 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Efficacy of Semantics-Preserving Transformations in Self-Supervised Learning for Medical Ultrasound
Apr 10, 2025Data augmentation is a central component of joint embedding self-supervised learning (SSL). Approaches that work for natural images may not always be effective in medical imaging tasks. This study systematically investigated the impact of data augmentation and preprocessing strategies in SSL for lung ultrasound. Three data augmentation pipelines were assessed: (1) a baseline pipeline commonly used across imaging domains, (2) a novel semantic-preserving pipeline designed for ultrasound, and (3) a distilled set of the most effective transformations from both pipelines. Pretrained models were evaluated on multiple classification tasks: B-line detection, pleural effusion detection, and COVID-19 classification. Experiments revealed that semantics-preserving data augmentation resulted in the greatest performance for COVID-19 classification - a diagnostic task requiring global image context. Cropping-based methods yielded the greatest performance on the B-line and pleural effusion object classification tasks, which require strong local pattern recognition. Lastly, semantics-preserving ultrasound image preprocessing resulted in increased downstream performance for multiple tasks. Guidance regarding data augmentation and preprocessing strategies was synthesized for practitioners working with SSL in ultrasound.
Intra-video Positive Pairs in Self-Supervised Learning for Ultrasound
Mar 12, 2024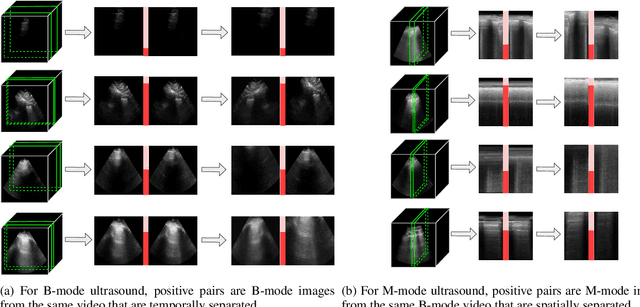
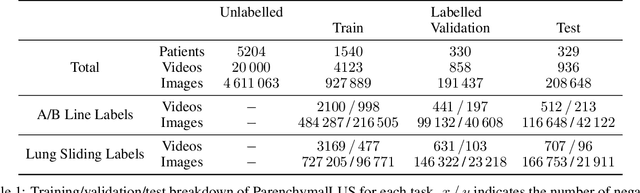
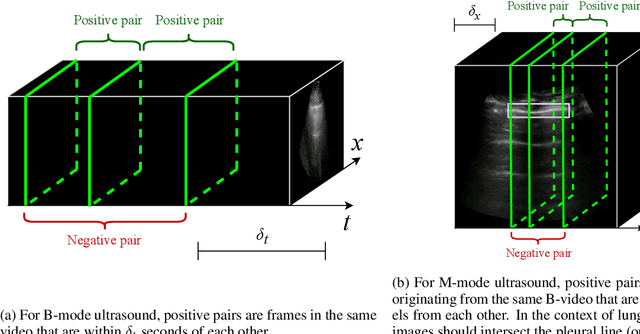
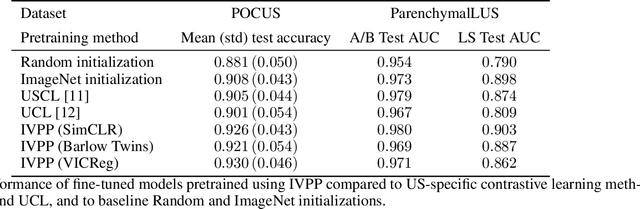
Self-supervised learning (SSL) is one strategy for addressing the paucity of labelled data in medical imaging by learning representations from unlabelled images. Contrastive and non-contrastive SSL methods produce learned representations that are similar for pairs of related images. Such pairs are commonly constructed by randomly distorting the same image twice. The videographic nature of ultrasound offers flexibility for defining the similarity relationship between pairs of images. In this study, we investigated the effect of utilizing proximal, distinct images from the same B-mode ultrasound video as pairs for SSL. Additionally, we introduced a sample weighting scheme that increases the weight of closer image pairs and demonstrated how it can be integrated into SSL objectives. Named Intra-Video Positive Pairs (IVPP), the method surpassed previous ultrasound-specific contrastive learning methods' average test accuracy on COVID-19 classification with the POCUS dataset by $\ge 1.3\%$. Detailed investigations of IVPP's hyperparameters revealed that some combinations of IVPP hyperparameters can lead to improved or worsened performance, depending on the downstream task. Guidelines for practitioners were synthesized based on the results, such as the merit of IVPP with task-specific hyperparameters, and the improved performance of contrastive methods for ultrasound compared to non-contrastive counterparts.
