and ultrasound imaging, concentrating on studies that compare self-supervised pretraining to fully supervised learning for diagnostic tasks such as classification and segmentation. The most pertinent finding is that self-supervised pretraining generally improves downstream task performance compared to full supervision, most prominently when unlabelled examples greatly outnumber labelled examples. Based on the aggregate evidence, recommendations are provided for practitioners considering using self-supervised learning. Motivated by limitations identified in current research, directions and practices for future study are suggested, such as integrating clinical knowledge with theoretically justified self-supervised learning methods, evaluating on public datasets, growing the modest body of evidence for ultrasound, and characterizing the impact of self-supervised pretraining on generalization.
Exploring the Utility of Self-Supervised Pretraining Strategies for the Detection of Absent Lung Sliding in M-Mode Lung Ultrasound
Apr 05, 2023



Self-supervised pretraining has been observed to improve performance in supervised learning tasks in medical imaging. This study investigates the utility of self-supervised pretraining prior to conducting supervised fine-tuning for the downstream task of lung sliding classification in M-mode lung ultrasound images. We propose a novel pairwise relationship that couples M-mode images constructed from the same B-mode image and investigate the utility of data augmentation procedure specific to M-mode lung ultrasound. The results indicate that self-supervised pretraining yields better performance than full supervision, most notably for feature extractors not initialized with ImageNet-pretrained weights. Moreover, we observe that including a vast volume of unlabelled data results in improved performance on external validation datasets, underscoring the value of self-supervision for improving generalizability in automatic ultrasound interpretation. To the authors' best knowledge, this study is the first to characterize the influence of self-supervised pretraining for M-mode ultrasound.
A Novel Approach to Fairness in Automated Decision-Making using Affective Normalization
May 02, 2022
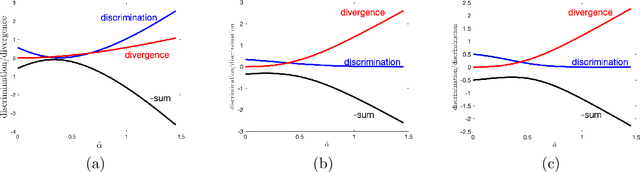
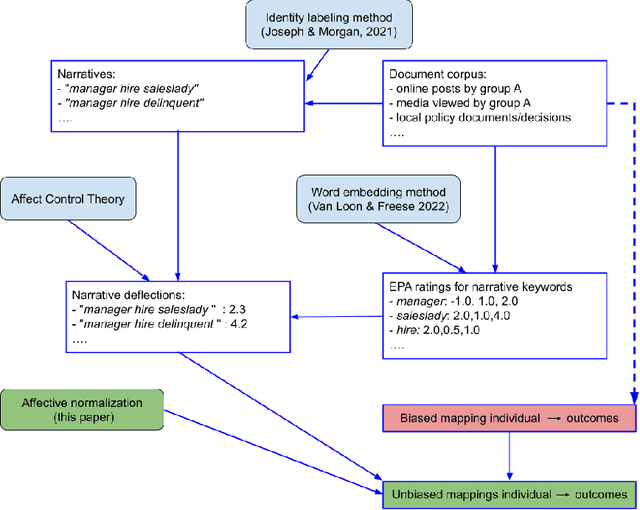
Any decision, such as one about who to hire, involves two components. First, a rational component, i.e., they have a good education, they speak clearly. Second, an affective component, based on observables such as visual features of race and gender, and possibly biased by stereotypes. Here we propose a method for measuring the affective, socially biased, component, thus enabling its removal. That is, given a decision-making process, these affective measurements remove the affective bias in the decision, rendering it fair across a set of categories defined by the method itself. We thus propose that this may solve three key problems in intersectional fairness: (1) the definition of categories over which fairness is a consideration; (2) an infinite regress into smaller and smaller groups; and (3) ensuring a fair distribution based on basic human rights or other prior information. The primary idea in this paper is that fairness biases can be measured using affective coherence, and that this can be used to normalize outcome mappings. We aim for this conceptual work to expose a novel method for handling fairness problems that uses emotional coherence as an independent measure of bias that goes beyond statistical parity.
