 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Efficacy of Semantics-Preserving Transformations in Self-Supervised Learning for Medical Ultrasound
Apr 10, 2025Data augmentation is a central component of joint embedding self-supervised learning (SSL). Approaches that work for natural images may not always be effective in medical imaging tasks. This study systematically investigated the impact of data augmentation and preprocessing strategies in SSL for lung ultrasound. Three data augmentation pipelines were assessed: (1) a baseline pipeline commonly used across imaging domains, (2) a novel semantic-preserving pipeline designed for ultrasound, and (3) a distilled set of the most effective transformations from both pipelines. Pretrained models were evaluated on multiple classification tasks: B-line detection, pleural effusion detection, and COVID-19 classification. Experiments revealed that semantics-preserving data augmentation resulted in the greatest performance for COVID-19 classification - a diagnostic task requiring global image context. Cropping-based methods yielded the greatest performance on the B-line and pleural effusion object classification tasks, which require strong local pattern recognition. Lastly, semantics-preserving ultrasound image preprocessing resulted in increased downstream performance for multiple tasks. Guidance regarding data augmentation and preprocessing strategies was synthesized for practitioners working with SSL in ultrasound.
Intra-video Positive Pairs in Self-Supervised Learning for Ultrasound
Mar 12, 2024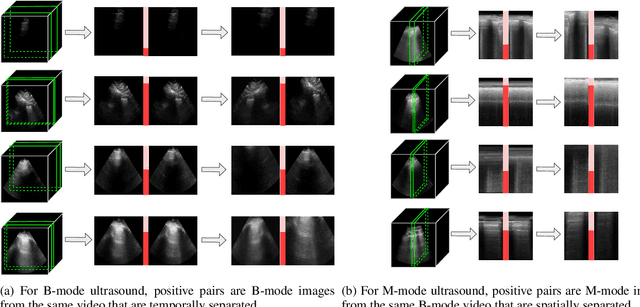
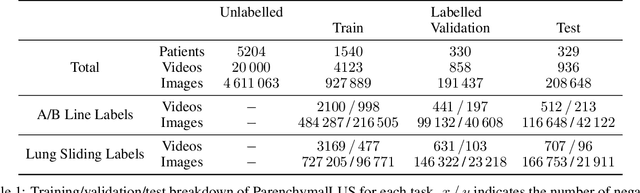
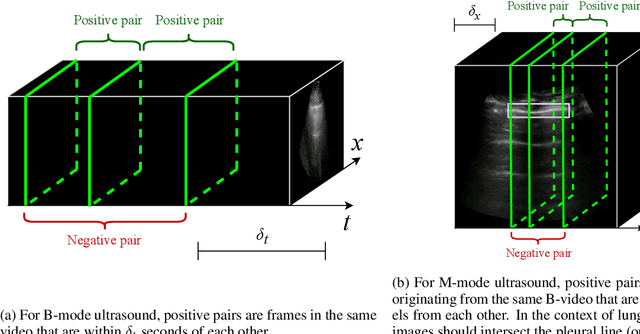
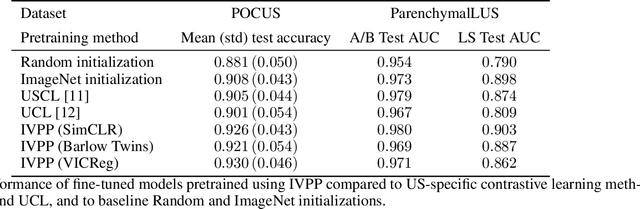
Self-supervised learning (SSL) is one strategy for addressing the paucity of labelled data in medical imaging by learning representations from unlabelled images. Contrastive and non-contrastive SSL methods produce learned representations that are similar for pairs of related images. Such pairs are commonly constructed by randomly distorting the same image twice. The videographic nature of ultrasound offers flexibility for defining the similarity relationship between pairs of images. In this study, we investigated the effect of utilizing proximal, distinct images from the same B-mode ultrasound video as pairs for SSL. Additionally, we introduced a sample weighting scheme that increases the weight of closer image pairs and demonstrated how it can be integrated into SSL objectives. Named Intra-Video Positive Pairs (IVPP), the method surpassed previous ultrasound-specific contrastive learning methods' average test accuracy on COVID-19 classification with the POCUS dataset by $\ge 1.3\%$. Detailed investigations of IVPP's hyperparameters revealed that some combinations of IVPP hyperparameters can lead to improved or worsened performance, depending on the downstream task. Guidelines for practitioners were synthesized based on the results, such as the merit of IVPP with task-specific hyperparameters, and the improved performance of contrastive methods for ultrasound compared to non-contrastive counterparts.
Exploring the Utility of Self-Supervised Pretraining Strategies for the Detection of Absent Lung Sliding in M-Mode Lung Ultrasound
Apr 05, 2023



Self-supervised pretraining has been observed to improve performance in supervised learning tasks in medical imaging. This study investigates the utility of self-supervised pretraining prior to conducting supervised fine-tuning for the downstream task of lung sliding classification in M-mode lung ultrasound images. We propose a novel pairwise relationship that couples M-mode images constructed from the same B-mode image and investigate the utility of data augmentation procedure specific to M-mode lung ultrasound. The results indicate that self-supervised pretraining yields better performance than full supervision, most notably for feature extractors not initialized with ImageNet-pretrained weights. Moreover, we observe that including a vast volume of unlabelled data results in improved performance on external validation datasets, underscoring the value of self-supervision for improving generalizability in automatic ultrasound interpretation. To the authors' best knowledge, this study is the first to characterize the influence of self-supervised pretraining for M-mode ultrasound.