Self-Supervised Pretraining Improves Performance and Inference Efficiency in Multiple Lung Ultrasound Interpretation Tasks
Sep 05, 2023In this study, we investigated whether self-supervised pretraining could produce a neural network feature extractor applicable to multiple classification tasks in B-mode lung ultrasound analysis. When fine-tuning on three lung ultrasound tasks, pretrained models resulted in an improvement of the average across-task area under the receiver operating curve (AUC) by 0.032 and 0.061 on local and external test sets respectively. Compact nonlinear classifiers trained on features outputted by a single pretrained model did not improve performance across all tasks; however, they did reduce inference time by 49% compared to serial execution of separate fine-tuned models. When training using 1% of the available labels, pretrained models consistently outperformed fully supervised models, with a maximum observed test AUC increase of 0.396 for the task of view classification. Overall, the results indicate that self-supervised pretraining is useful for producing initial weights for lung ultrasound classifiers.
A Survey of the Impact of Self-Supervised Pretraining for Diagnostic Tasks with Radiological Images
Sep 05, 2023



Self-supervised pretraining has been observed to be effective at improving feature representations for transfer learning, leveraging large amounts of unlabelled data. This review summarizes recent research into its usage in X-ray, computed tomography, magnetic resonance, and ultrasound imaging, concentrating on studies that compare self-supervised pretraining to fully supervised learning for diagnostic tasks such as classification and segmentation. The most pertinent finding is that self-supervised pretraining generally improves downstream task performance compared to full supervision, most prominently when unlabelled examples greatly outnumber labelled examples. Based on the aggregate evidence, recommendations are provided for practitioners considering using self-supervised learning. Motivated by limitations identified in current research, directions and practices for future study are suggested, such as integrating clinical knowledge with theoretically justified self-supervised learning methods, evaluating on public datasets, growing the modest body of evidence for ultrasound, and characterizing the impact of self-supervised pretraining on generalization.
Exploring the Utility of Self-Supervised Pretraining Strategies for the Detection of Absent Lung Sliding in M-Mode Lung Ultrasound
Apr 05, 2023



Self-supervised pretraining has been observed to improve performance in supervised learning tasks in medical imaging. This study investigates the utility of self-supervised pretraining prior to conducting supervised fine-tuning for the downstream task of lung sliding classification in M-mode lung ultrasound images. We propose a novel pairwise relationship that couples M-mode images constructed from the same B-mode image and investigate the utility of data augmentation procedure specific to M-mode lung ultrasound. The results indicate that self-supervised pretraining yields better performance than full supervision, most notably for feature extractors not initialized with ImageNet-pretrained weights. Moreover, we observe that including a vast volume of unlabelled data results in improved performance on external validation datasets, underscoring the value of self-supervision for improving generalizability in automatic ultrasound interpretation. To the authors' best knowledge, this study is the first to characterize the influence of self-supervised pretraining for M-mode ultrasound.