Dream to Explore: Adaptive Simulations for Autonomous Systems
Oct 27, 2021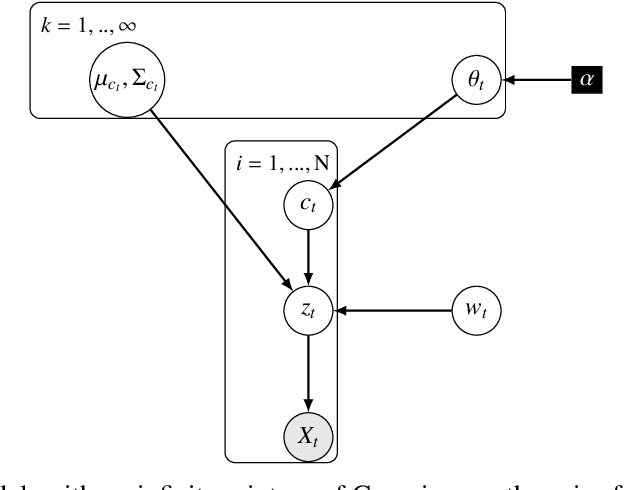
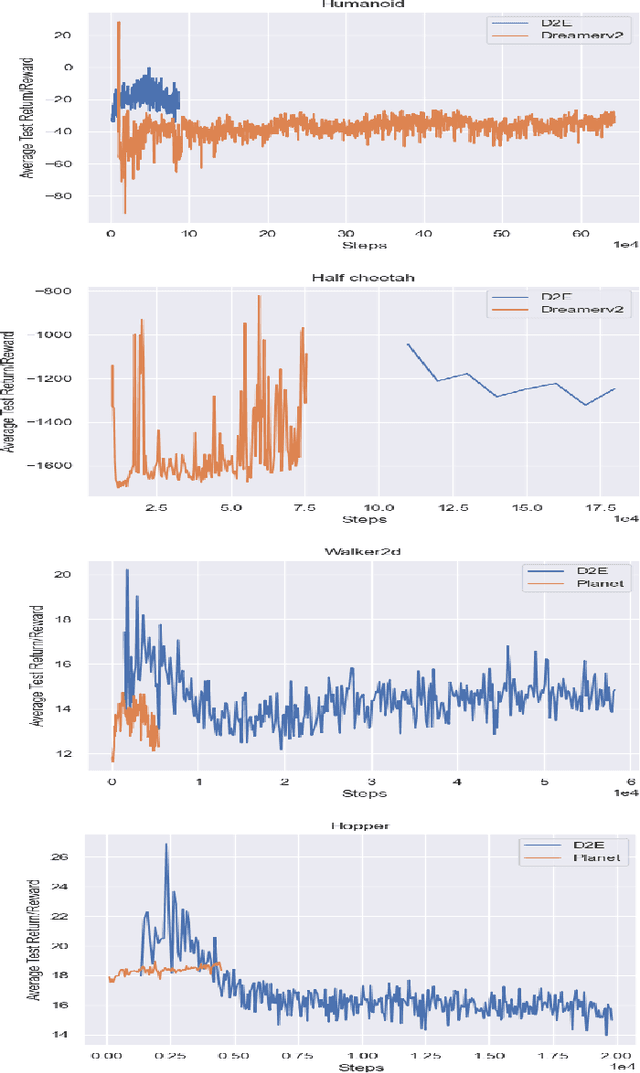
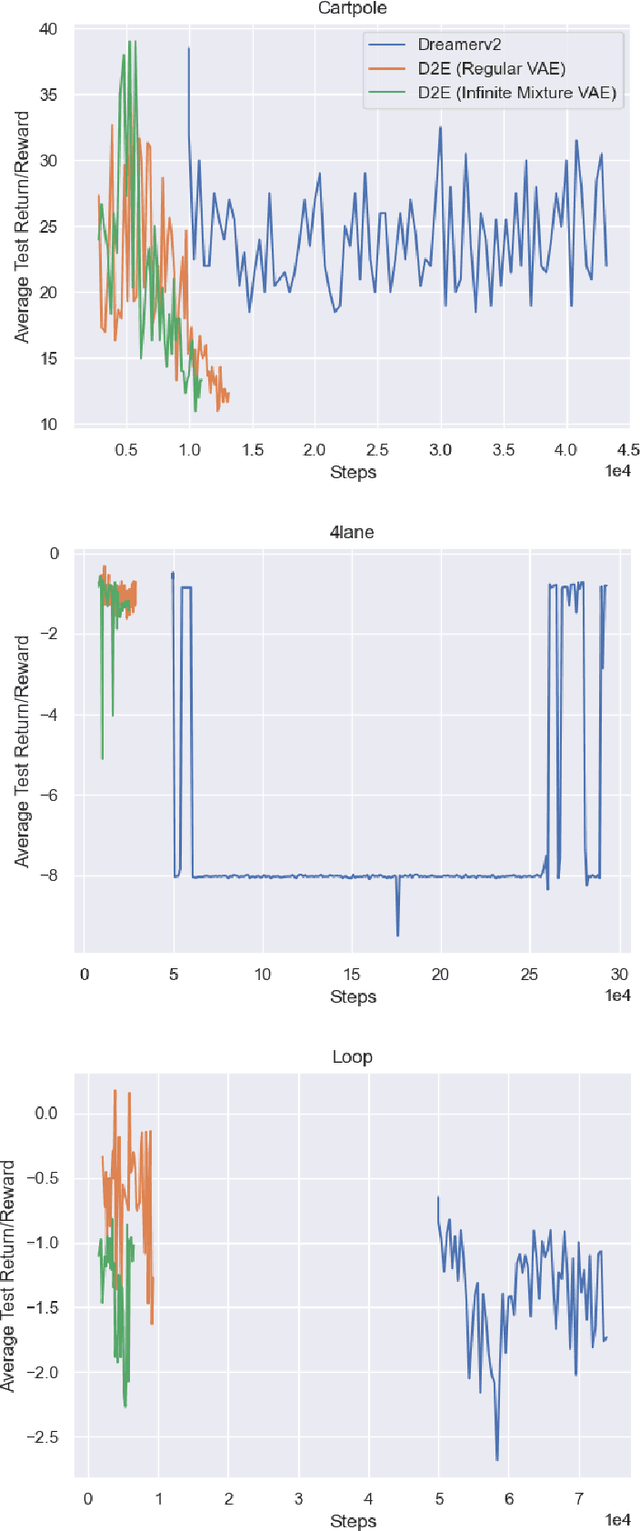
One's ability to learn a generative model of the world without supervision depends on the extent to which one can construct abstract knowledge representations that generalize across experiences. To this end, capturing an accurate statistical structure from observational data provides useful inductive biases that can be transferred to novel environments. Here, we tackle the problem of learning to control dynamical systems by applying Bayesian nonparametric methods, which is applied to solve visual servoing tasks. This is accomplished by first learning a state space representation, then inferring environmental dynamics and improving the policies through imagined future trajectories. Bayesian nonparametric models provide automatic model adaptation, which not only combats underfitting and overfitting, but also allows the model's unbounded dimension to be both flexible and computationally tractable. By employing Gaussian processes to discover latent world dynamics, we mitigate common data efficiency issues observed in reinforcement learning and avoid introducing explicit model bias by describing the system's dynamics. Our algorithm jointly learns a world model and policy by optimizing a variational lower bound of a log-likelihood with respect to the expected free energy minimization objective function. Finally, we compare the performance of our model with the state-of-the-art alternatives for continuous control tasks in simulated environments.
Trust-ya: design of a multiplayer game for the study of small group processes
Sep 09, 2021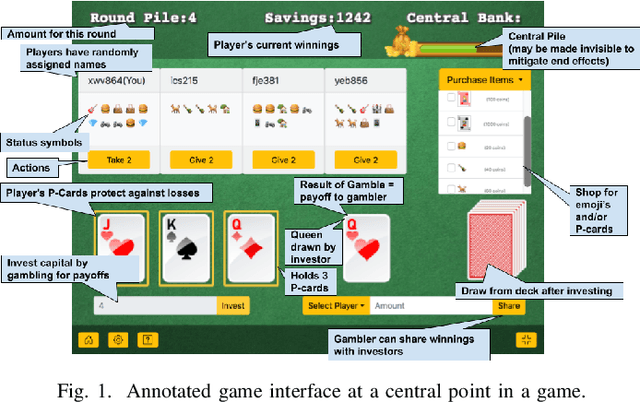
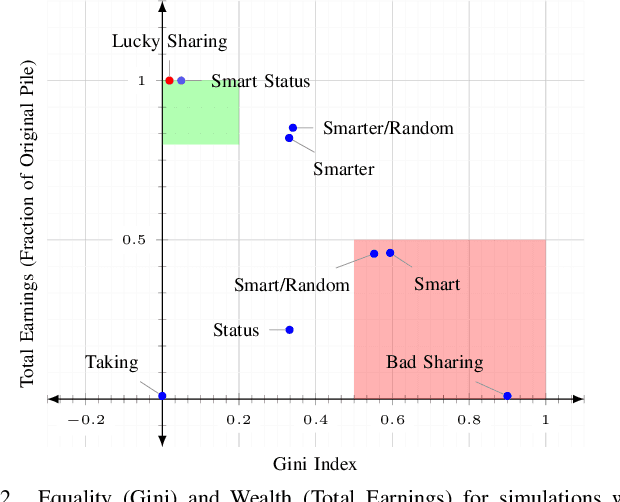
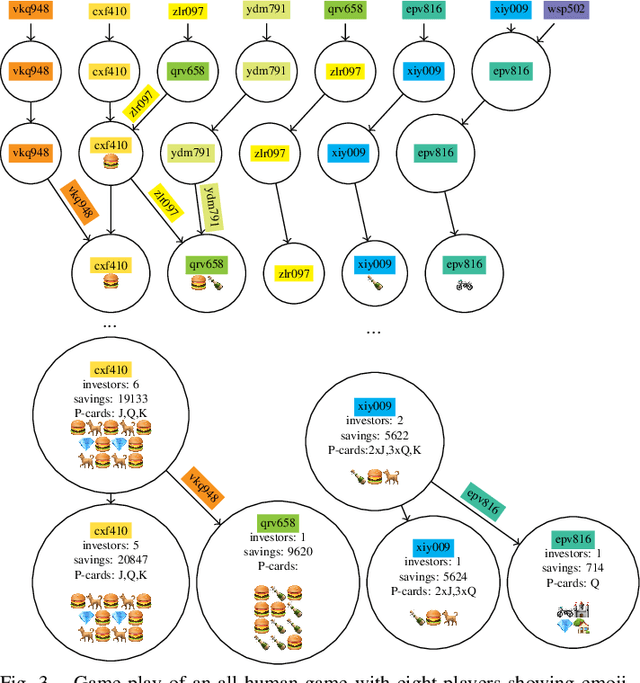
This paper presents the design of a cooperative multi-player betting game, Trust-ya, as a model of some elements of status processes in human groups. The game is designed to elicit status-driven leader-follower behaviours as a means to observe and influence social hierarchy. It involves a Bach/Stravinsky game of deference in a group, in which people on each turn can either invest with another player or hope someone invests with them. Players who receive investment capital are able to gamble for payoffs from a central pool which then can be shared back with those who invested (but a portion of it may be kept, including all of it). The bigger gambles (people with more investors) get bigger payoffs. Thus, there is a natural tendency for players to coalesce as investors around a 'leader' who gambles, but who also shares sufficiently from their winnings to keep the investors 'hanging on'. The 'leader' will want to keep as much as possible for themselves, however. The game is played anonymously, but a set of 'status symbols' can be purchased which have no value in the game itself, but can serve as a 'cheap talk' communication device with other players. This paper introduces the game, relates it to status theory in social psychology, and shows some simple simulated and human experiments that demonstrate how the game can be used to study status processes and dynamics in human groups.
The Human Effect Requires Affect: Addressing Social-Psychological Factors of Climate Change with Machine Learning
Nov 24, 2020Machine learning has the potential to aid in mitigating the human effects of climate change. Previous applications of machine learning to tackle the human effects in climate change include approaches like informing individuals of their carbon footprint and strategies to reduce it. For these methods to be the most effective they must consider relevant social-psychological factors for each individual. Of