Dream to Explore: Adaptive Simulations for Autonomous Systems
Oct 27, 2021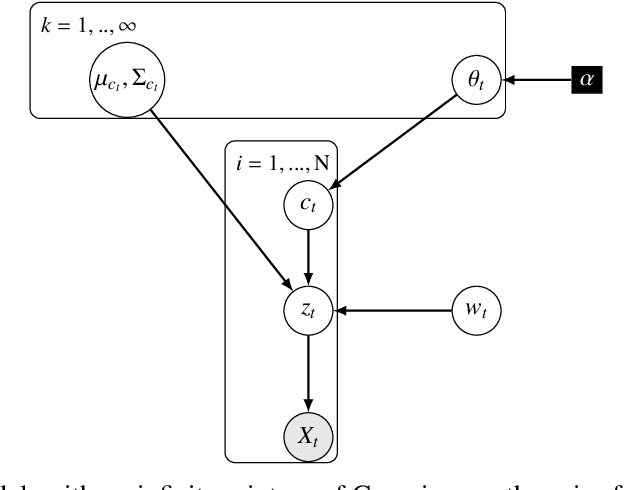
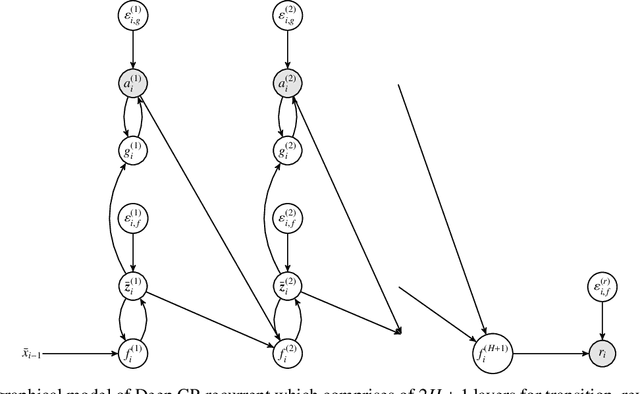
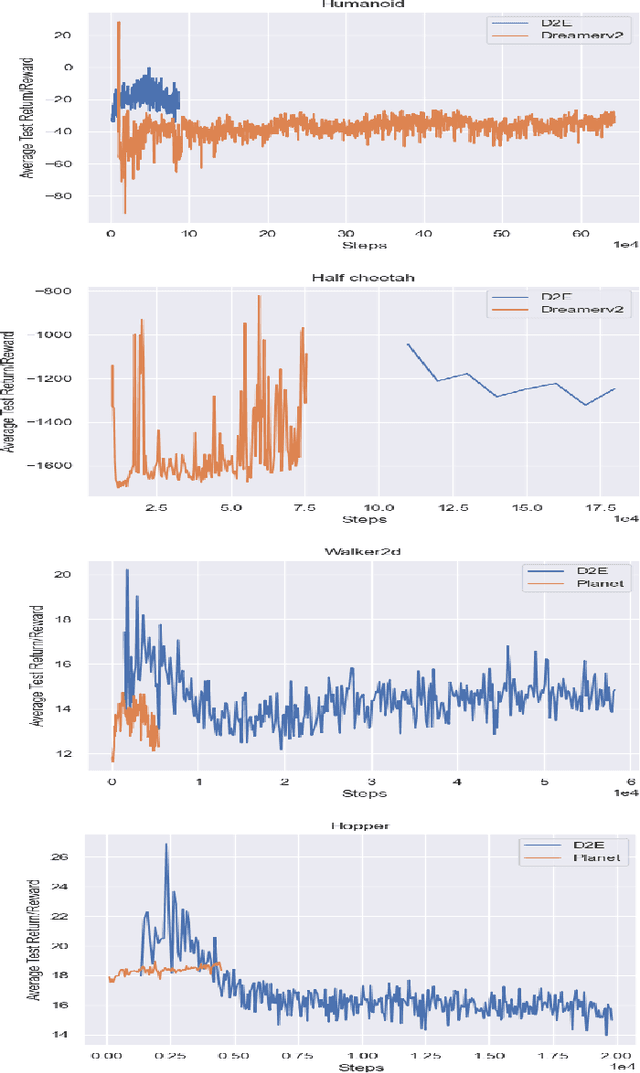
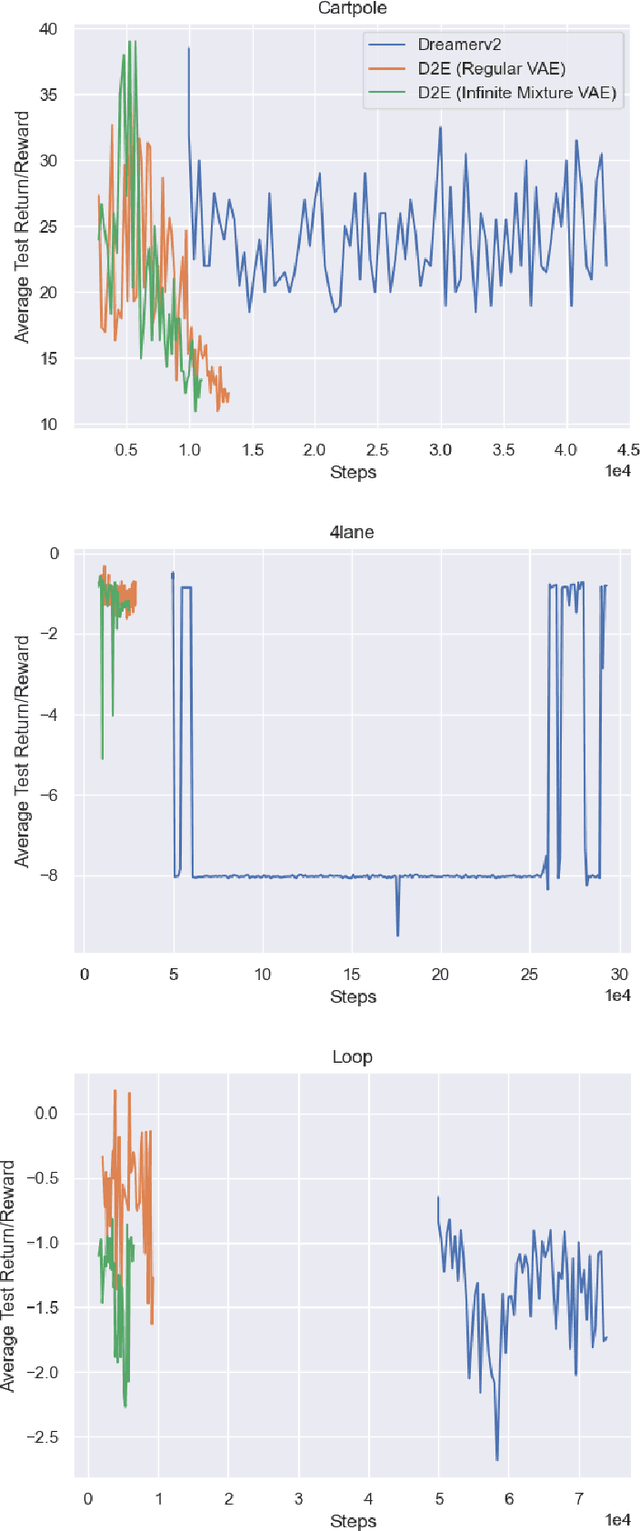
One's ability to learn a generative model of the world without supervision depends on the extent to which one can construct abstract knowledge representations that generalize across experiences. To this end, capturing an accurate statistical structure from observational data provides useful inductive biases that can be transferred to novel environments. Here, we tackle the problem of learning to control dynamical systems by applying Bayesian nonparametric methods, which is applied to solve visual servoing tasks. This is accomplished by first learning a state space representation, then inferring environmental dynamics and improving the policies through imagined future trajectories. Bayesian nonparametric models provide automatic model adaptation, which not only combats underfitting and overfitting, but also allows the model's unbounded dimension to be both flexible and computationally tractable. By employing Gaussian processes to discover latent world dynamics, we mitigate common data efficiency issues observed in reinforcement learning and avoid introducing explicit model bias by describing the system's dynamics. Our algorithm jointly learns a world model and policy by optimizing a variational lower bound of a log-likelihood with respect to the expected free energy minimization objective function. Finally, we compare the performance of our model with the state-of-the-art alternatives for continuous control tasks in simulated environments.