social-psychological factors at play in climate change, affect has been previously identified as a key element in perceptions and willingness to engage in mitigative behaviours. In this work, we propose an investigation into how affect could be incorporated to enhance machine learning based interventions for climate change. We propose using affective agent-based modelling for climate change as well as the use of a simulated climate change social dilemma to explore the potential benefits of affective machine learning interventions. Behavioural and informational interventions can be a powerful tool in helping humans adopt mitigative behaviours. We expect that utilizing affective ML can make interventions an even more powerful tool and help mitigative behaviours become widely adopted.
Generating Emotionally Aligned Responses in Dialogues using Affect Control Theory
Apr 16, 2020
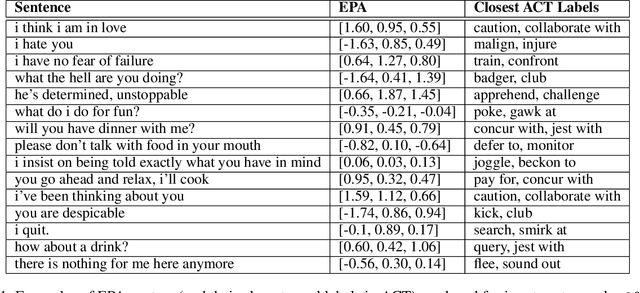
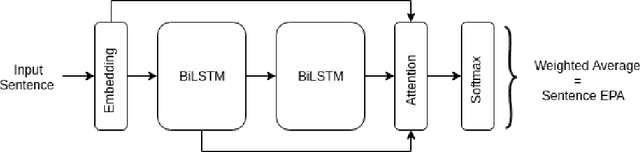

State-of-the-art neural dialogue systems excel at syntactic and semantic modelling of language, but often have a hard time establishing emotional alignment with the human interactant during a conversation. In this work, we bring Affect Control Theory (ACT), a socio-mathematical model of emotions for human-human interactions, to the neural dialogue generation setting. ACT makes predictions about how humans respond to emotional stimuli in social situations. Due to this property, ACT and its derivative probabilistic models have been successfully deployed in several applications of Human-Computer Interaction, including empathetic tutoring systems, assistive healthcare devices and two-person social dilemma games. We investigate how ACT can be used to develop affect-aware neural conversational agents, which produce emotionally aligned responses to prompts and take into consideration the affective identities of the interactants.