Univariate Long-Term Municipal Water Demand Forecasting
May 18, 2021
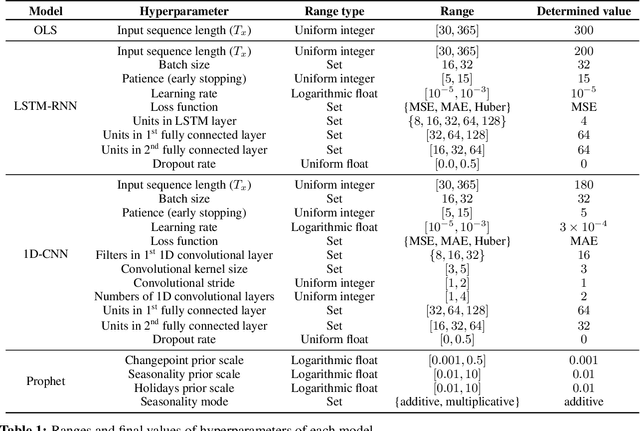
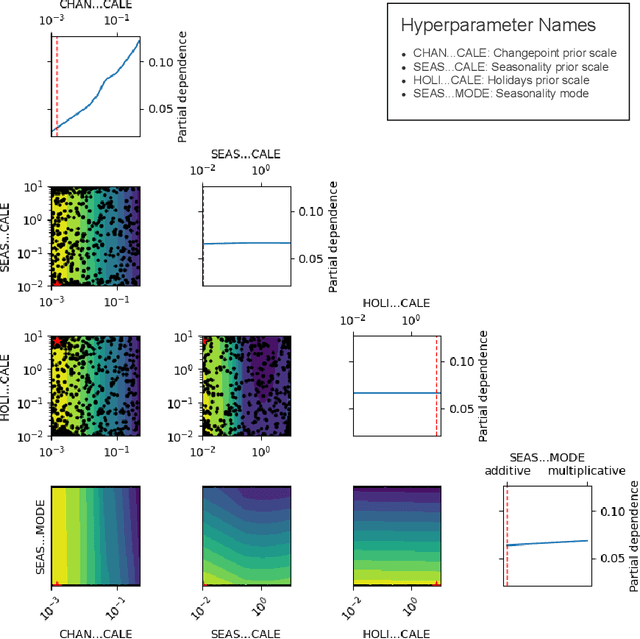
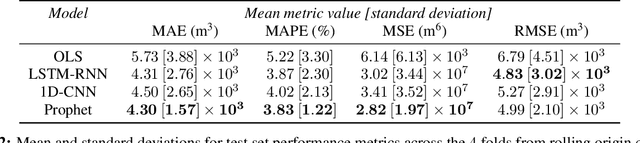
This study describes an investigation into the modelling of citywide water consumption in London, Canada. Multiple modelling techniques were evaluated for the task of univariate time series forecasting with water consumption, including linear regression, Facebook's Prophet method, recurrent neural networks, and convolutional neural networks. Prophet was identified as the model of choice, having achieved a mean absolute percentage error of 2.51%, averaged across a 5-fold cross validation. Prophet was also found to have other advantages deemed valuable to water demand management stakeholders, including inherent interpretability and graceful handling of missing data. The implementation for the methods described in this paper has been open sourced, as they may be adaptable by other municipalities.
Interpretable Machine Learning Approaches to Prediction of Chronic Homelessness
Sep 12, 2020We introduce a machine learning approach to predict chronic homelessness from de-identified client shelter records drawn from a commonly used Canadian homelessness management information system. Using a 30-day time step, a dataset for 6521 individuals was generated. Our model, HIFIS-RNN-MLP, incorporates both static and dynamic features of a client's history to forecast chronic homelessness 6 months into the client's future. The training method was fine-tuned to achieve a high F1-score, giving a desired balance between high recall and precision. Mean recall and precision across 10-fold cross validation were 0.921 and 0.651 respectively. An interpretability method was applied to explain individual predictions and gain insight into the overall factors contributing to chronic homelessness among the population studied. The model achieves state-of-the-art performance and improved stakeholder trust of what is usually a "black box" neural network model through interpretable AI.